Ideas
-
无服务器计算中的两个缺失链条:有状态计算和放置位置控制
由于无服务器计算的易编程性和易管理,近年来它得到了迅速的普及。许多人将其视为云服的下一个通用计算平台[4]。 但是,虽然...
-
用于机器学习开发和模型治理的专用工具日益变得重要
几年前我们开始发布文章(参见本文末尾的“相关资源”),了解数据团队开始接受更多机器学习(ML)项目时所面临的挑战。 在此过...
-
Ray编程:给新用户的小指南
Ray是一个用于在计算集群上编程的通用框架。 Ray使开发人员能够轻松地并行化他们的Python应用程序,构建新的应用,在任意大小...
-
使用Apache Kafka和Apache Pulsar创建任务队列
使用Kafka和Pulsar的一个常见用例是创建任务队列。这两种技术为实现此用例提供了不同的实现。我将讨论用Kafka和Pulsar实现任...
-
为什么数据科学家不是数据工程师
“一位科学家可以发现一颗新星,但他不能制造一颗。他必须要求工程师为他做这件事。” -Gordon Lindsay Glegg, 设计中的设计...
-
机器学习模型脆弱性和安全性的提议
和许多人一样,我已经知道机器学习模型本身可能会带来安全风险。最近大量的博文和论文概述了这一内容广泛的主题,列举出了攻...
-
医疗领域构建自然语言处理系统的经验教训
我们正处于自然语言处理(NLP)领域令人兴奋的十年。 在阅读理解、语言翻译和创意写作等复杂任务上,计算机的表现将会和人类...
-
处理企业中的实时数据操作
在Strata 2017我首次提出了一个新图表,帮助团队了解团队失败的原因以及何时失败: 在项目早期,管理层和开发人员对项目成功...
-
机器学习中的深度自动化
在之前的一篇文章中我们讨论了机器学习(ML)在软件开发中的应用,其中包括数据科学中的采样工具和管理数据基础架构。 从那时...
-
管理机器学习中的风险
在这篇文章中我分享了去年9月我在纽约Strata数据会议上所发表主题演讲幻灯片和笔记。 随着数据社区开始部署更多机器学习(ML...
-
数据隐私和机器学习时代下的数据收集和数据市场
在这篇文章中我分享5月底我在伦敦Strata数据会议上演讲中使用的幻灯片和笔记。 我的目标是提醒数据社区,数据本身中存在着许...
-
检验机器学习可解释性的技巧
解释机器学习模型是目前数据科学界一个相当热门的话题。 机器学习模型需要可被解释,以便先进的预测建模技术被更广泛地采纳,...
-
数据工程师vs数据科学家
了解数据工程师和数据科学家之间的差异非常重要。 误解或不了解其差异,会导致团队在处理大数据时失败或者表现不及预期。 一...
-
数据隐私变得越发关键的时代如何搭建数据分析产品
在这篇文章中,我分享了在2018年3月进行的加利福尼亚州Strata数据会议上所发表演讲,提供了和“公司如何在数据隐私变得关键的...
-
从将机器学习模型转化成真正产品和服务中学到的经验教训
人工智能依然处于它的幼年时期。今天,只有15%的企业在使用机器学习,但是有30%的企业已经在它们未来的发展路线图里包括了机...
-
用Skater来解读预测性模型:解密模型的隐秘
在过去多年里机器学习(ML)走过了很长的路。它从纯学术领域的一个实验性研究课题,发展成为真实世界里的问题的一个自动化解...
-
比较两个生产级NLP库:准确性、性能和可扩展性
这是本系列博客的第三篇,也是最后一篇。这个系列之前的博客比较了两个主要的开源自然语言处理软件库:John Snow Labs的Apach...
-
比较两个生产级NLP库:运行Spark-NLP和spaCy的管道
在本博客系列的第一篇中我介绍了两个自然语言处理库(John Snow Labs的Apache Spark NLP和Explosion AI的spaCy),并用它们训...
-
比较两个生产级NLP库:训练Spark-NLP和spaCy的管道
本系列博客的目地是通过使用两个领先的生产级语言处理库(John Snow Labs的Apache Spark NLP和Explosion AI的spaCy)来处理真...
-
构建AI平台的关键考虑点
AI的希望是很大的,但是真正要在企业内部构建和实现AI确很有挑战性。随着越来越多的企业学着在正式的生产环境里构建智能的产...
-
企业如何在机器学习时代前行
在过去的几年间,数据社区已经在关注收集和整理数据,为此目的构建基础设施,并使用数据来改善决策制定。现在我们看到,在很...
-
应用数据科学的现状
现在已经进入2017年的下半年,是时候来看看对使用数据科学和机器学习(ML)有兴趣的企业所面临的常见挑战了。让我们假定你的...
-
什么是机器学习工程师?
我们已经谈论数据科学和数据科学家有10年了。虽然对“数据科学家”的含义总是存在一些争议,但是我们看到了许多大学、在线学院...
-
科学领域中的深度学习一览
深度学习在很多商业应用中取得了前所未有的成功。大约十年以前,很少有从业者可以预测到深度学习驱动的系统可以在计算机视觉...
-
关于如何解释机器学习的一些方法
到现在你可能听说过种种奇闻轶事,比如机器学习算法通过利用大数据能够预测某位慈善家是否会捐款给基金会啦,预测一个在新生...
-
学习数据科学并没有什么神秘之处
有些人可以想出用数据来提升企业业务的方法。这些人可以解释这些方法并使之变为现实,从而影响他们机构的变革。尽管他们的工...
-
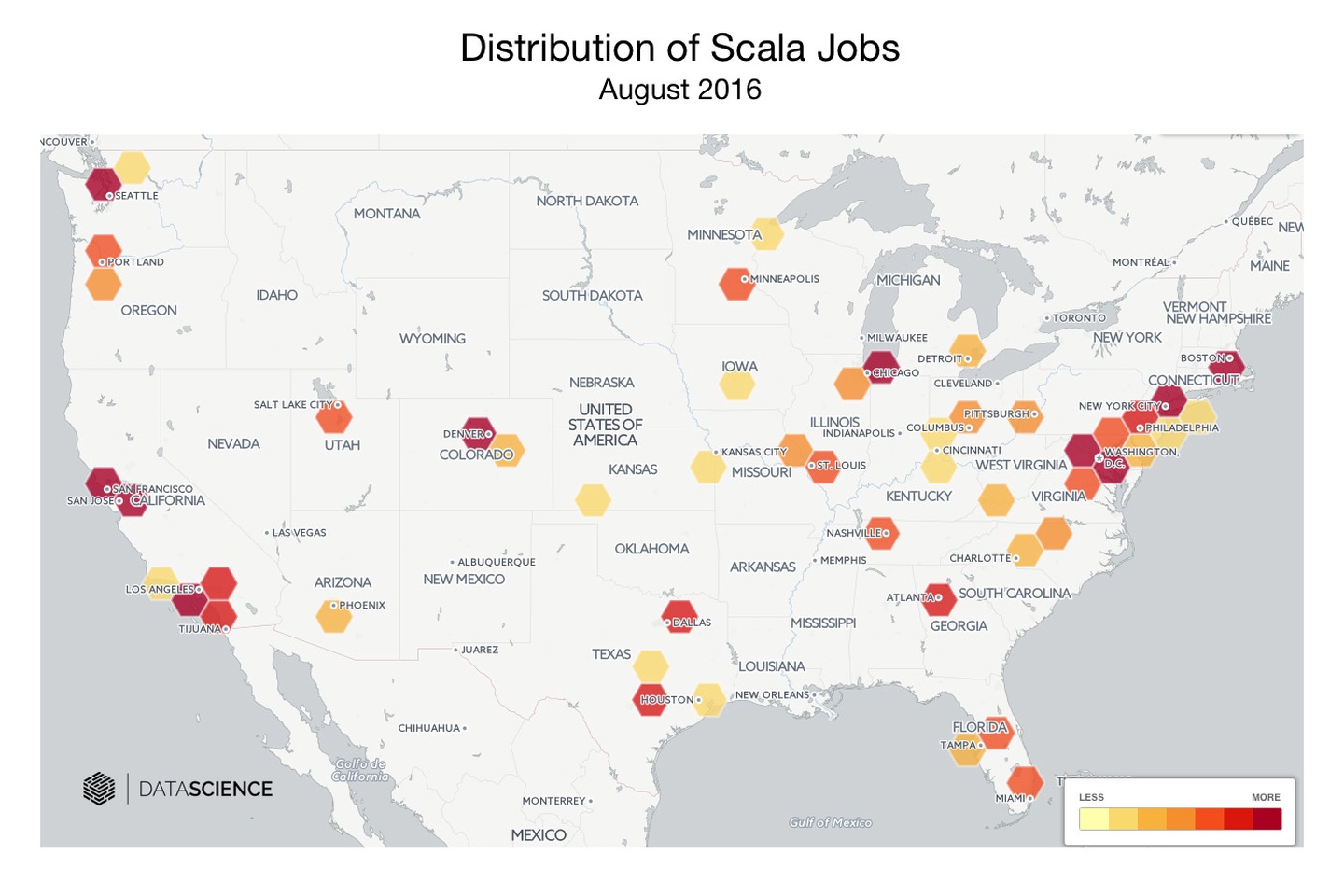
评估Scala
今年早些时候我要组建立一个数据工程团队,因而必须选择一种编程语言。Scala看上去像是一个不错的选择(我们打算经常与Spark...
-
让科学重回数据科学
科学(比如物理、化学等)的主要原则(或者至少是科学的理想原则)之一是:可重复性。只有结果能被清楚地再现并经过严格的同...
-
把深度学习用于你已有的数据
在过去的几年里,深度学习取得了显著的进步。尽管企业的经理们已经意识到了学术界里正在发生的事情,但我们依然处于将研究引...
-
深度学习的难点
深度学习的核心问题就是一个非常难的优化问题。所以在神经网络引入后的几十年间,深度神经网络的优化问题的困难性是阻碍它们...
-
2017年安全数据科学领域的4个趋势
安全数据科学正在蓬勃发展,有报告显示安全分析市场将在2023年达到八十亿美元的价值, 26%的增长率。这要感谢不屈不挠的网络...
-
增强学习的解释
一个机器人向前迈了一大步然后跌倒了。下一次它就往前走一小步并可以保持平衡了。机器人就像这样尝试了很多次,最终它成功学...
-
什么是实践中真正在用的数据科学系统?
在过去的几年间,数据科学这个概念已经被非常多的行业所接受。数据科学(源自于一个科学研究课题)最早是来自于一些试图去理...
-
局部可理解的与模型无关的解释(LIME)技术介绍
机器学习是近来许多科学和技术进步的核心。随着计算机在诸如围棋比赛中战胜人类专业选手等案例里所展现出的进步,许多人开始...
-
三个值得添加到您的数据科学工具包中的想法
我总是在关注和寻找可以改进我如何解决数据分析项目的好想法。尤其喜欢可以转化为我可以重复使用的工具的那些方法。大部分时...
-
人机协作是如何自动化分类数据
人工智能的倡导者与以人为中心的方法的支持者之间的争论其实是一个错误的二分法。机器当然可以帮助人们解决面对的问题,但是...
-
欧洲核子研究组织如何预测新的流行数据集
去年夏天,我曾在日内瓦的欧洲核子研究组织(CERN)暑期开放实验室实习。我工作的重点是为CERN的大数据分析来探索Apache Spar...
-
工作职位推荐系统的算法与架构
Indeed.com 每个月有两亿不同的访客,有每天处理数亿次请求的推荐引擎。在这篇文章里,我们将描述我们的推荐引擎是如何演化的...
-
日志和实时流计算处理
到目前为止,我还仅仅只是描述了一些把数据从一个地方拷贝到其他地方的多种的方法。然而,在存储系统间挪动字节并不是故事的...
-
数据对于制造业的国际化影响
机器学习与制造业 人工智能在全球已经有数十年的发展历史,并且人们在深度学习领域也看到了巨大的进步(如IBM的Deep Blue和Go...
-
认知应用:大数据的下个转折点
在我的之前的一些博客中,我提到了生成认知的必要性和重要性,并提供了一个认知应用的例子。我始终认为认知应用是对于希望通...
-
智能数据平台推进智慧城市
根据联合国2014年的报告,全球54%的人口居住在城市,而未来的城市化进程则会进一步将这个数字在2050年提升到66%。这个人口城...
-
凌驾于算法之上:搜索体验的优化
我们生活在算法的黄金年代。尽管我们拥有搜索引擎、语音识别以及计算机视觉系统等技术长达数十年,但也只是在最近几年中它们...
-
巨大的科学难题需要大数据解决方案
在劳伦斯伯克利国家实验室的超级计算中心,我领导国家能源研究科学计算中心(NERSC)的数据和分析小组。在这个角色上,我追踪...
-
什么是数据科学?
我们已经听到这个观点:据哈尔•瓦里安(Hal Varian)说,统计学家是下一个性感的工作。五年前,在《什么是Web 2.0》里蒂姆•奥...