2016年7月我向朋友David Talby提出了构建一个针对Apache Spark用户的NLP库的想法。一年多后,Talby和他的合作者发布了Spark NLP。在发布公告、Talby和我撰写的播客以及最近发表的对流行的开源NLP库进行比较的博文中,他们介绍了这个项目背后的动机。(信息披露:我是Databricks的顾问,Databricks是Apache Spark团队创建的初创公司。)
在该项目两周年即将来临之际,我向Talby询问了主要是谁对该项目感兴趣,他慷慨地分享了项目主页访问者的地理人口统计数据。
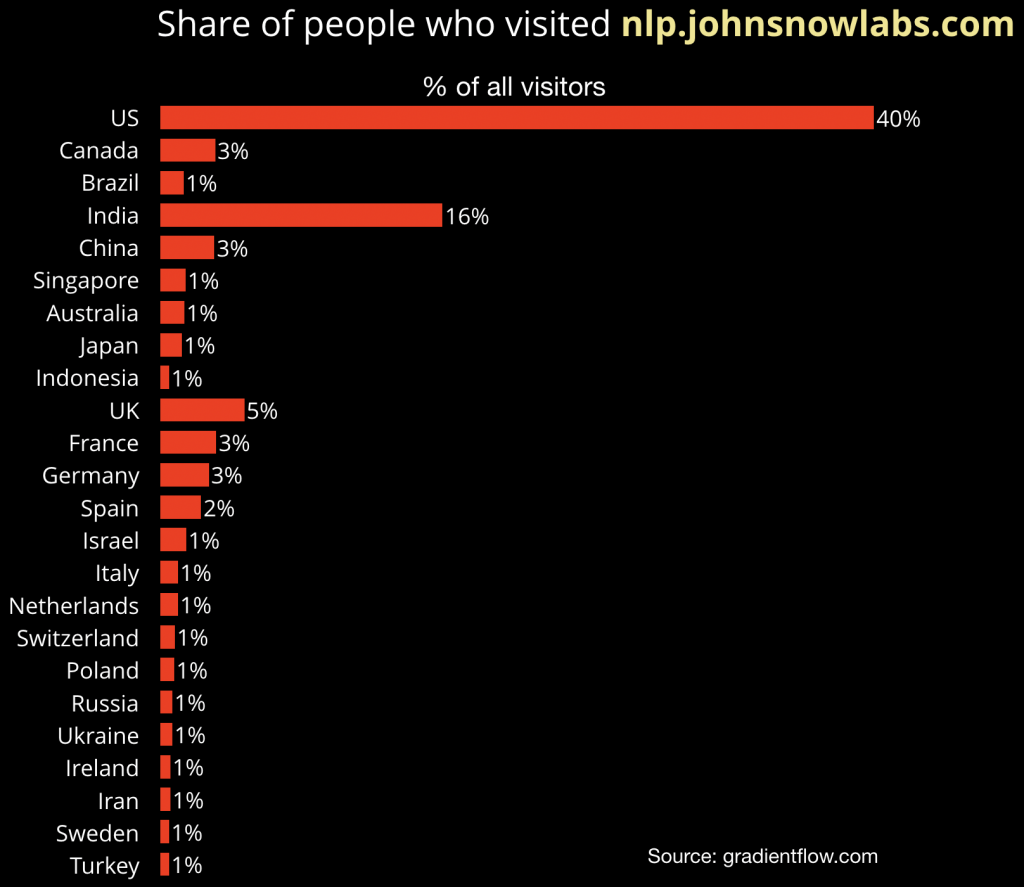
图1 Spark NLP网站访客的地理人口统计数据。 幻灯片由Ben Lorica制作,数据由David Talby友情提供
在该网站的数千名访问者中,44%来自美洲,24%来自亚太地区,22%来自欧洲、中东和非洲地区。
许多访问者正在转变为该项目的用户。在我们最近的企业人工智能应用调查中,不少受访者表示他们正在尝试Spark NLP。基于Strata数据大会与会者的投票,该项目还获得了3月份Strata数据奖项中的开源类别的最高奖。
有许多其他优秀的开源NLP库,它们也拥有大量用户,如spaCy、OpenNLP、Stanford CoreNLP和NLTK等。但在Spark NLP项目启动时,它显然是吸引了那些已经拥有Spark集群(并且需要可扩展的NLP解决方案)的用户。虽然该项目刚开始是针对于Apache Spark的用户,但它现在已经发展到通过简单的API,只需几行代码就可以完成工作,并且完全隐藏了Spark。这个库的Python API接口现在拥有最多的用户。安装Spark NLP对于Python就是使用pip或conda的一行命令的操作,或使用maven、sbt或spark-package在Java或Scala上执行的一个依赖包添加操作。Spark NLP库的文档也在不断增加,还出现了一些公共在线示例,可用于如情感分析、命名实体识别和拼写检查等常见的任务。文档的改进、易用性以及重要的深度学习模型的生产级实现,结合它的速度、可扩展性和准确性,使得Spark NLP成为需要NLP库的企业的一个不错的选择方案。
想了解更多关于Spark NLP的信息,请关注于2019年9月23至26日在纽约市举行的Strata数据大会上,David Talby和他的同事举办的3小时的教学辅导课“使用Spark NLP 进行大规模自然语言理解”。最优惠价格截止于6月28日。
相关内容:
- 《在医疗领域构建自然语言处理系统的经验教训》
- 三部曲系列的《比较生产级的NLP库》
- 《对开源NLP库的功能性比较》

Ben Lorica
Ben Lorica是O'Reilly Media,Inc.的首席数据科学家,也是Strata数据会议和人工智能会议的日程主管。 他将商业智能,数据挖掘,机器学习和统计分析应用到各种环境中去,包括直接营销,消费者和市场研究,目标广告,文本挖掘和金融工程。 他的工作背景包括投资管理公司,互联网创业公司和金融服务公司。





