在这一集的数据秀里,我采访了英特尔的大数据技术CTO和Strata + Hadoop World北京大会的联合主席Jason Dai。Dai和他的团队是Apache Spark项目的长期多产贡献者。他们对Spark项目早期的主要贡献是系统层面的,包括基于Netty的shuffle、公平调度器和yarn-client运行模式。近期,他们主要贡献了一些高级分析所用的工具。在与中国的主要云服务商结成合作伙伴关系后,他们已经实现了一些算法的基础模块和机器学习的模型,这些部分使得Apache Spark可以扩展处理极高维度的模型和超大数据集。他们是通过使用诸如“数据稀疏性”和英特尔的MKL软件来实现这个可扩展性的。在取得这些成就的过程中,他们对于企业如何在真实应用里部署机器学习模型获得了宝贵的经验和洞察。

在我预测2017年将会是大数据与数据科学领域开始认真探索诸如深度学习这样的技术的一年时,我是依据与这个领域的多位专家沟通后作出的。我也了解到Dai和他的团队为Apache Spark的深度学习库做出了贡献。从贡献基础架构到机器学习应用,再到现在的基于深度学习的应用,他的团队的整个演化过程是可以预测的。
一旦有了一个平台和团队可以让你部署机器学习的模型,很自然地你会开始探索深度学习。正如我在最近的数据秀的一集里指出的,企业正在开始应用深度学习技术到时间序列数据、事件数据、文本和图像数据上。其中的大部分企业已经在大数据技术(大部分都是开源的)上进行了投入,并雇佣了数据科学家和数据工程师,而且这些人对于这些大数据工具都很熟悉。
尽管有很多可用的深度学习的库、云服务和打包的解决方案可用,部署深度学习通常会涉及到海量(标记过的)数据、超大的模型和大型计算。因此一个典型的深度学习项目都会涉及到在Spark集群上进行数据获取、预处理和准备,并在多GPU服务器上的进行模型训练。
一个新的被称为BigDL的项目提供了另外一种选择:即直接把深度学习引入大数据生态系统。BigDL是为Apache Spark开发的开源的、分布式的深度学习库。它有着与现有流行的深度学习框架(如Torch和Caffe,BigDL参考了Torch的模型)相一致的特征。对于许多已经有数据在Hadoop/Spark集群上的企业而言,BigDL可以让它们在已有的相同的集群上使用深度学习。
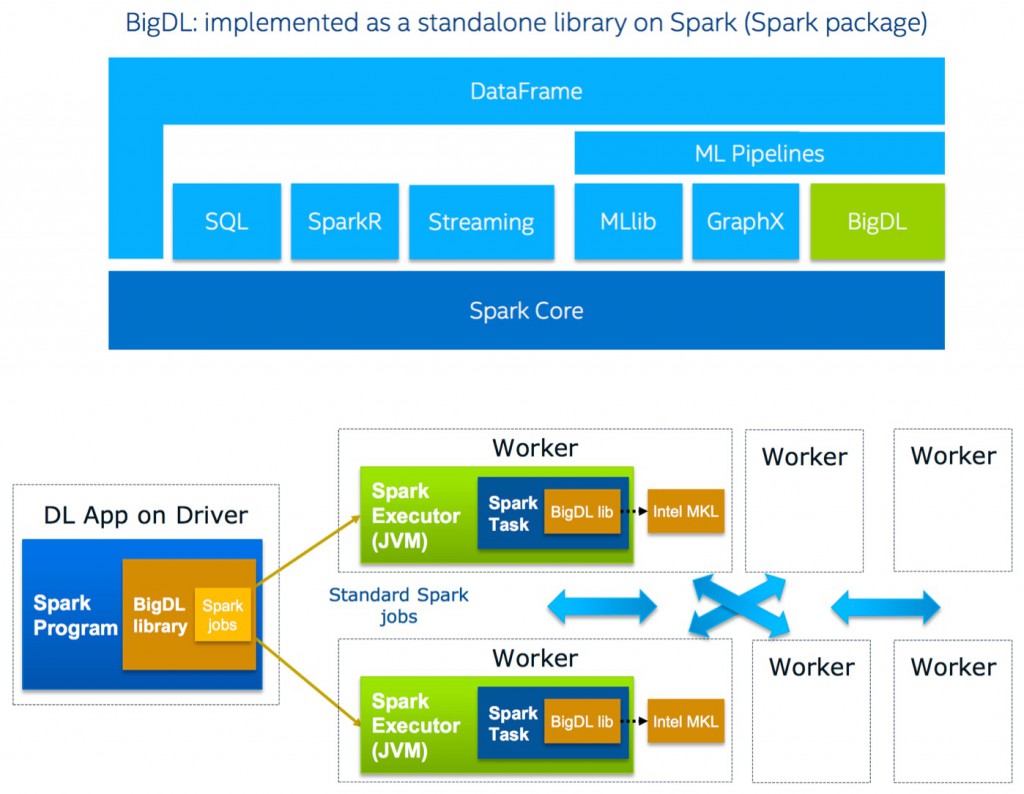
来源:Jason Dai授权使用
对于需要在Spark集群上进行数据预处理和准备并在装配多个GPU服务器上进行模型训练的典型的深度学习任务,现在可以只用一个简单的Spark库,并运行在进行数据预处理和准备的相同的集群上。BigDL利用了MKL软件,并能让你高效地在集群上训练更大的模型(使用分布的、同步小批次的随机梯度下降法,SGD)。同时它提供的AMI(亚马逊机器镜像)可以被用来在亚马逊的AWS上部署和尝试使用BigDL。
对于处于学术前沿的研究人员而言,GPU还是能提供更快的训练深度学习模型的速度。不过对于那些已经在大数据集群的软硬件上已经有了投入的企业,BigDL就有吸引力了(方便vs性能)。这对于使用云计算资源的企业而言就更是如此了。甚至是对于已经投资CPU多于GPU的公有云服务商而言,BigDL也是有吸引力的。
大量数据产品都有非常复杂的数据管道部分,而机器学习建模仅仅只是整个系统中很小的一个组成部分。我可以预见,BigDL会吸引一些企业,因为它带来了使用统一的基础平台来进行数据处理、存储、特征工程、分析、机器学习和现在的深度学习的可能性。这意味着不需要在集群和框架(BigDL仅仅是一个Spark的库)间传输数据、更低的端到端的训练时间和更简单的资源与工作流管理。实际上,这也就是BigDL产生的原因:在了解到多家中国的企业对于使用已有的硬件和计算资源来进行深度学习项目的有兴趣后,这个团队就决定搞这么一个东西出来。
2016年底,BigDL作为一个开源项目被发布。在发布前的几个月期间,Dai和他的团队已经帮助了一些企业在他们的由几十个赛扬服务器组成的Spark集群的生成系统上部署使用了BigDL。早期的使用案例包括一个大型支付公司和一家大型商业银行里使用的欺诈检测系统,以及在多家大型制造企业里使用的图像分类和物体识别应用。
目前我们还是处于将深度学习引入企业的机器学习模型库的非常早期的阶段。我预计企业还会持续地对各种各样的深度学习的可管理的服务、专利和开源工具进行试验。对于那些希望能充分利用已有的大数据基础设施和方便已经熟悉这些框架的团队采用深度学习的企业而言,BigDL提供了一种选择。采用BigDL还有经济上的好处。即除了使用已经在用的工具所带来的方便性之外,还能通过降低复杂性和增加现有设施的使用率来获得更低的总所有成本(TCO,Total Cost of Ownership)。
Strata + Hadoop World北京2017大会的议题征集即将在2017年2月24日截止。
相关资料
- 《在Apache Spark上的互联网规模的机器学习》:Jason Dai在2016年Strata新加坡大会上的演讲
- BigDL(深度学习)、SparseML(稀疏数据集上的机器学习)和主题模型的代码
- 2017年将会是大数据与数据科学领域开始探索使用人工智能技术的一年
- 为大型企业构建深度学习解决方案的关键点
- 把深度学习用于你已有的数据
- 大型计算如何推动深度学习的火箭
订阅O’Reilly数据秀播客,探索推动大数据、数据科学及人工智能的机遇和技术。可以在 iTunes, Stitcher, TuneIn, SoundCloud, RSS 找到我们。

Ben Lorica
Ben Lorica是O’Reilly Media的首席数据科学家和数据主题内容策略的主管。他已经在多个领域里(包括直销市场、消费者和市场研究、精准广告、文本挖掘和金融工程)进行了商业智能、数据挖掘、机器学习和统计分析的工作。他之前曾效力于投资管理公司、互联网创业企业和金融服务公司。





