随着企业在更广泛的产品和服务组件中使用机器学习(ML)和人工智能技术,对新的工具、最佳实践和新的组织结构的需求变得越来越清晰。在最近的一些文章中,我们介绍了在企业和机构内支撑机器学习实践所需的基础技术,以及在机器学习中用于模型开发、模型管理和模型运维/测试/监控的专用工具。
为了适应机器学习以及人工智能的兴起,需要进行哪些文化和组织变革?在这篇文章中,我们将从一个受到高度监管的行业(金融服务业)的视角来分析这个问题。金融服务业公司拥有悠久的作为许多新技术的早期采用者的传统。当然人工智能也不例外:
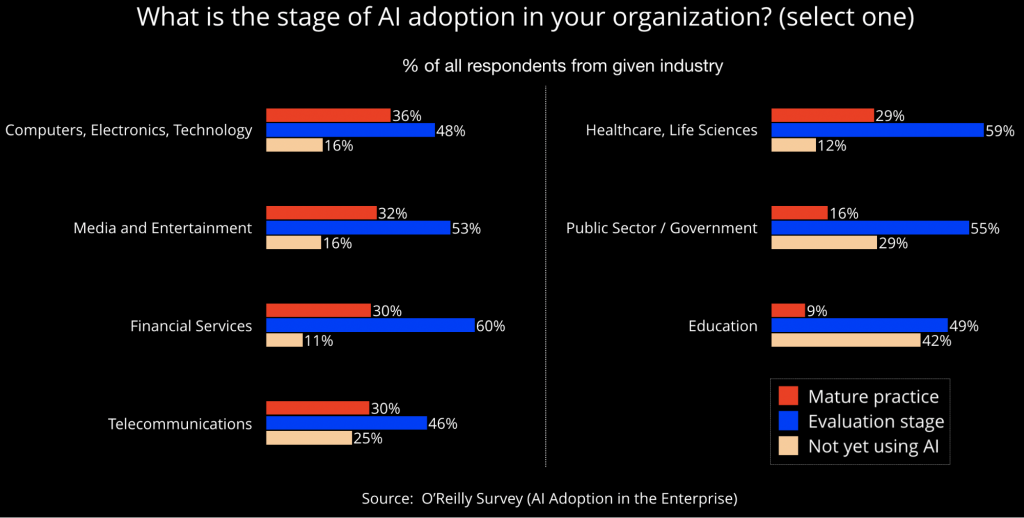
图1 人工智能技术被采用的阶段(按行业分)。图片来源:Ben Lorica
与医疗行业类似,在另一个受到严格监管的行业(金融服务业)里,长时间以来企业必须在它们的一些算法(例如,信用评分)中建立可解释性和透明性。根据我们的经验,大部分最受欢迎的关于模型可解释性和可理解性的会议发言是来自金融行业的人士。
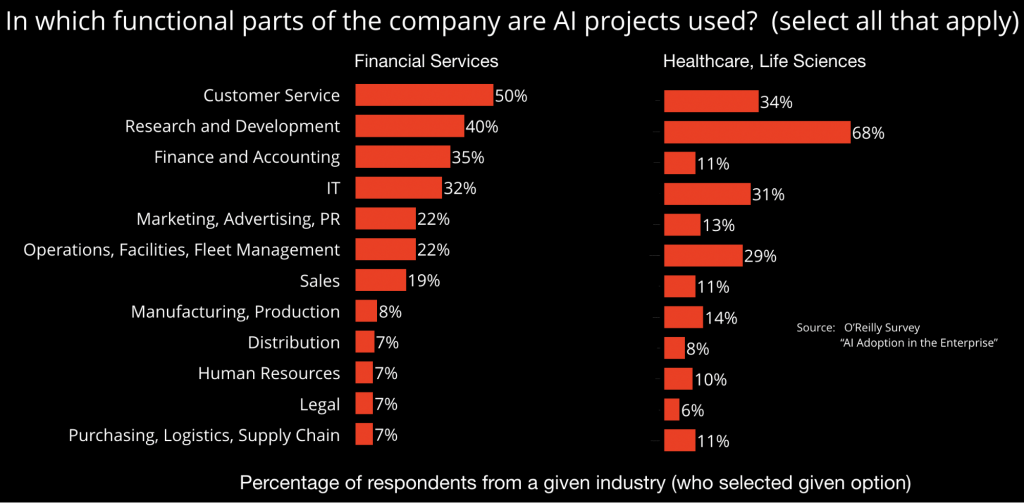
图2 在金融和医疗行业里的人工智能项目。图片来源:Ben Lorica
在2008年金融危机之后,美联储发布了一套新的监管模型指南——SR 11-7:《模型风险管理指南》。SR 11-7的目标是对一些早期规范进行扩展,并主要侧重于模型验证。虽然SR 11-7中没有任何令人惊讶的事情,但一旦企业和机构开始使用模型为重要的产品和服务提供能力,它就会提供出重要的需要考虑的因素。在本文的其余部分,我们将列出SR 11-7中涵盖的关键领域和建议,并解释它们如何与机器学习的最新发展相关。请注意,SR 11-7关注的重点是风险管理。
模型风险的来源
我们应该澄清的是SR 11-7还涵盖了未基于机器学习的模型,如“使用统计、经济、金融或数学理论、技术和假设来处理输入数据以进行定量估计的定量工具、系统或方法。”鉴于这一点,SR 11-7强调对模型的错误或不恰当使用就会导致很多潜在的模型风险来源,以及基本错误。机器学习开发人员正在开始关注更广泛的风险因素。在之前的文章中,我们列出了机器学习工程师和数据科学家可能需要管理的事情,例如歧视、隐私、安全性(包括针对模型的攻击)、可解释性,以及安全性和可靠性。
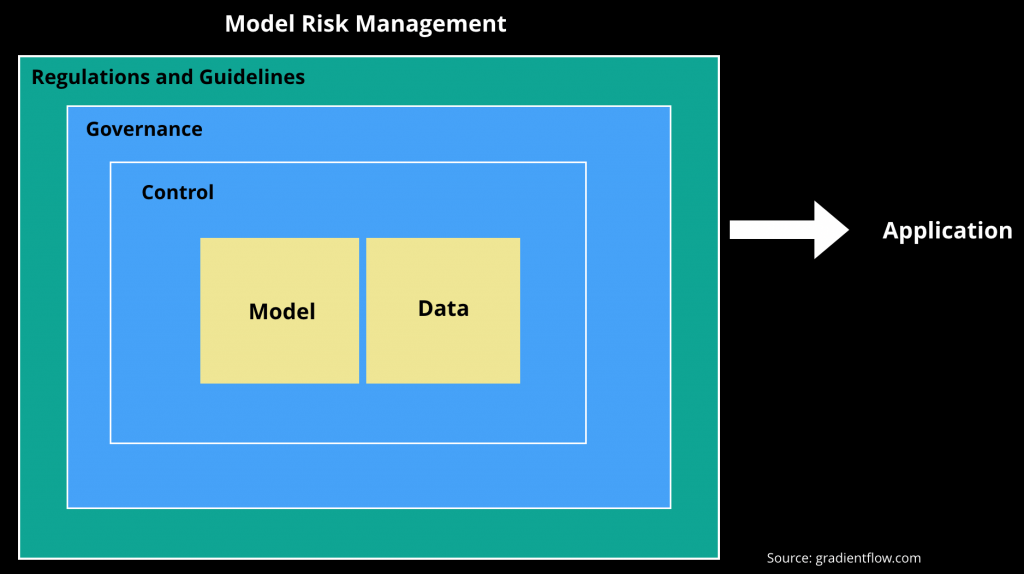
图3 模型风险管理。图片来源:Ben Lorica和Harish Doddi
模型开发和实施
SR 11-7的作者强调了有一个明确的意图说明的重要性,这样才能保证模型与其预期用途相一致。这与机器学习开发人员早已了解的理念是一致的:为特定应用构建和训练的模型很少可被(直接)用于其他场景。SR 11-7背后的监管机构也强调了数据的重要性,特别是数据质量、相关性和文档化。虽然各种模型在新闻报道里的覆盖率最高,但实际情况是数据仍然是大多数机器学习项目的主要瓶颈。鉴于到这些重要的因素,研究机构和初创公司正在开发构建专用于数据质量、治理和血缘的工具。开发人员还在构建可以实现模型复现性、协作和部分自动化的工具。
模型验证
SR 11-7对如何进行模型验证有一些具体的对企业和机构的建议。它的基本原则是:企业和机构需要由能够识别模型的局限性的合格团队进行批判性分析。首先,模型验证团队应该由不负责模型开发的人员组成。这与The Future of Privacy Forum和Immuta最近发布的报告中提出的建议类似(他们的报告是专门针对机器学习的)。其次,考虑到一般会倾向于展示和奖励模型构建者的工作而不是模型验证者的工作,应该有适当的权力、激励和补偿政策来奖励执行模型验证的团队。特别的,SR 11-7中引入了“有效挑战”的概念:
进行验证工作的员工应有明确的权力来挑战开发人员和用户,并向上级报告他们的发现,包括问题和缺陷。 ……有效挑战依赖于激励、能力和影响力的结合。
最后,SR 11-7建议制定流程来选择和验证第三方开发的模型。鉴于SaaS的兴起和开源研究原型的激增,这是一个与使用机器学习的企业和机构非常相关的问题。
模型监控
一旦把模型部署到生产环境中后,SR 11-7的作者强调了向决策者提供监控工具和有针对性的报告的重要性。这与我们最近提出的一些建议相一致,机器学习运维团队需要为所有的利益相关方(运维团队、机器学习工程师、数据科学家和管理者)提供可自定义视图的仪表盘。SR 11-7的作者还列举了需要建立独立的风险监控团队的另一个重要原因。作者指出,在某些情况下,挑战特定模型的动机可能是不对称的。根据企业和机构通常的奖励结构,某些团队不太可能挑战那些有助于提升其自身特定关键绩效指标(KPI)的模型。
管理、策略和控制
SR 11-7强调了维护一个模型的目录的重要性。该目录应该包含所有模型的完整信息,包括当前部署的、最近退役的和正在开发的模型。作者还强调文档应该足够详细,以便“不熟悉模型的各方可以理解模型如何运作,其局限性和关键假设”。这些内容是针对于机器学习的。同时对于机器学习生命周期开发和模型管理的早期工具和开源项目,需要补充有助于创建适当文档的工具。
对于已经开始在产品和服务中使用机器学习的企业和机构,SR 11-7的一部分还对可能有用的角色提出了具体建议:
- 模型所有者:他们会确保正确开发、部署和使用模型。在机器学习的世界中,这些人是数据科学家、机器学习工程师或其他专家。
- 风控人员:他们关注风险的测量、限制、监控和独立验证。在机器学习的语境里,他们可能是一个由领域专家、数据科学家和机器学习工程师组成的独立团队。
- 合规人员:他们确保有现成的具体流程供模型所有者和风控人员使用。
- 外部监管者:他们负责确保法规里的要求都被所有的商业机构正确地遵循了。
总体呈现
在许多案例里,看似做好准备的金融机构,由于没有恰当地考虑到模型的风险,从而没能及时发现一些流氓部门或流氓交易员。为此,SR 11-7建议金融机构不仅需要考虑单个模型的风险,还要考虑源于模型间交互和依赖性所带来的总体风险。许多机器学习团队还没有开始考虑用于管理同时部署多个模型所带来的风险的工具和流程,但很明显许多应用需要这种规划和思考。依赖于许多不同数据源、管道和模型(例如,自动驾驶汽车、智能建筑和智能城市)的新兴应用的创建者将需要有总体上的风险管理。新的数字原生公司(媒体、电子商务、金融等)非常依赖数据和机器学习,更需要有系统来单独和集成地监控多个机器学习模型。
医疗和其他行业
虽然这篇文章专注于为金融机构编写指南,但所有行业里的企业都将需要开发和制定管理模型风险的工具和流程。许多企业已经受到现有(GDPR)的和即将发布的(CCPA)的隐私法规的影响。而且如前所述,机器学习团队也已经开始构建工具来帮助检测歧视、保护隐私、防范针对模型的攻击以及确保模型的安全性和可靠性。
医疗行业是另一个受到高度监管的行业,这个行业里的人工智能正在迅速变化。今年早些时候,通过发布《基于人工智能/机器学习的软件作为医疗设备的修改建议监管框架》,美国FDA针对监管向前迈出了一大步。该文件开篇就指出“传统的医疗设备监管模式没有被设计用于自适应的人工智能/机器学习技术,这些技术有可能实时适应和优化设备性能,以持续改善患者的医疗保健。”
该文件接着提出了发展此类基于人工智能/机器学习的系统的风险管理框架和最佳实践。作为第一步,作者列出了那些会对用户产生影响的修改,以及由此带来的需要进行管理的内容:
- 对分析性能的修改(例如,模型的重新训练)
- 更改软件的输入
- 改变软件的预期用途。
FDA提出了一种需要不同监管机构批准的总的产品生命周期方法。对于上市前的系统,需要对安全性和有效性进行上市前认证。对于运行中的实时性能,必须要进行监控,以及做日志、跟踪和支持质量文化的其他流程,但不是每个变更都需要监管部门的批准。
该监管框架是相当新的,并已公示,以便在全面实施之前收集公众的反馈意见。不过它仍然缺乏对安全性和有效性的本地化测量要求,以及评估和消除歧视的要求。然而,这是通过明确的监管框架为医疗和生物技术开发快速增长的人工智能产业所迈出的重要的第一步,我们建议从业者在这个监管框架的演进过程中持续保持关注。
总结
每一个重要的新技术浪潮都会带来益处和挑战。管理机器学习中的风险是企业和机构需要越来越多解决的问题。来自美联储的SR 11-7包含许多建议和指南。这些建议和指南很好地对应着那些希望将机器学习集成到产品和服务中的企业的需求。
相关资源
- 《管理机器学习的风险》
- 《什么是模型管理和模型运维?》
- 《成为一个机器学习企业意味着对基础技术的投资》
- 《对高质量数据的要求》
- Andrew Burt和Steven Touw所写的《企业如何管理那些它们无法完全解释的模型》
- David Talby所写的《在调优机器学习模型成为真正的产品和服务过程中学到的经验教训》
- Ira Cohen所写的《应用机器学习来获取关于机器学习算法的洞察》
- 《你开发了一个机器学习的应用。现在需要确保它是安全的》
- Jike Chong所写的《金融服务业里的数据科学和机器学习的应用》
- Gary Kazantsev所写的《数据科学是如何对华尔街带来影响的》





