今年早些时候我要组建立一个数据工程团队,因而必须选择一种编程语言。Scala看上去像是一个不错的选择(我们打算经常与Spark打交道),但是有几点让我不得不停下脚步。我阅读了很多与这个主题相关的意见,但没有太多的收获。我看到的东西要么是有明显的偏见,要么是5年之前的,要么两者都是。我写这篇文章是希望它能帮助到其他身处同样位置的人,来明晰和评估Scala对于数据科学和工程团队的价值。
在这篇文章中我将会从数据和人两方面来探讨Scala生态系统中的几个核心组件的现状。我从GitHub上抓取了相应的时间序列数据来帮助进行分析,并试图解决我可以遇见的一些常见问题。我也咨询了几个Scala社区的领导者的意见,包括Martin Odersky。他们都非常乐意花时间来分享他们的观点。
我尝试着公平地阐述和分析,但是我应该发表一个免责声明,那就是这篇概述是从我个人角度出发写的。我并没有给Scala以及其生态系统提供任何可引用的开源贡献。我之前主要是用Haskell写代码。我已经在DataScience公司(一家位于洛杉矶的提供数据科学平台的公司)成功招募并培训了一支完全使用Scala编程的6人团队。
专有的Java和SMACK技术栈的兴起
Scala十分依赖Java生态系统。过去一年中可能是最重要的一个与Java相关的事件就是Oracle针对Google的诉讼。Java生态系统和整个工业界一直期待许可证只是在创建一个兼容的API的实现时才被需要。尽管Google在公平使用原则上胜诉,但是由于联邦巡回法庭在API版权上的判决,核心问题还是没有解决。
Java更大的问题是Oracle的专有性所带来的语言的束缚以及相关管理维护工作的缺乏。在过去的十年中,Java演进的很缓慢。Java 6和Java 7之间花了长达五年的时间,以至于甚至出现了一份写给Larry Ellison(译者注:Oracle的CEO)的请愿书,希望可以“将Java EE作为全球IT工业界的核心部分推进”。这些问题导致Java语言开始失去市场,在某些应用领域的用户开始转向诸如Scala的开源语言。根据Indeed.com收集的数据,从2012年至2016年,Scala职位发布的增长超过500%以上,而同期Java的职位需求量下降了33%。
这种趋势的早期信号比较明显地表现在分布式数据处理领域,主要是SMACK (Spark, Mesos, Akka, Cassandra, Kafka)技术栈的崛起,而这些技术和工具都是由Scala编写的。Scala是在正确的时间出现的正确的语言,用它编写的Spark正在帮助Scala的推广。在语法上来说,Spark与Scala的集合API几乎是相同的,用起来就像是一个力量倍增器。
除了Scala之外,以数据为中心的应用和组合的并发原语与日俱增的重要性驱动了对于函数式编程语言的广泛兴趣,诸如 Clojure、Erlang和Haskell。
流计算、微服务和Scala
在流式数据和微服务的广泛应用中,Scala的重要性是显而易见的。Lightbend最近针对2151名全球基于JVM的开发人员的调查显示,在生产系统中使用微服务的Scala开发人员比Java开发人员多了50%。在生产系统中使用微服务的所有开发人员中,35%使用了Akka Streams,30%使用Kafka,19%使用Spark Streaming。
我通过从对应的GitHub仓库抓取每日的时间序列数据比较了Akka、Kafka和Spark。我分别观察了3个数据:新关注总数、拉取请求数和提交数。在每种场景下,数据都是3年的跨度,从2013年9月30日至2016年9月30日。为了可读性,时间序列进行了以2周为单位的移动平均处理。本文是通过谷歌的BigQuery SQL接口在开源GitHub档案库中查询的。文中涉及的所有查询的源代码都可以在这里找到。
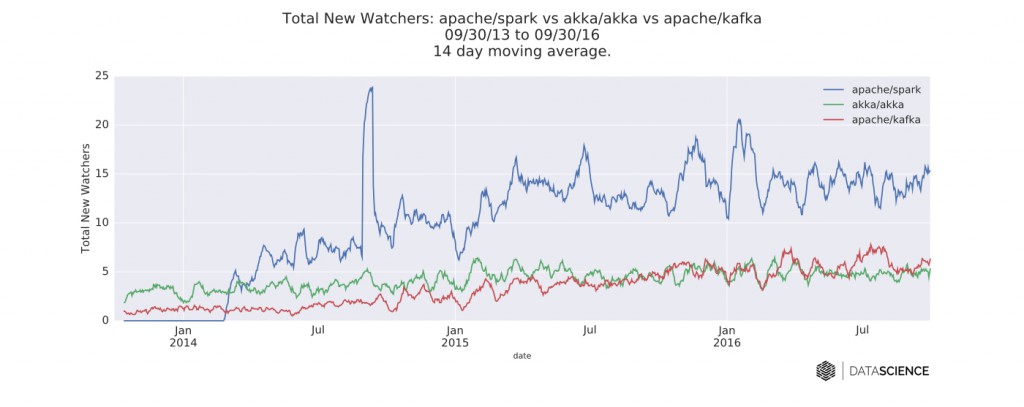
图一 Spark、Akka和Kafka的GitHub库每天的新关注数的时间序列数据。为了可读性,数据都进行了以14天为单位的移动平均处理。图片由DataScience.com授权使用
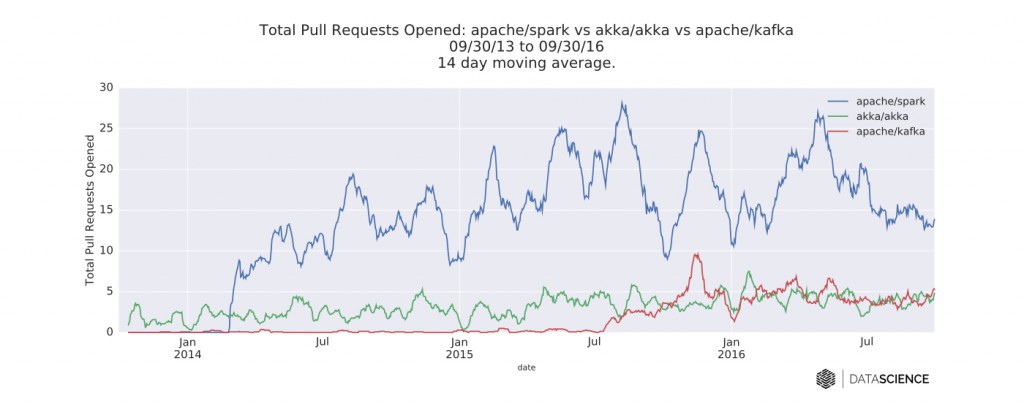
图二 Spark、Akka和Kafka的GitHub库每天新增的拉取请求数的时间序列数据。图片由DataScience.com授权使用
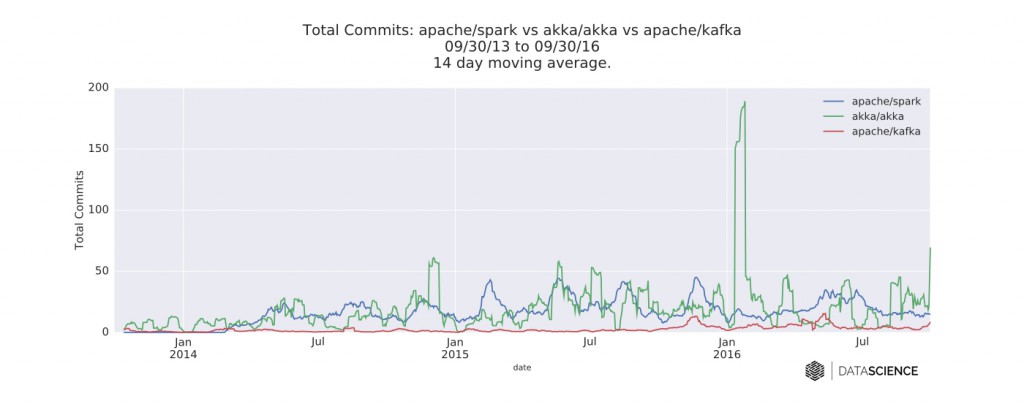
图三 Spark,、Akka和Kafka的GitHub库每天新增的提交数的时间序列数据。图片由DataScience.com授权使用
Spark和Kafka的发展
Spark毫无疑问在关注人数和PR(拉取请求)数上是最为活跃的。这一点也不意外,它仍然是数据社区中最活跃的开源项目。从2015到2016年,其代码库的贡献人数增长了67%。Scala继续是Spark相关开发的首选语言,紧随其后的是Python。
Kafka在PR数上快要追上Akka了。另外值得一提的是,随着Confluent接管了Kafka的维护工作,一些开发转向了Java。Kafka专注于用流式数据处理作为批处理ETL系统的替代品。
此外,Kafak让你可以建立一个分布式系统,提供一次且仅有一次的提交保证。并且,你可以发送强类型的二进制数据(例如Avro格式)。如果你使用Scala这样的强类型语言,你可以保留类型系统给予的所有保障。这与处理JSON时你需要把所有东西都重新解析一遍形成鲜明对比。(消费和产生JSON数据是批处理ETL系统中现成工具的主要用途。)
似乎许多Kafka的新使用者是像DataScience这样的创业公司。一般把它作为一个可扩展的微服务的管道。Jay Kreps 在今年早些时的一篇博客中解释说,Confluent的想法也与此差不多。
分析中其他一些有趣的点:
- 每天新增的PR数量和发布日期的剩余时间相关联。
- 2016年1月Akka的提交数到达一个极高的值(总共有2008次提交)。这看上去像是一次大扫除:维护人员合并了许多Akka Streams和HTTP组件的提交到了一个主分支中。
这当然不是一个面面俱到的比较。这三个库都是多面手。特别是Spark,它是一个多功能的框架。除了流计算之外, Spark还包含了一个基于内存的分布式计算引擎、DataFrame、图计算和机器学习库。
Dotty——一个新的工业标准?
Martin Odersky一直在领头推进Dotty的发展。Dotty是一个新的基于依赖对象类型(DOT)运算(基本上是个简化版的Scala)和来自于函数式编程(FP)数据库社区的想法开发的研究用编译器。
Dotty开发的团队协作显示了基于目前技术的可观的改进,特别是在编译时间方面。我问Odersky关于Dotty架构的创新点和可以帮助终端用户的地方,他是这么回答的:
我想到的有两点:首先,这跟之前的基础非常相关,使我们在如何设计一个健全的类型系统方面有更好的指导方向。这也使得用户遇到更少的意外和困难。其次,它有一个本质上是函数式的架构。这使得它可以更容易地被扩展、更容易地正确完成,使得该编译器被当作一个服务提供给IDE和元编程时,其API更加健壮。
尽管Dotty带来了出现一些有趣的编程语言的可能性(尤其是完全依赖类型,诸如Agda和Idris),Odersky已经选择优先考虑使这些语言立即对社区做出贡献。这些语言之间的差别是很小的,大部分是为了简化语言(比如移除过程语法)或是修复问题(不健全的模式匹配),或两者都有(早期的发起者)。
有趣的是,Odersky其实有长时间构建编译器的经验。在博士毕业之前,他出售了一个Pascal编译器给Borland公司。他师从Niklaus Wirth(Pascal语言的创立者)完成了博士学业,随后在IBM进行一些博士后的工作(E语言,后来被商用),并发现了一些函数式编程的缺陷。随后他继续编写Pizza(和以Haskell和Java泛型闻名的Philip Wadler一起合作)和Funnel语言,不过没有人用这些,但是他和Wadler的工作产生了GJ编译器,当然也带来了Java泛型。他也编写过多个Scala编译器(Dotty是第五或者第六个)。我有可能有地方没提到,但是我想说的是他是十分值得信赖的。
当然,我还是想问他全依赖类型是否有可能在某一时候在Scala中终结,他是这么回答的:
永远不要否定可能性 :-)。事实上,我们正在和Viktor Kuncak一起将Leon程序与Scala整合起来,这需要比现在更加丰富的依赖类型。但是目前这仅仅是研究,其结果是完全不定的。
Scala和Dotty团队正在非常紧密地合作,来把Scala2.x和Dotty整合。并且表示他们非常注重其连续性。Scala 2.12 和 2.13有个语言标记可以解锁藏在Dotty中的特性(例如,存在性类型),并且Dotty编译器有一个Scala 2的兼容模式。甚至还有一个迁移工具的存在。
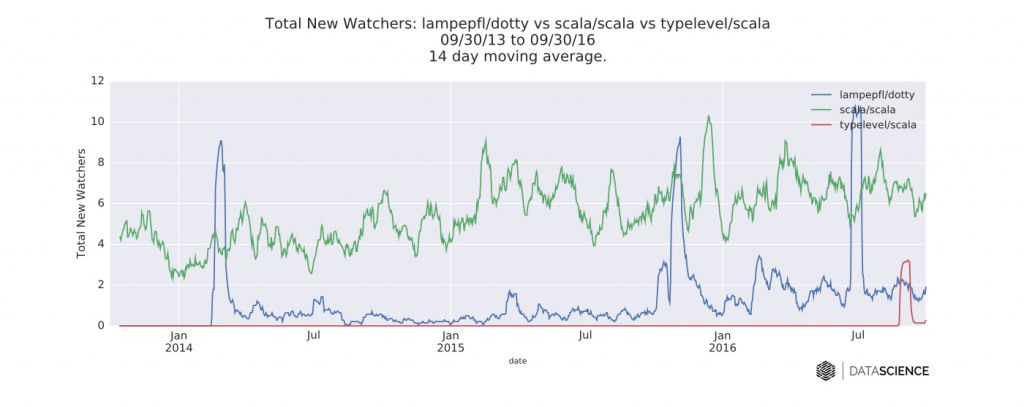
图四 每个编译器的GitHub库每日的新关注数的时间序列数据。图片由DataScience.com授权使用
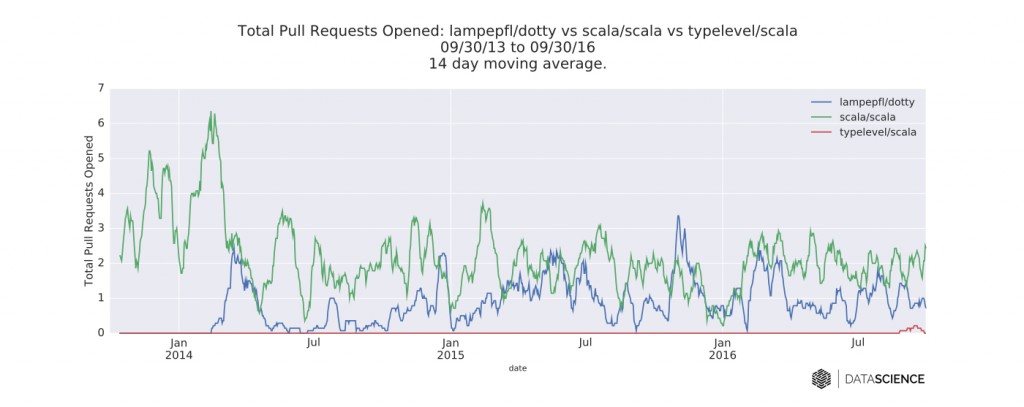
图五 每个编译器的GitHub库每日的新PR数的时间序列数据。图片由DataScience.com授权使用
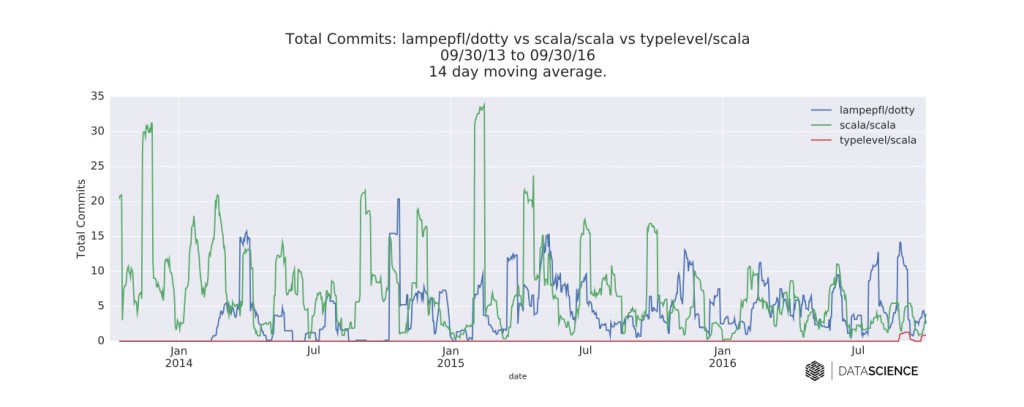
图六 每个编译器的GitHub库每日的提交数的时间序列数据。图片由DataScience.com授权使用
我比较了这两个编辑器(和Typelevel一起),分析了它们对应的GitHub库的时间序列数据。总的来说,新的关注(很可能是来自于Dotty公告和黑客资讯)可能是这些数据中最有意思的。
Lightbend是由Odersky、前扑克冠军以及软件工程师Paul Phillips和Akka创始人Jonas Bonér创立的一家支持Scala和PLAY响应式JVM框架的公司。该公司一开始叫做“Typesafe”,以此来表明它函数式编程的根源所在,在2016年2月才改名为“Lightbend”。我和Lightbend的CEO Mark Brewer聊了聊他们在Scala上的工作,他是这么说的:
Scala 2.12已经是Lightbend以及许多其他贡献者的一项重要的投资。它的后端利用Java 8的特性被完全重写(以至于在编译到Java字节码时不需要从Scala翻译到Java)。此外2.12引入了一个新的优化器,进行更加深层的静态分析从而消除函数式编程中常见的高阶代码的开销。现在2.12版本(希望)是一个最终的发布候选,整个团队已开始在做2.13了。2.13的特性正在定义中,但是它会包含一个新的集合类(是由社区要求的)以及其他从Dotty来的特性。
特别是Lightbend在Scala 2.12版本的工作,一定程度展示了他们响应了函数式编程社区的需求和建议。
最后,有趣的是,随着Dotty正在逐渐能够编译大部分主要Scala生态系统中的东西,开发周期时间的显著减少是可期的,这让不少公司表示有兴趣尽快地迁移过去。我们很期待当Dotty与Scala碰撞在一起会发生什么。
行为准则的战争
Scala是一种多范式的语言,它的社区当然也反映出了这一点。Martin Odersky原本对Scala的目标是证明函数式代码可以按照面向对象的准则来组织。这一设计理论使得除了一些上面提到的项目中产生的Java变体语言之外的,从纯函数式编程语言变化而来的语言(例如Haskell)被广泛采用。
社区分裂:Cats和Scalaz
从历史上来看,Scala函数式编程社区的代表是Scalaz,其目前仍然是GitHub上评分最高的Scala库之一。有且总是有相当一部分Haskell的开发人员投身在Scalaz上。从一开始,这个社区就全力倡导将Haskell这样的函数式编程模板、语法引入到Scala中。
2014年底,在新的行为准则(CoC)引入失败后,社区开始分崩离析,正如Edward Kmett在这篇推文里所说。
事实上,Typelevel的人离开后创建了一个新的函数式编程库(Cats)。尽管它并不是一个Scalaz的直接分支,但是依然使用了很多相同的概念,因此或多或少都是Scalaz的一个直接的竞争者。
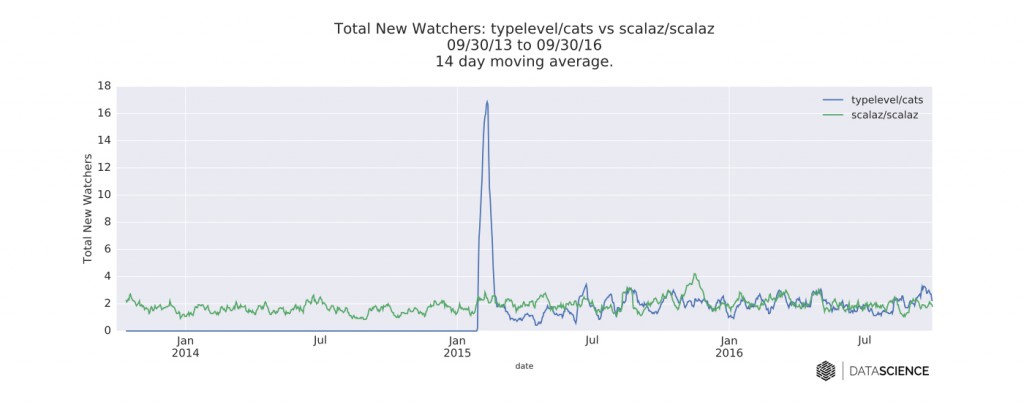
图七 Cats和Scalaz的GitHub库的每日新关注数的时间序列数据。图片由DataScience.com授权使用
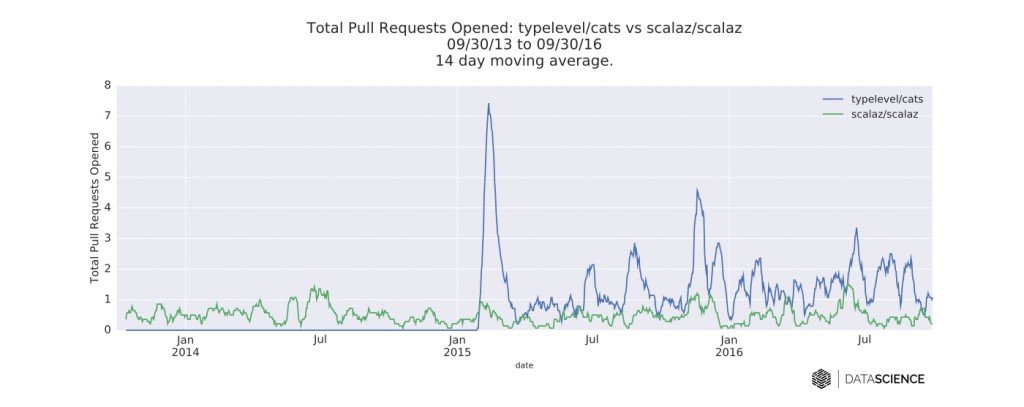
图八 Cats和Scalaz的GitHub库的每日新PR数的时间序列数据。图片由DataScience.com授权使用
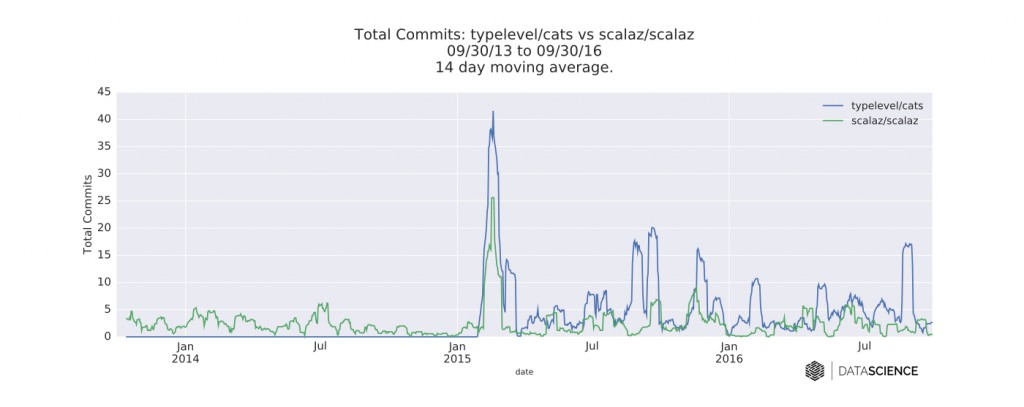
图九 Cats和Scalaz的GitHub库的每日新提交数的时间序列数据。图片由DataScience.com授权使用
从PR的活动指标的整体幅度来看,Cats比Scalaz要大。尽管部分原因可能是因为它的库的建立时间较晚。然而,从每天的提交数和新关注数来看,随着时间的变化,Scalaz并没有表现出明显的下降。所以说,社区中的一些人的恐惧已经淡化了。事实上,Scalaz和Cats的并存已经给下游的库带来了很多头疼的问题,尽管大部分似乎都有可行的解决方案。比如可以通过包含所有的必须的函数式编程依赖(像FS2和scodec所作的那样),或是通过使用shimes工具,或是进行源代码预处理。
另一方面,可能Tony Morris说的是对的,Scalaz项目在动机上和Cats是截然不同的,最终两者都会有空间来演化并服务于Scala社区的不同需求。Cats一直努力保持轻量级和模块化(参见这里和这里),同时避开了Scalaz中相对复杂的语法。
言论自由碰上非暴力传播
Scalaz行为准则(CoC)引入失败的几个可能的原因包括:第一个是因为其引入而被禁止的人正好是项目的创始人。然而,更主要的原因可能是CoC是在一个七年之久的社区内被提出的,而不是在刚开始阶段就被引入的一个社区。以这种方式改变群体话语的模式,可以说等于要求参与者加入一个完全独立的运动。从而出现两个最有可能的结果,或者对CoC的直接拒绝,或者CoC直接被忽视(这是在Scala内部发生的事情)。并且持续的消极情绪拖累论坛活动,导致其趋于停滞。
Scalaz的闹剧暴露出来的主要鸿沟是在开源软件开发上的行为准则的哲学分歧(同样的问题最近在Scala辩论论坛上也发生了)。一方觉得想法都是差不多的,这些想法如何沟通不怎么重要(这个辩论发生在今年的LambdaConf会议上)。他们觉得只是简单的因为传递方式是粗鲁和无礼的就无视批评是不可接受的。
另一方觉得暴力沟通拖累了整个社区,因此可接受的沟通是要被CoC所限制的。从个人的经验来说,我与Typelevel的人的交互是相当积极的,我们团队中的每个人都是这样。Typelevel对于新加入的人的耐心对于我们使用它们的项目是十分有帮助的,特别是Cats。
你应该用Scala吗?回应一些恐惧、不确定和怀疑
像任何主流语言一样,Scala已经吸引了相当数量的权威的支持,但同时也伴随着“Scala太棒了”和“Scala正在死亡”(像这一条,显然是一个Java开发者写的)的话语。如果你正在考虑学习Scala或者是雇用一个Scala团队,你应该两方面都要考虑并且有自己判断。同时也要了解一些已经被揭秘的明显的恐惧、不确定和质疑。我想要来讨论几个最常见的顾虑(这里是一个不错的关于其他几个顾虑的讨论)。
1. 关于Typesafe的更名和Scala的维护管理的担忧
大家可能不知道,今年2月份,Scala的母公司Typesafe更名为Lightbend。这个担忧对我来说有点过于夸大了。Lightbend的CEO Mark Brewer在一篇博客中讲的很清楚,Lightbend将继续致力于这一语言和Scala相关社区的贡献。当我跟Brewer提到这一长期存在的担忧时,他回复到:
我们很幸运能有这样一个非常吸引人(也是很喧嚣)的Scala社区,这意味着对于Lightbend在做什么的会得到非常多的反馈。尽管没有抱怨,但是我们宁愿有抱怨而是没有关注。
2. 关于开发人员上手难易的担忧
这一担忧是成立的。Scala跟其他语言相比有着陡峭的学习曲线。且缺乏集中式的入门材料和社区论坛(像Rust有的那样)一直是一个问题。今天3月,EPFL宣布为Scala成立一个开源基础社区,叫做Scala Center(由Lightbend、IBM、Verizon等公司支持)。
3. 需要更好的文档
希望Scala Center的引入也可以带来更多在文档上的改进。我跟Heather Millar——Scala Center的执行董事谈到文档时,她是这么说的:
我一直觉得文档是一个问题,公司应该招聘一个技术写作人员来解决这个问题。作为一个亲自编写了大部分基础Scala文档的人,我过去五年对此都十分有激情,现在这不应该再是一个志愿任务了。然而由于Scala Center的管理运作模式,我个人不能决定Scala Center是否需要出资招聘一个专业的写手来改进文档。在我可以进行招聘之前,需要在最近的顾问委员会会议上提出来讨论,并由大家投票决定。
Scala Center有3.5个全职员工。作为EPFL的一部分,他们是有非常严格的招聘限制的(员工必须是联邦大学的一部分,薪资是不具有竞争力的等)。该中心每周从非官方途径听取来自个人、公司、顾问委员会成员的意见。这些建议被提炼成提案,每3个月在顾问委员会会议上提交。然后顾问委员会对这些提案进行投票,考虑所有涉及的利益相关者的最迫切的需求。Scala Center会尽全力让他们的人来实现这些提案。
4. 对于Scala社区流程的担忧
这一担忧某些程度上来看是成立的。除了(与之有关)Scalaz的小插曲,已经有更多的人抱怨随意浏览的行为以及随之而来的论坛的参与度的下降。Miller说很多人联系她说(大部分是女性):她们觉得,
不仅是害怕,而且感到丢脸。或者她们看到人们互相指责,这使得她们甚至不想参与。她们觉得这是一个充满敌意的环境,远甚于其他她们参与的社区。
目前,Scala Center主要关注于像缓解Scala/Dotty迁移的复杂度以及改进高层监管这样的项目(他们最近重启了Scala的改进流程)。他们正在准备一个关于新的Scala平台流程和一个关联类库的重构的重要声明。
5. 对于招聘Scala开发人员的担忧
这一担忧是很有道理的。如果你预期需要建立和培养一个非常大的团队或是快速培养一个团队,Scala可能对你来说并不合适的。相对于其他主流函数式语言开发人员来说,Scala开发人员的需求量也比较大。
专家技术人员某种程度上来说是分布良好的,有很多人在主要的技术中心地区工作,小部分人分散在全美各地。然而,出了湾区、洛杉矶、纽约和西雅图地区,你可能要去适应进行远程合作。有经验的Scala开发人员也充分意识到了自己的价值。尽管招聘一些有经验的Scala开发人员是可能的,但是想在你团队里填满成熟的Scala人才可能不是简单和高性价比的。相比于通过标准的Java招聘策略来招聘成熟的Java人才来建立一个开发团队,Scala的情况是不一样的。
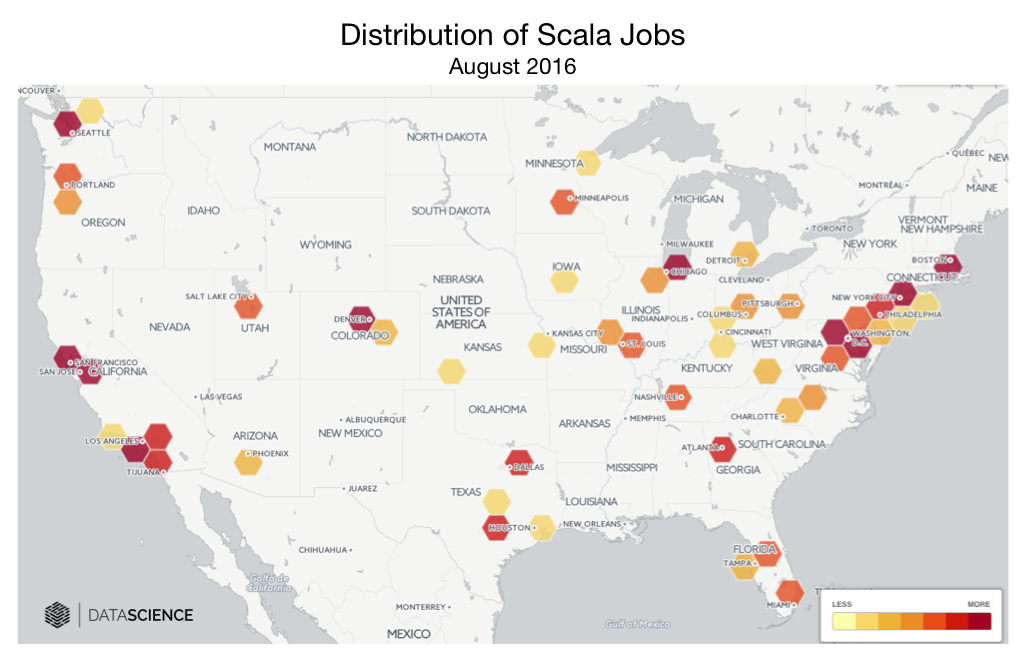
图十 2016年8月美国Scala职位分布。图片由DataScience.com授权使用
一个语言的成长
Scala社区已是前所未有的高生产效率。我们也看到工业界往函数式编程的转向,这丰富了现在技术栈的内容,可能是一个好事情。Scala发现了分布式数据处理上的一个明确的缺口,并且正在推动技术主流去使用函数式技术。从这方面来看,Scala从一个有激情的函数式编程社区中获益良多。
我不认为大部分的Scala社区希望看到Scala完全商业化。然而,在大部分与我交谈的人中,有一个共识,就是像Java一样的趋势发展是不健康的。Java达成了完全的统治地位,而后十年几乎停滞不前,这对编程界来说不是一个好事。所以,(Scala社区将)继续实验和力争健康成长。抵制早期的标准化,并简化扩展而不是堆砌语言。随着对Scala理解的深入,去弄清楚和不断修正它,并且向一个更接近可变和不可达之间的最佳效果不断迭代前进。
感谢Janie Chen 和 Dave Goodsmith 在我撰写本文时对我的帮助。

Chris McKinlay
Chris McKinlay 是DataScience公司的工程师总监。Chris于2013年在加州大学洛杉矶分校获得数学博士学位,以攻破OkCupid网站而著名。Chris很高兴能跟他的第88个约会对象结婚,并且住在洛杉矶。可以通过推特@cem3394 联系他。





更多内容可以参考Strata北京2017的相关议题。