随着企业开始进行人工智能技术的探索,三个特定的领域引起了很多关注:计算机视觉、自然语言应用和语音技术。世界知识产权局(WIPO)最近的一份报告发现,这三个领域的专利占了人工智能相关专利的大部分:计算机视觉占49%,自然语言处理(NLP)占14%,语音技术占13%。
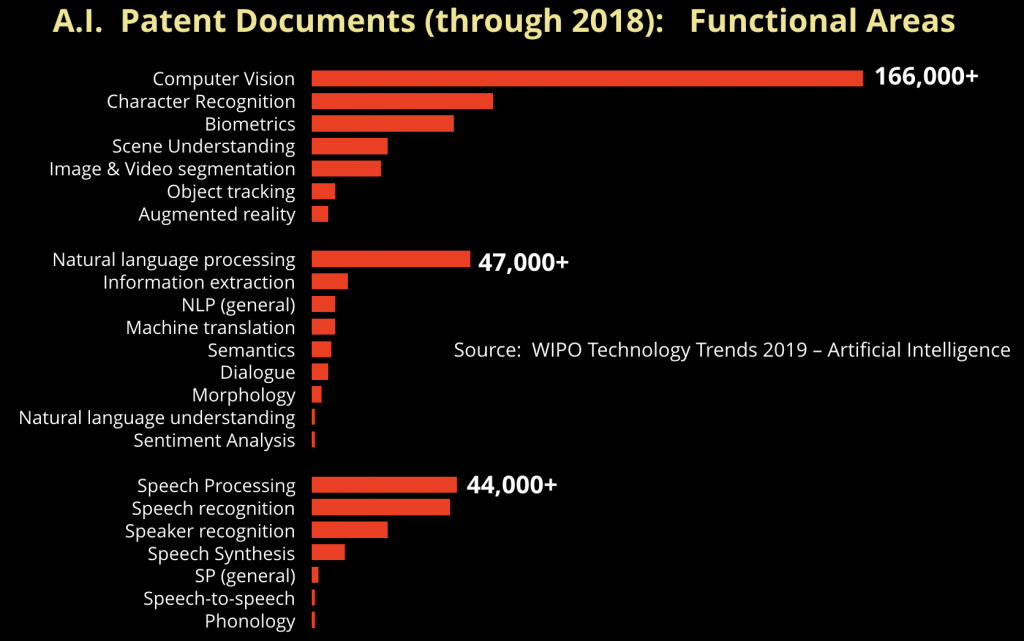
图1 世界知识产权局2019年的研究显示了几个关键领域的专利发表情况。图片来源:Ben Lorica
企业里有很多非结构化和半结构化的文本数据,而很多公司已经拥有了NLP和文本分析的经验。虽然比较少的公司拥有收集和存储图像或视频的基础设施,但计算机视觉是许多公司开始探索的领域。深度学习和其他技术的兴起促使初创公司商业化了一些计算机视觉的应用,包括安防和合规、媒体和广告以及内容生成。
一些企业也在探索话音和语音的应用。自然语言和语音模型的最新进步提升了准确性,从而开辟出了一些新的应用。在企业语音应用方面,呼叫中心、销售和客户支持以及个人助理等应用处于领先地位。在消费者应用方面,语音搜索、智能音箱和数字助理正越来越普及。虽然远非完美,但目前这一代话音和语音应用已经足够得好,从而推动了语音应用的爆炸性增长。语音技术的潜力的一个早期线索是语音驱动的搜索的增长。Comscore估计,到2020年,大约一半的在线搜索将使用语音。Gartner建议企业重新设计其网站,以支持视觉和语音搜索。此外,从2018年到2019年,智能音箱预计将增长82%以上。到今年年底,此类设备的安装数将超过2亿台。
图2 语音交互的类型。图片来源:Yishay Carmiel和Ben Lorica
音频内容数据也正在呈现爆炸式的增长。这就需要使用语音技术进行搜索和挖掘,从而能解锁这些新内容。例如,根据《纽约时报》最近的一篇文章,在美国“每个月中大概有三分之一的人会至少收听一次播客”。播客节目的增长并不仅限于美国,包括中国在内的世界各地的播客量都在增加。
语音和对话应用是有挑战性的
在文本和NLP或计算机视觉领域里,程序员可以简单地开发出一个应用。但语音应用(不是简单的语音命令)对许多企业来说仍然具有挑战性。口语比书面文字有更多的“噪音”。例如,在阅读了许多播客脚本后,我们可以证明语音对话的脚本仍然需要大量的编辑工作。即使你可以获得最好的转录(语音到文本)技术,你也通常也会看到一个包含暂停、填充、重启、插话(在对话的场景里)和不合语法结构的句子的脚本数据。脚本还可能包含需要改进的段落,因为有人可能“在开脑洞”或难以准确地表达特定的观点。此外,由转录产生的脚本可能无有在正确的位置打标点或进行大写处理。因此,在许多应用中,脚本的后处理就需要人类编辑参与。
在计算机视觉(现在是NLP)中,我们已经处于数据至少与算法同等重要的阶段。 具体而言,预先训练的模型已经在计算机视觉和NLP的若干任务中提供了最好的性能。那么语音领域怎么样?“一个模型能满足所有的”语音模型没能出现的原因有下述几个:
- 存在各种声学环境和背景噪音:室内或室外、在汽车里、在仓库里或在家庭等。
- 可能需要支持多种语言(英语、西班牙语、中文普通话等),特别是在说话人在对话过程中使用(或混用)多种语言的情况下。
- 应用类型(如搜索、个人助理等)会影响对话流程和词汇表。
- 根据应用的复杂程度,需要针对特定领域和主题来调整语言模型和词汇。这一点对于文本和自然语言应用也成立。
构建语音应用
尽管存在挑战,但正如前面我们所指出的那样,语音技术和语音应用已经出现了相当多的让人激动的内容。虽然我们尚未达到可以使用通用解决方案为各种语音应用“供电”的阶段,同时也没有能够跨多个领域的语音智能助理。
然而,已经有一些很好的基础模块可以被用来组装有趣的语音应用。为了帮助正在探索使用语音技术的公司,我们整理了以下指南:
- 集中你的注意力。正如我们所指出的那样,当前一代语音技术无法实现“一个模型能满足所有的”场景。因此最好将重点放在特定任务、某种语言和某个领域。
- 理解应用想要实现的目标,然后再去看所需要的技术类型。如果你能知道应用的KPI,那么就可以使用这些KPI来找到为特定应用领域实现这些度量标准所需要的语言模型。
- 在“真实数据和真实场景”里进行实验。如果你计划开始使用现成的模型和服务,请注意“真实数据和真实场景”的重要性。在许多情况下,初始测试数据并不能代表用户与想部署的系统进行交互的方式。
- 获取每个特定任务的标记样本。例如,识别英语中的“cat”和中文普通话中的“猫”将需要不同的模型和不同的标记数据。
- 制定数据采集策略以保证收集到合适的数据。确保构建的系统可以随着收集到更多的数据而持续学习,以及制定一个支持持续改进的迭代流程。
- 语音应用的用户关心的是结果。语音模型只有在推导出洞察力并使用这些洞察力而采取行动时才有意义。例如,如果用户要求智能音箱播放特定的歌曲,那么对该用户唯一重要的就是音箱能播放那首歌曲。
图3 模型应该被用来推导出洞察。图片来源:Yishay Carmiel和Ben Lorica
- 自动化工作流程。理想情况下,所需的字典和语音模型可以在没有太多干预(来自机器学习或语音技术专家)的情况下进行更新。
- 语音应用是复杂的端到端系统,因此要尽可能地进行优化。单单一个语音识别系统就是由我们在前一篇文章中描述的多个模块所组成。训练和再训练模型的代价可能很高。根据应用和场景,延迟和持续连接也是重要的考虑因素。
从NLU到SLU
我们仍处于企业级语音应用的早期阶段。在过去的12个月中,我们看到预训练的自然语言模型取得了快速进展,这些模型在多个NLP基准测试中创造了新记录。开发人员开始采用这些语言模型,并针对特定领域和应用对它们进行微调。
对AI应用来说,语音数据又增加了另一层的复杂性,它超越了自然语言理解(NLU)。口语理解(SLU)需要能够从口语中提取含义。虽然SLU还没有被用于语言或语音应用,但好消息是,已经可以使用现有的SLU模型构建简单、特定用途的语音应用。为了找到正确的应用场合,企业需要了解当前技术和算法的局限性。
与此同时,我们将会一步一步地进行。正如Alan Nichol在一篇关注基于文本的应用的博文中指出的那样,“聊天机器人只是实现真正的AI助手和自动组织的第一步。”同样地,今天的语音应用揭开了即将发生的事情的一角。
相关内容:
- “文本分析 101:深度学习和注意力网络一路走向生产系统”,在人工智能伦敦大会上的一个新的教学议程。
- 《深度学习正革命化对话人工智能》
- 《企业里的下一代人工智能助手》
- Yishay Camiel的《在大数据和深度学习时代的商业化语音识别系统》
- 《在医疗领域构建自然语言处理系统的经验教训》
- Alan Nichol的《使用机器学习来改进对话应用中的对话流程》
- 《一张简单的幻灯片:谁对Spark NLP感兴趣?》
- Ihab Ilyas和Ben Lorica的《对高质量数据的需求》







