Ideas
-
MLflow:一种机器学习生命周期管理平台
尽管机器学习(ML)可以产生出色的结果,在实践中使用它仍然是很复杂的。 除了软件研发中的常见挑战外,机器学习开发人员还面...
-
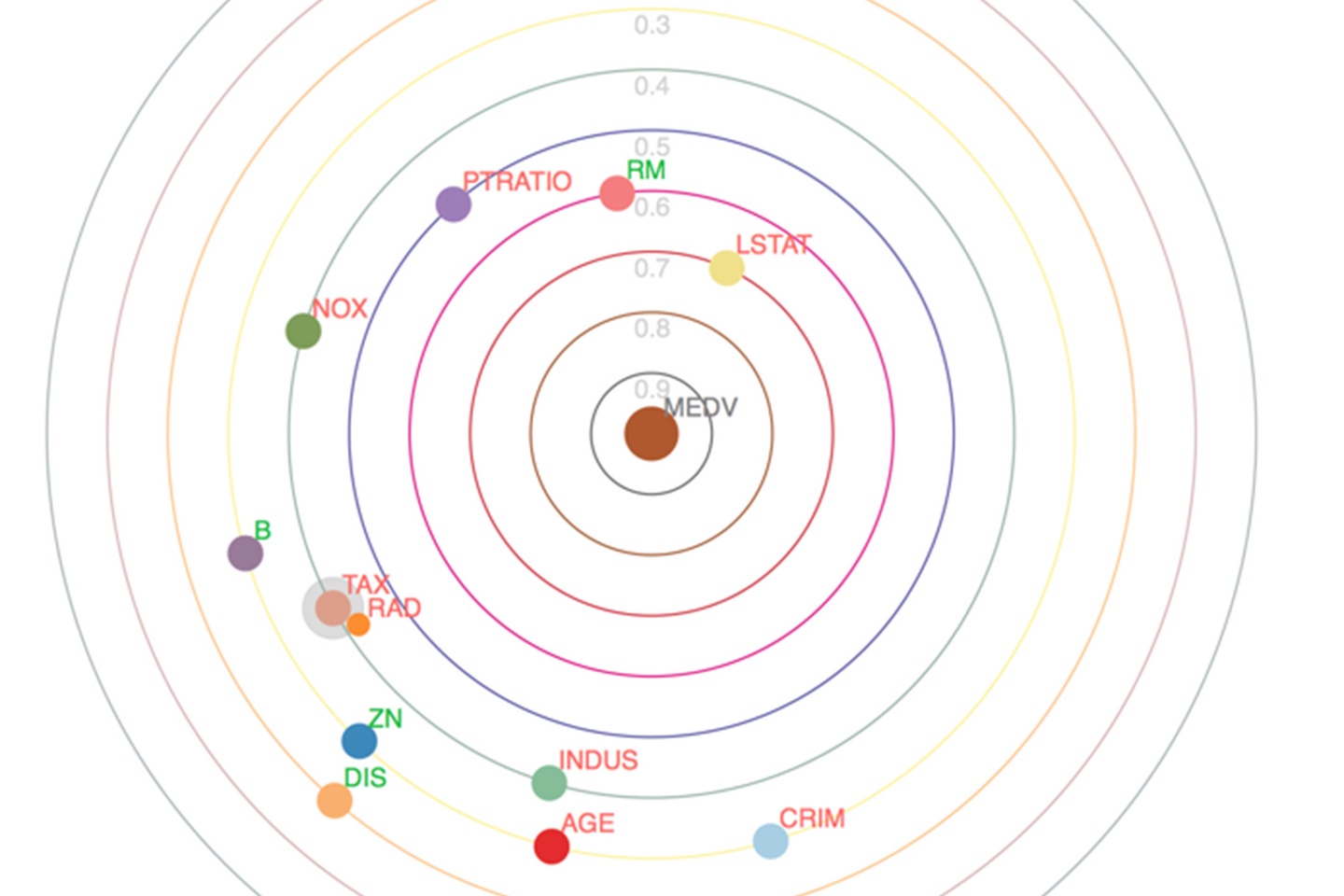
一个优雅地探索相关性的新可视化方法
一个古老的诅咒一直萦绕着数据分析:我们用来改进模型的变量越多,那么我们需要的数据就会出现指数级的增长。不过,我们通过...
-
扩展Spark ML来构建你自己的模型和变换器类型
尽管Spark ML管道提供了各种各样的算法,你仍可能想要额外的功能,并且不脱离管道模型。在Spark Mllib中,这算不上什么问题,...
-
为大数据带来交互式的BI
基于Hadoop的SQL一直在被持续地改进,但是一个查询要等几分钟到几小时还是非常得正常。在这篇博文里,我们将会介绍开源的分布...
-
Elasticsearch 5.0和ELK/Elastic Stack指南
这篇文章是一步一步的使用指南,介绍了如何结合使用Elasticsearch和其他ELK技术栈(现在叫Elastic Stack)来发送、解析、存储...
-
用深度学习来获取文本语义
词向量是一种把词处理成向量的技术,并且保证向量间的相对相似度和语义相似度是相关的。这个技术是在无监督学习方面最成功的...
-
为Spark ML扩展结构化流计算
Spark的新的ALPHA结构化流计算API已经引起了广泛的兴趣。因为它把Dataset、DataFrame和SQL的API都引入了流计算上下文。然而在...
-
从图像识别到物体识别
在增强现实(AR)与自动驾驶的时代来临之际,3D数据呈现爆炸式增长。在不久的将来,处理3D数据的算法将应用于像机器人自动巡...
-
优步在Hadoop上做增量处理的案例
优步的任务是提供“对每个人来说,在任何地方都可以获得像自来水一样可靠的出行服务”。为了履行这一承诺,优步依赖于在每个层...
-
用Spark 和DBSCAN对地理定位数据进行聚类
机器学习,特别是聚类算法,可以用来确定哪些地理区域经常被一个用户访问和签到而哪些区域不是。这样的地理分析使多种服务成...