这篇文章是一步一步的使用指南,介绍了如何结合使用Elasticsearch和其他ELK技术栈(现在叫Elastic Stack)来发送、解析、存储和分析日志。在这个指南里我会使用:
- Filebeat:用于收集日志(注意:日志里包括的信息还可能有指标、SQL事务记录和其他的Beat能收集的信息源)。
- Logstash:用于处理日志和指标,并把他们转变成结构化的事件,以便于Elasticsearch进行索引处理。
- Kibana:用于对存储在Elasticsearch里的结构化数据做可视化展现。
在这里,我会使用Apache的访问日志作为例子。但你从这篇文章里所获得的知识可以让你运用于其他类型的日志。文章最后我们会看看对这样的系统扩展到生产级别所面临的挑战,无论是你自己干还是使用第三方提供的ELK/Elastic Stack。
安装和配置Elasticsearch、Kibana和Filebeat。
Elasticsearch
Elasticsearch是一个Java应用,所以你需要安装最新版的JDK(Oracle的或是Ubuntu 16.04上的OpenJDK)。在Ubuntu 16.04版里,你可以用下面的命令安装OpenJDK 8。
sudo apt-get install openjdk-8-jdk
如果你用的是RPM/DEB的Linux,我推荐下面这个官方包。文章里会用APT资源库来获得5.x版本。
wget -qO – https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add –
echo “deb https://artifacts.elastic.co/packages/5.x/apt stable main” | sudo tee -a /etc/apt/sources.list.d/elasticsearch-5.x.list
sudo apt-get update && sudo apt-get install elasticsearch
在启动Elasticsearch(命令是sudo service elasticsearch start)前,你需要决定给它分配多少内存。这可以通过修改/etc/elasticsearch/jvm.options文件里面的-Xms和-Xmx值来确定。经验法则是一开始使用服务器总内存的一半来配置这两个值,这样剩下的一半内存可以被操作系统用于缓存。以后可以通过监控Elasticsearch的heap使用情况以及根据IO吞吐量的需求再调整这两个值。
Kibana
Kibana可以通过使用Elasticsearch同一个APT资源库来获取并安装。
sudo apt-get install kibana
sudo service kibana start
Filebeat
同样,我们还是使用同一个APT资源库来安装Filebeat。
sudo apt-get install filebeat
默认地Filebeat 5.0会向Elasticsearch推送一个模版。对于大多数的应用场景,这个模版都可以配置与filebeat*模式相匹配的索引。例如,大部分的字符串都会被作为关键字索引起来,从而能很好地为分析(Kibana的可视化)所用。message字段会作为文本被索引,从而能被用来做全文本搜索(Kibana的Discover分页)。对应于Apache的日志文件,你需要通过配置filebeat.prospectors(里面的第一个prospector定义为:input_type: log)里面的paths(路径)变量来把Filebeat指向它们。你需要用如下方式来定义这个路径:
paths:
– /var/log/apache.log
然后启动Filebeat。你的日志应该开始被导入了:
sudo service filebeat start
在Kibana里对日志进行可视化展现
到这里,你可以在浏览器里打开Kibana(默认端口是5601)来查看Elasticsearch里的日志了。首先你需要通过定义一个“索引模式”来指示被搜索的索引。把它设成filebeat-*:
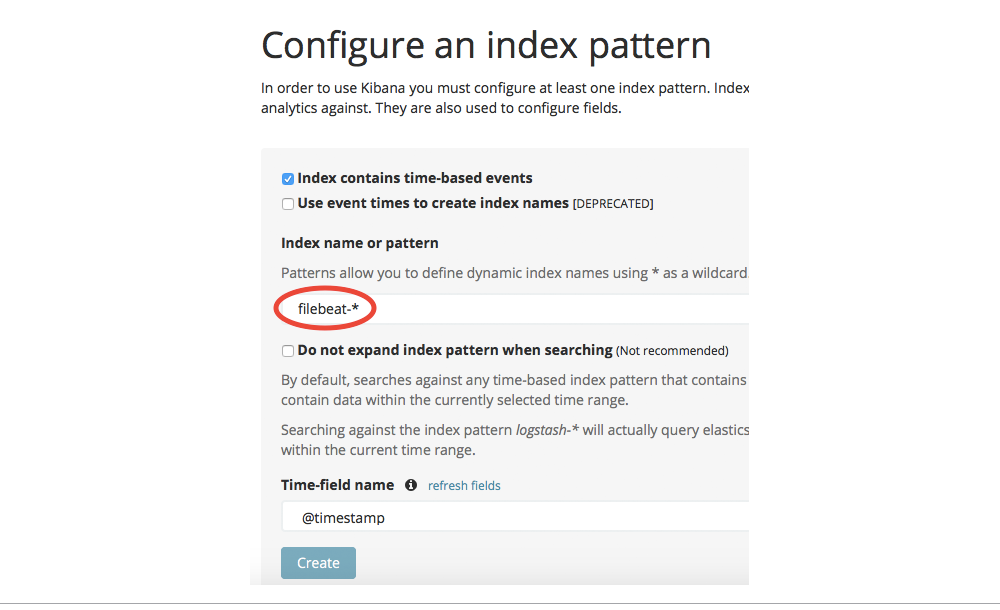
图1 图片由Radu Gheorghe友情授权使用
接着你可以去Discover面板并搜索日志。例如,你采用与grep类似的方式搜索日志的内容,但也会有一样的缺陷。比如,如果你搜索“200”,你就无法确定是“200 OK”响应还是“200 bytes”被传送。
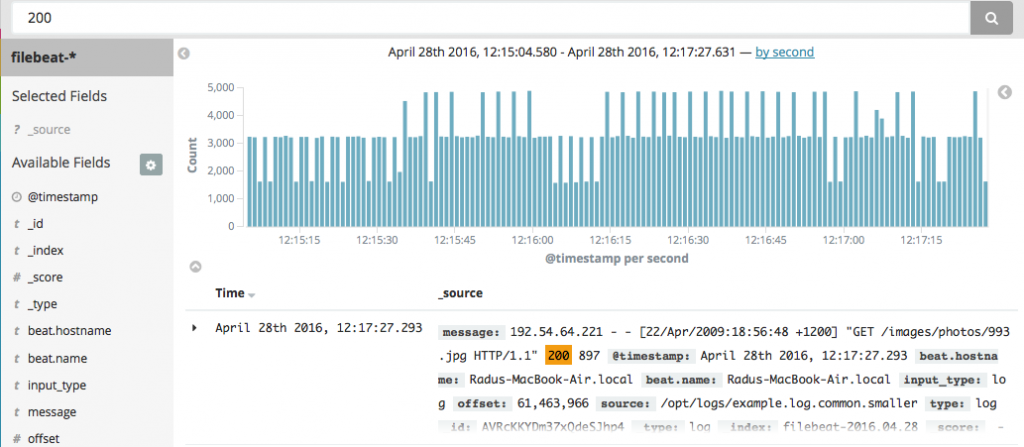
图2 图片由Radu Gheorghe友情授权使用
需要可视化时,你可以进入Visualize分页并按主机名区分显示。但是同样的,你也无法使用message字段里的信息,因为它里面的不同的部分(比如响应编码)还没有被解析为它们自己的字段:
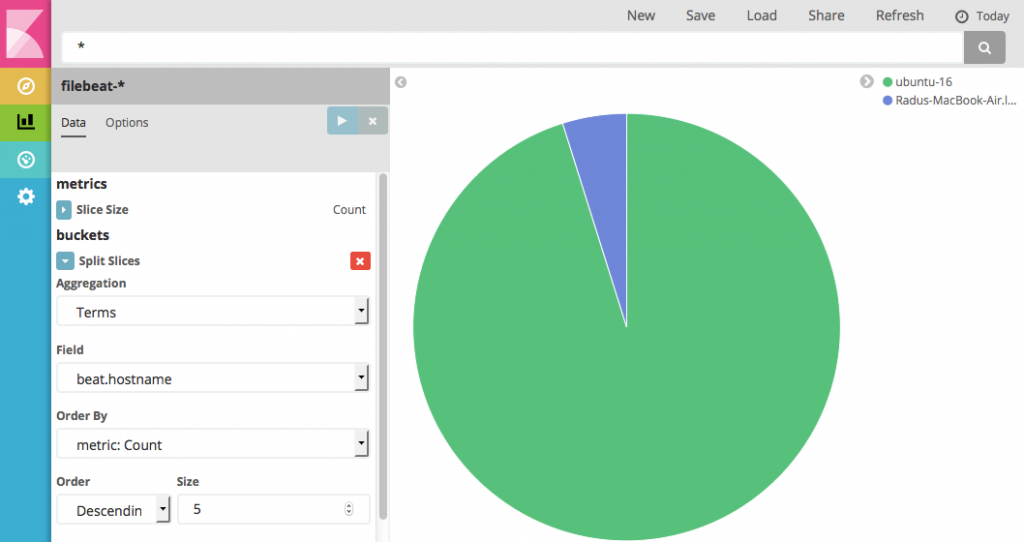
图3 图片由Radu Gheorghe友情授权使用
使用Logstash解析数据
为了能全面地探索你的日志数据,你需要一个能解析它们的工具。Logstash就是这样一个工具。在Elasticsearch 5.0版里,你可以使用一个Elasticsearch的“消化节点”来进行这一处理,它能带来性能的显著提升。但是消化管道并不能为Logstash提供灵活性(例如条件)。所以在这个文章里我们会只会关注Logstash。
为了构建Filebeat -> Logstash -> Elasticsearch -> Kibana的管道,你需要安装和配置Logstash,并更新Filebeat的配置选项来让它从原来指向Elasticsearch改为指向Logstash。让我们一步一步地完成这个过程:
首先用相同的资源库来安装Lostash:
sudo apt-get install logstash
随后在/etc/logstash/conf.d/文件夹里创建一个文件(比如说logstash.conf)。在这个文件里设置一个beats input让Filebeat来连接。接着你可以使用grok filter来解析你的数据,然后再发送给Elasticsearch。
input {
beats {
port => 5044
}
}
filter {
grok {
match => [ “message”, “%{COMMONAPACHELOG}” ]
}
}
output {
elasticsearch {
hosts => “localhost:9200”
}
}
在Filebeat里,你需要注释掉整个output.elasticsearch小节,并把output.logstash下面的hosts配置修改为Logstash的地址:
### Logstash as output
logstash:
# The Logstash hosts
hosts: [“localhost:5044”]
为了能让Filebeat通过Logstash来重发日志数据,你需要做以下几个动作:
- 先停掉Filebeat(sudo service filebeat stop)。
- 删除注册文件。Filebeat在这个文件里记录了它原来指向的Apache日志。这个动作让Filebeat完全重启:sudo rm /var/lib/filebeat/registry
- 删除Elasticsearch里面已经索引的数据:curl -XDELETE localhost:9200/filebeat*
- 最后启动Logstash和Filebeat:sudo service logstash start; sudo service filebeat start
现在你的日志应该已经被Elasticsearch再次索引了。只是这次它们是结构化的,并且默认是存在索引logstash-*下面。Logstash使用了一个与Filebeat类似的模版,所以目前你还不用操心它的配置。
再去看一下Kibana。你需要在Settings分页下新建一个索引模式,并配置logstash-*指向索引。你可能也想把这个模式设为默认的。
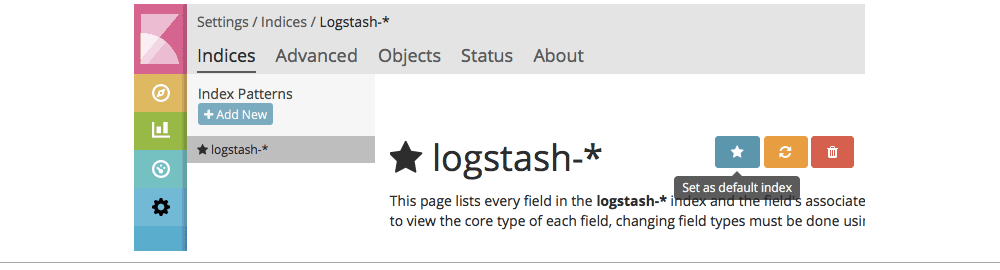
图4 图片由Radu Gheorghe友情授权使用
因为现在Apache的日志已经是结构化的了,所以你可以搜索指定的字段。比如这个response字段:
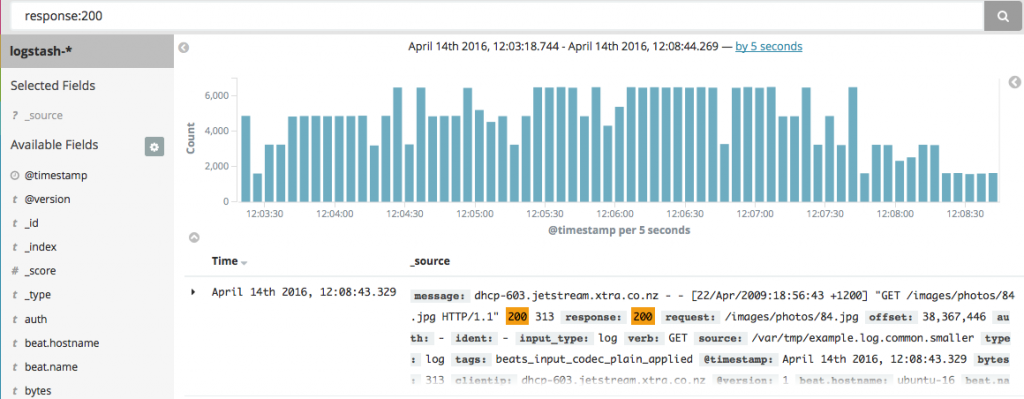
图5 图片由Radu Gheorghe友情授权使用
你也可以构建可视化图来查看不同类型的响应时间随时间变化的情况:
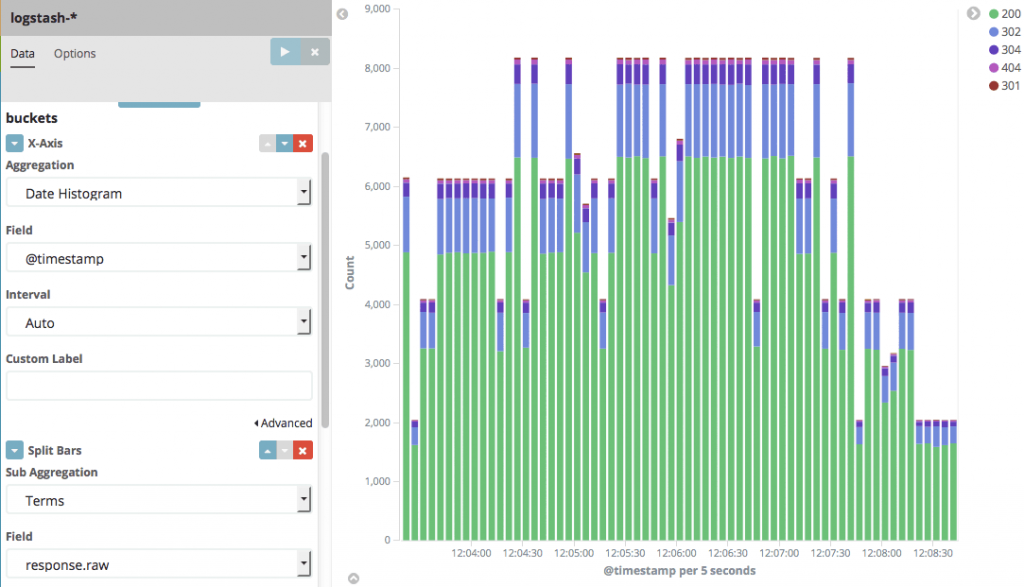
图6 图片由Radu Gheorghe友情授权使用
从概念验证到生产系统
如你所见,Elastic Stack的入门是相当得简单明了。不过想把它用于生产环境的数据则需要做更多的工作。
在数据收集侧,Logstash可能会成为瓶颈,除非你能把它扩展部署到很多节点,或是单机多节点。还有其他的备选方案。比如你可以使用rsyslog。它也很快还是轻量级的。你可以很容易地把它装在每个Web服务器上,让它完成解析和直接发送数据到Elasticsearch的任务。不过,不同的发送者用不同的特征集合。在我们这个场景里,rsyslog允许配置rulesets来使用不同的通道发送消息,但GeoIP默认是不支持这个功能的。
在Elasticsearch一侧,为了实现容错以及处理更多的日志,你需要为集群加入更多的节点。你需要在elasticsearch.yml里做一些修改来实现这个目标。
实现容错
首先定义discovery.zen.ping.unicast.hosts,这样节点间才能相互知道其他的节点的存在,从而形成一个集群。生产环境至少需要3个节点。这样即使一个节点挂了,其他的节点还是能形成一个仲裁组。想定义仲裁组的大小,可以设置discovery.zen.minimum_master_nodes为NUMBER_OF_NODES/2+1。最后,你可以通过设置network.host来让Elasticsearch监听外部接口(而不是监听默认的localhost地址)。这样就能让Filebeat、Logstash、Elasticsearch、Kibana和你的浏览器运行在不同的机器上。
对于包括更多节点的集群的配置或是对已有集群的调优则会要求你对Elasticsearch的工作方式有更深的理解。O’Reilly的培训视频《使用Elasticsearch》只有3个小时长,但会提供给你所有需要知道的关于如何配置和管理Elasticsearch的足够信息。视频内容针对日志和其他的应用场景,例如社交媒体分析和内容搜索等。
自建还是购买
自建Elastic Stack可以让你对Elasticsearch有更多的掌控,包括何时升级、安装什么插件以及如何与其他的在用的技术(如数据库、数据处理工具等)相集成。缺点则是要花很多时间、精力和投资来进行日常维护、升级、调优,以及在基础的ELK/Elastic Stack上开发各种各样你需要的特性。如果自建对你来说不是那么有吸引力,你还是有一些其他的选择。
一种选择是使用云端的日志管理服务。这能让你很快就上生产,节省你在配置和维护Elasticsearch上的时间和投入。这些服务一般包括监控、备份和升级等。
如果你想自建Elastic Stack,同时还想降低启动的时间,那就有很多的选择可供考虑。比如这个O’Reilly的视频课程、Elasticsearch培训和ELK/Elastic Stack咨询服务等。

Radu Gheorghe
Radu Gheorghe是Sematext公司的搜索咨询师和软件工程师。作为咨询师,他与客户一起基于Elasticsearch或Solr开发搜索、分析和日志的解决方案。他也是支持团队的一员,帮助解决这些解决方案的生产系统里的问题。作为软件工程师,他主要贡献于Logsene、Sematext的日志SaaS。Radu是《使用Elasticsearch》视频教程的作者,同时也是《Elasticsearch in Action》的作者之一。





