深度学习的核心问题就是一个非常难的优化问题。所以在神经网络引入后的几十年间,深度神经网络的优化问题的困难性是阻碍它们成为主流的一个重要因素。并导致了它们在20世纪90年代到21世纪初期间的衰落。不过现在已经基本解决了这个问题。在本篇博文中,我会探讨优化神经网络的“困难性”,以及理论上是怎么解释这个问题的。简而言之:神经网络变得越深,优化问题就会变得越难。
最简单的神经网络是单节点感知器,其优化问题是凸问题。凸优化问题的好处是所有的局部最小值也是全局最小值。存在各种各样的优化算法来解决凸优化问题,并且每隔几年就会发现更好的用于凸优化的多项式时间的算法。使用凸优化算法可以轻松地优化单个神经元的权重(参见下图)。下面让我们看看扩展一个单神经元后会发生什么。
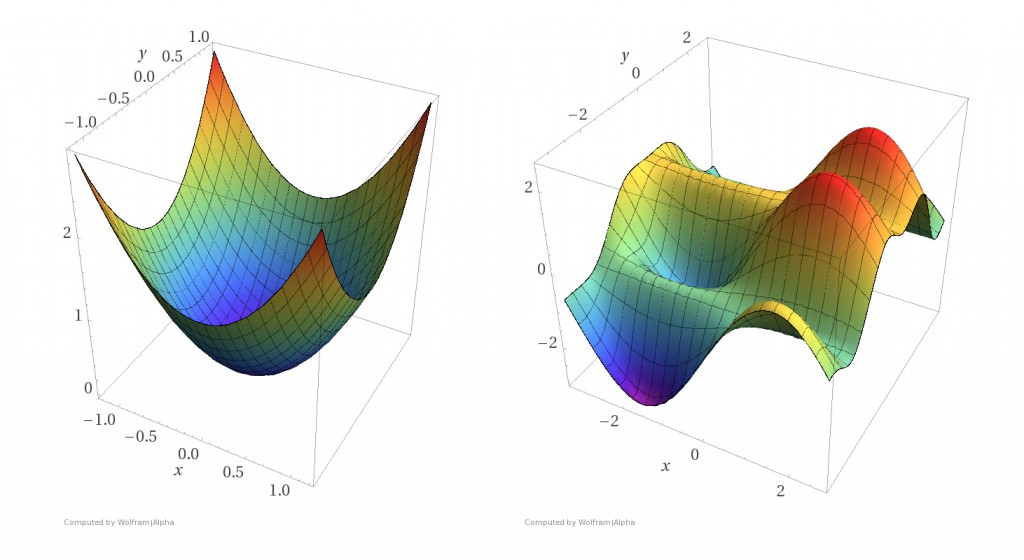
图1 左图:一个凸函数。右图:一个非凸函数。凸函数比非凸函数更容易找到函数曲面的底部(来源:Reza Zadeh)
下一步自然就是在保持单层神经网络的情况下添加更多的神经元。对于单层n节点感知器的神经网络,如果存在边权重可以使得神经网络能正确地对训练集进行分类,那么这样的边权重是可以通过线性规划在多项式时间O(n)内找到。线性规划也是凸优化的一种特殊情况。这时一个问题应运而生:我们可以对更深的多层神经网络做出这种类似的保证么?不幸的是,不能。
为了可证明地解决两层或多层的一般神经网络的优化问题,需要的算法将会遇到某些计算机科学中最大的未解问题。因此我们对机器学习研究人员尝试找到可证明地解决深度神经网络优化问题的算法不抱有太大的希望。因为这个优化问题是NP-hard问题,这意味着如果在多项式时间内可证明地解决这个问题,那么也可以解决那些几十年来尚未被解决的成千上万的问题。事实上,J. Stephen Judd在1988年就发现下面这个问题是NP-hard问题:
给定一个一般的神经网络和一组训练样本,是否存在一组网络边权重使得神经网络能为所有的训练样本产生正确的输出?
Judd的研究还表明:即使要求一个神经网络只为三分之二的训练样本产生正确的输出仍然是一个NP-hard问题。这意味着即使在最坏的情况下,近似训练一个神经网络在本质上还是困难的。1993年Blum和Rivest发现的事实更糟:即使一个只有两层和三个节点的简单神经网络的训练优化问题仍然是NP-hard问题。
理论上,深度学习与机器学习中的很多相对简单的模型(例如支持向量机和逻辑回归模型)的区别在于,这些简单模型可以数学证明地在多项式时间内完成模型优化。对于这些相对简单的模型,我们可以保证即使用运行时间比多项式时间更长的优化算法也都不能找到更好的模型。但是现有的深度神经网络的优化算法并不能提供这样的保证。在你训练完一个深度神经网络模型之后,你并不知道这个网络模型是否是在你的当前配置下能找到的最优的一个模型。所以你会存有疑虑,如果继续训练模型的话是否可以得到一个更好的模型。
幸运的是我们在实践中可以非常高效地接近这些最优结果:通过运行经典的梯度下降优化方法就可以得到足够好的局部最小值,从而可以使我们在许多常见问题上取得巨大进步,例如图像识别、语音识别和机器翻译。我们简单地忽略最优结果,并在时间允许的情况下尽可能多地进行梯度下降迭代。
似乎传统的优化理论结果是残酷的,但我们可以通过工程方法和数学技巧来尽量规避这些问题,例如启发式方法、增加更多的机器和使用新的硬件(如GPU)。一些研究工作正在积极地探索为什么理论结果很残酷,但这些经典的优化算法却工作得这么好。
深度学习能成功的因素远远不只克服优化问题。神经网络的架构、训练数据的数量、损失函数和正则化等都对于能在机器学习任务中获得高质量的结果起着关键作用。在后续的博文中,我将会讨论涵盖这些方面的最新的理论成果,来解释为什么神经网络在各种任务上工作得如此好。

Reza Zadeh
Reza Zadeh是斯坦福大学的兼职教授、Matroid创始人和首席执行官。他的工作主要关注于机器学习、分布式计算和离散应用数学。他曾在Miscrosoft和Databricks的技术顾问委员会任职。