去年夏天,我曾在日内瓦的欧洲核子研究组织(CERN)暑期开放实验室实习。我工作的重点是为CERN的大数据分析来探索Apache Spark的MLlib框架。
在CERN,一个主要的实验项目是CMS(世界上最大的粒子物理探测器之一),通过它可以帮助我们对亚原子有更好的理解。实验是在CERN的大型强子对撞击(LHC)上进行的。LHC是一个粒子加速器,可以把亚原子粒子推送到极高的速度并通过CMS探测器可视化。CMS探测器是一个巨大的多层数码相机,记录了每秒LHC的粒子碰撞产生的碎片的图像。CMS实验每一年要收集O(10)拍字节的数据。随着时间的推移,每一次碰撞都会带来巨大的数据量。最大数据的生产速率可以达到约600兆/秒,由此带来了一个相当大的数据处理的挑战。这些数据在全球LHC计算网格的多层计算基础设施保存并处理。
由于数据安排是CERN实验中必要的一个组件,我们正在寻找不一样的方法来改进这个任务,并开发了一个原型试验项目-评估Apache Spark作为CERN的大数据分析基础设施。这一项目的目的是从CMS的数据中得出合适的预测,改进资源利用,并对框架和指标有深层的理解。
理解流行的CMD数据集
此原型项目的第一个阶段是预测新的和流行的CMS数据集。流行度被定义为数据集被用作研究的频繁性。这些被认为是流行的数据集是因为它们日常被物理学家访问,因而需要在全世界各个数据中心复制备份。识别流行的数据集改进了分析的效率并帮助识别可能成为高能物理学的热点话题的数据集,比如Higgs粒子和超对称粒子。
图一展示了随机数据集在2014年每周的流行度,Y轴使用的是对数刻度。每一条线代表了不同的数据集。由黑线代表的数据集在第1到20周比其他多20%-30%的访问,表明该数据集的流行和普及。相较而言,黄线代表的数据集根本没有被访问,表明该数据集是不流行的。
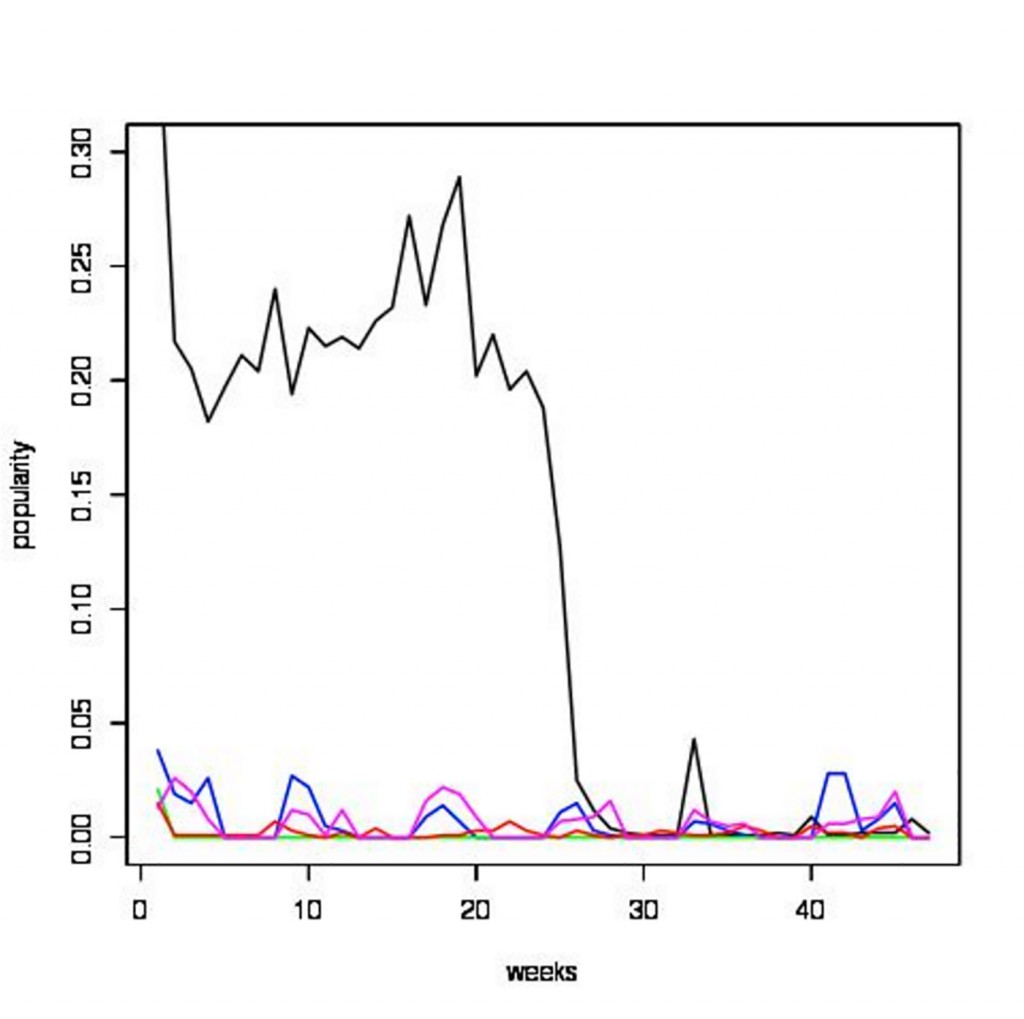
图一 星期为单位的随机CMS数据集的流行度。本图由瓦伦丁·库兹涅佐夫提供,经许可使用
相对流行的数据集也可以通过制作基于单一流行度指标的云图,比如基于Naccess(单一用户访问数据集的总量)、totcpu(cpu分析数据集总花费的小时数,见图二)、nusers(数据集的总访问用户数,见图三)等。这些用户可以是物理学家、学生或者是研究人员。你在图中看到的数字代表了数据集的名字。数据集的命名法包括日期、软件版本和格式,由三个不同的部分定义:进程、软件和层。这三个部分非常重要,因为它们可以帮助复制过程。

图二 使用totcpu指标的CMS数据集的流行度在云图中的表示。本图由瓦伦丁·库兹涅佐夫提供,经许可使用

图三 使用Nusers指标的CMS数据集的流行度在云图中的表示。本图由瓦伦丁·库兹涅佐夫提供,经许可使用
2014年中最频繁被访问的CMS数据集在图四中展示。

图四 2014年100个最频繁访问的CMS数据集在云图中的表示。本图由瓦伦丁·库兹涅佐夫提供,经许可使用
使用Apache Spark来预测新的和流行的CMS数据集
机器学习算法能够运行预测模型并推测随着时间改变的流行的数据集。我将Apache Spark评估为一个将不同的从CMS数据服务收集信息的预测模型流式组合起来的工具。当与更早的通过动态数据安排方法获得的结果比较时,Spark提供的准确度是相近的。一个较大的不同是,其结果是实时获取的。因为Spark可以实时的分析流式数据,在数据产生时滚动预测流行度结果。预测流行的数据集是通过用Spark源生的机器学习库(MLlib)和Python的机器学习算法来完成的。这些算法主要包括朴素贝叶斯、统计随机梯度下降和随机森林。
每一周的数据都会被添加到已有的数据之中,并建立一个新的模型,从而得到更好的数据分析结果。这些模型稍后会被整合进来,并通过真阳性,真阴性,假阳性或假阴性的值进行评估。我也使用了Python的机器学习库(scikit-learn)并比较了从不同框架得到的值。在这一过程中,我能够判断每一个模型的质量。MLlib有几乎所有的机器学习算法的的实现,在CPU开销和内存使用上与Python框架相比有更好的结果。
结论
Spark和scikit-learn的模型原型的准确度几乎相同。通过运用主成分分析法,我可以交互式地为新的数据集选择最佳的预测模型。其他一些对CMS数据分析重要的因素是并行度和快速的分布式数据处理。Spark框架提供了一个简单的编程抽象,提供了强有力的缓存和持久化能力,同时还有很快的速度。结论就是,我们发现Spark的组件(Spark Steaming和MLlib)极大地简化了CMS数据的分析,并可以成功地应用到CMS数据集上。

Siddha Ganju
Siddha Ganju是卡内基梅隆大学计算机数据科学专业的硕士生,2015年夏天在CERN的开放实验室实习。她的研究主要在于机器学习、自然语言处理、信息检索和深度学习的结合之处。Siddha从印度米尔布尔国家科技学院获得学士学位。可以从http://sidgan.me访问Siddha的网站。





