我总是在关注和寻找可以改进我如何解决数据分析项目的好想法。尤其喜欢可以转化为我可以重复使用的工具的那些方法。大部分时候,我都是通过自己反复尝试或者咨询其他从业人员来发现这些工具。我与学术界和学术研究也有着密切联系,我经常发一些推文推荐我偶然看到并为之入迷、深感兴趣的学术论文。通常情况下,学术研究的结果不会马上转化为我所能用的,但是我最近偶然从几个研究中发现一些想法,值得与大家分享。
我在这篇文章中阐述的想法解决了一些经常出现的问题。在我看来,这些想法也强化了数据科学中包含的数据管道的概念,而不仅仅是机器学习算法。这些想法也应该能给试图构建人工智能应用的工程师们带来启示。
使用可重用的保留数据法来避免在交互式数据分析中出现过拟合
过拟合在统计和机器学习领域是一个众所周知的问题。像保留部分数据做验证法、自助法以及交叉验证法等技术被用来在静态数据分析中避免过拟合。被广泛应用的保留部分数据做验证法将整个数据集划分成两个独立集合。但是从业人员(包括我自己)经常在应用经典的保持法的时候忘记重要的一点:理论上相应的保留数据集只能被使用一次(如图一所示):
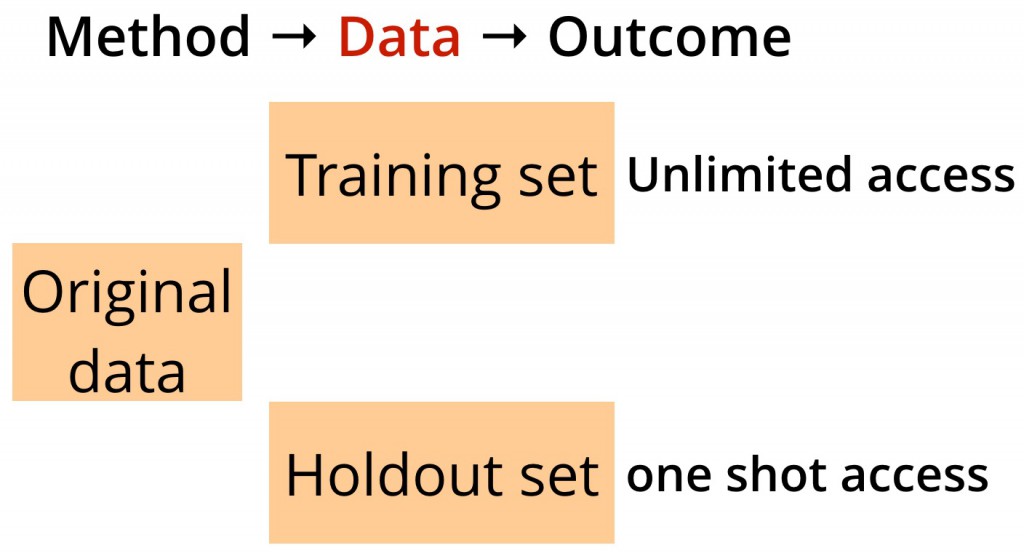
图一:静态数据分析,由本·骆易家提供
而事实上,目前大部分数据科学项目本身都是交互式的。数据科学家反复迭代多次并且基于之前的结果修正他们的方法或者算法。很多情况下同一个保留数据集被频繁多次地使用,这将会导致过拟合(如图二所示):
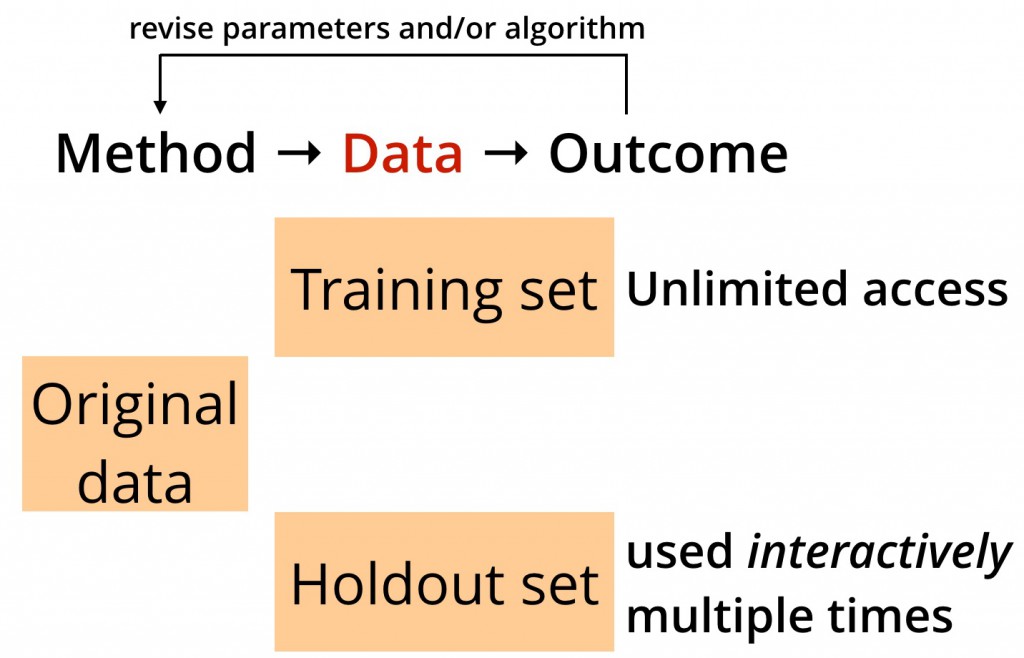
图二 交互式数据分析,由本·骆易家提供
为了解决这一问题,有一个研究团队通过借鉴差分隐私的思想设计出了可重用的保留数据做验证方法。通过解决过拟合问题,他们的方法可以增加数据产品的可靠性,特别是在有更多的智能的应用被部署的关键场合里。好消息是他们得出的解决方案对于数据科学家来说是开放的,而且并不要求对差分隐私这一概念的理解。在圣何塞铁杆数据科学会议上的一次演讲中,谷歌的莫里兹·哈特(其中一名研究人员)描述了他们提出的阈值保留数据法,下面是其对应的Python代码:
from numpy import *
def Thresholdout(sample, holdout, q):
# function q is what you’re “testing” – e.g., model loss
sample_mean = mean([q(x) for x in sample])
holdout_mean = mean([q(x) for x in holdout])
sigma = 1.0 / sqrt(len(sample))
threshold = 3.0*sigma
if (abs(sample_mean – holdout_mean)
< random.normal(threshold, sigma) ):
# q does not overfit: your “training estimate” is good
return sample_mean
else:
# q overfits (you may have overfit using your training data)
return holdout_mean + random.normal(0, sigma)
他们的阈值保留数据法和其他方法的细节可以在这篇论文和哈特的博客文章中找到。我也推荐最近的一篇关于盲样分析的论文——一个相关的数据摄动法在物理学中的应用,可能很快会在其他学科也得到应用。
使用随机搜索进行黑盒参数调优
大部分数据科学项目涉及到数据管道,其中包含了一些需要恰当调整的“旋钮”(超参数),通常需要反复试验来完成调优。这些超参数通常伴随着特定的机器学习方法(网络深度和架构、窗口大小等),但是它们也涉及到影响数据准备及其他数据管道中的步骤的多个方面。
随着机器学习管道相关应用日渐增多,超参数调优成为许多研究论文(甚至是商业产品)的主题。许多结果是基于贝叶斯优化和其相关技术。
在职的数据科学家不需要急着去学习贝叶斯优化。最近加州大学伯克利分校的本·雷希特的博客(这篇和这篇)中强调:研究表明当进行黑盒参数调优时,简单的随机搜索实际上与更高级的方法相比是十分有竞争力的。并且他们正在努力提高某些特定工作里的随机搜索的速度。
通过局部近似来解释你的黑盒模型
在某些领域(包括健康、消费金融以及安全),模型解释是常见的需求。而目前黑盒模型风靡全球——包括深度学习以及其他算法甚至是模型组合定义。随着人工智能受到关注,指出黑盒技术仅可以被部署到某些应用领域是十分重要的,这些领域必须已经开发出可以使得模型更加具有解释性的工具。
最近,来自马尔·科图略·里贝罗和其同事们的一篇论文提出了一种可以使得这种模型更加容易解释的方法。在这篇论文中提出的想法是使用一系列可解释的局部可信近似值:这是一些可解释的局部模型,可以近似原始模型在将被预测的实例附近是如何行为的。研究人员观察到,尽管一个模型可能过于复杂以至于不能够全局的解释,但是提供一个局部可信的解释通常来说已经足够。
最近的一个演讲描述了研究人员提供的该方法的实用工具。论文的一位共同作者卡洛斯·贾斯特林演示了一个相关方法的实现,帮助调试一个计算机视觉应用中的深度神经网络。
卡洛斯·贾斯特林将在2016年9月26日至29日在纽约举办的Strata + Hadoop世界大会上做一个名为“为什么我该相信你?解释机器学习模型的预测结果”的演讲。
相关资源如下:
- 局部可解释的模型无关解释的介绍
- 六个我为什么喜欢KeystoneML框架的原因——对话本·雷希特
- GraphLab的演化史——对话卡洛斯·贾斯特林
- 深度学习——Strata + Hadoop世界大会演讲集合

本·罗瑞卡(Ben Lorica)
本· 罗瑞卡是O'Reilly的首席数据科学家和关于数据方面的内容策略主管。在多个领域里(包括直销市场、消费者和市场研究、精准广告、文本挖掘和金融工程),他曾经进行了商业智能、数据挖掘、机器学习和统计分析的工作。他曾效力于投资管理公司、互联网创业企业和金融服务公司。





