在这篇文章中,我分享今年早些时候我在伦敦的Strata数据会议上发表主题演讲的幻灯片。我将重点介绍最近一项关于机器学习被采纳情况的调查结果,并描述公司内部数据和机器学习的最新趋势。现在是评估企业活动的好时机,有许多迹象表明大量公司已经开始使用机器学习。例如,在2018年7月的这份调查吸引了超过11000名受访者,我们发现公司有很强的参与感:51%的公司表示他们已经在生产环境中使用了机器学习模型。
随着围绕人工智能的过度宣传,人们很容易跳入涉及您不熟悉的数据类型的坑中。我们发现,那些成功利用机器学习的公司,要么把机器学习建立在现有数据产品和服务的基础上,要么更新现有模型和算法来实现对当前业务的支持。以下是一些组织开始使用机器学习的典型方式:
- 建立在现有数据分析用例的基础上:例如,可以将现有数据源用于商业智能和分析,并在机器学习程序中使用它们。
- 更新现有应用程序,如推荐系统、搜索排名、时间序列预测等。
- 使用机器学习解锁对新的数据类型的分析,这些数据类型包括图像、音频、视频。
- 处理全新的用例和应用。
以深度学习为例,这是一种特殊形式的机器学习,在2011/2012年因语音和计算机视觉的创纪录模型而重新出现。当我们继续阅读语音和计算机视觉方面令人印象深刻的突破时,公司开始使用深度学习来扩充或取代现有的模型和算法。著名的例子是谷歌的机器翻译系统,它从“以统计为核心”的方法转移到了使用TensorFlow来做。在我们自己的会议中,我们看到了人民对时间序列和自然语言处理的深度学习培训课程/教程的浓厚兴趣,这两个领域里,公司可能已经有了现有的解决方案,深度学习也开始显示出一些希望。
机器学习不仅出现在更多的产品和系统中,而且正如我们在之前一篇文章,机器学习也将改变应用程序本身在未来的构建方式。开发人员会发现自己越来越多地构建具有机器学习元素的软件。因此,许多开发人员需要整理数据,训练模型,并分析模型的结果。话虽如此,我们仍然处在一个高度经验主义的时代:我们需要大数据、大模型和大计算机。
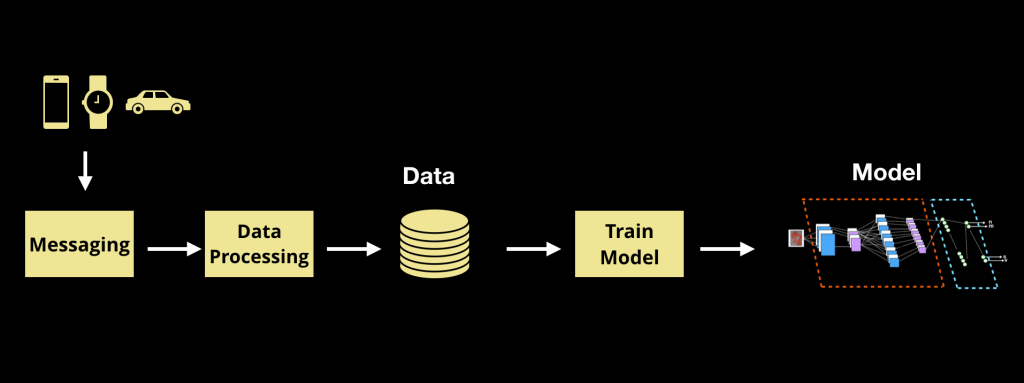
图1 一种典型的机器学习数据管线。资料来源:O’Reilly
不得不提到,深度学习模型比数据科学家先前最青睐算法更需要大量数据。数据是机器学习应用程序的关键,让数据流动、被清洗、并以可用的形式出现,将是维持机器学习实践的关键。
着眼于机器学习日益增长的重要性,我们最近完成了数据基础设施调查,这个调查吸引了超过3200受访者。我们的目标有两个:(1)找出人们在使用什么工具和平台,以及(2)确定公司是否正在构建维护机器学习项目所必须的基础工具。许多受访者表示他们正在使用开源工具(Apache Spark、Kafka、TensorFlow、PyTorch等)。)和云中的托管服务。
我们问的一个主要问题是:你目前正在构建或评估什么技术?
- 毫不奇怪,数据集成和ETL名列前茅,60%的受访者目前正在构建或评估该领域的解决方案。在一个数据渴求算法的时代,一切都真正从收集和汇总数据开始。
- 让您的数据为机器学习做好准备的一个重要部分,是对其进行规范化、标准化,并使用其他数据源对其进行扩充。52%的受访者表示,他们正在构建或评估数据准备和清理解决方案。这些工具包括用于数据准备的Human-In-The-Loop系统:这些工具允许领域专家训练自动化系统进行大规模的数据准备和清理。事实上,有一个令人兴奋的新研究领域叫做数据编程,它统一了训练集的程序化创建技术。
- 您还需要能够让您了解您拥有哪些数据,以及谁可以访问这些数据的解决方案。调查中约三分之一的受访者表示他们对数据治理系统和数据目录感兴趣。一些公司开始构建自己的解决方案,一些公司将在今年秋天在纽约的地层数据上展示它们,例如,Marquez和DataBook(Uber)。同时初创公司——Alation、Immuta、Okera等公司也在相同领域开发有趣的产品。
- 21%的受访者表示,他们正在构建或评估数据谱系解决方案。过去,我们对数据源的态度很随意。关于数据伦理、隐私和安全的讨论已经让数据科学家意识到数据谱系和来源的重要性。具体来说,公司需要知道数据来自哪里,数据是如何收集的,以及数据是如何被修改的。审计或复制ML管线的需求日益成为一个法律和安全问题。幸运的是,我们开始看到开源项目(包括DVC, Pachyderm, Delta Lake, DOLT)解决了对数据谱系和来源的需求。在最近的会议上,我们还与建立了数据谱系系统的公司进行了会谈——Intuit、Lyft、Accenture、NetFlix等公司,更多关于数据治理/谱系的系统将于今年秋天在纽约Strata 数据会议上一起展示。
- 随着组织内数据科学家和机器学习工程师数量的增长,工具必须标准化,模型和特征需要共享,需要开始引入自动化流程。58%的受访者表示他们正在构建或评估数据科学平台。我们的Strata数据会议持续举行几次会议,讨论公司如何构建内部数据科学平台,特别是他们做出了哪些权衡、选择了哪些设计,以及在此过程中吸取了哪些经验教训。
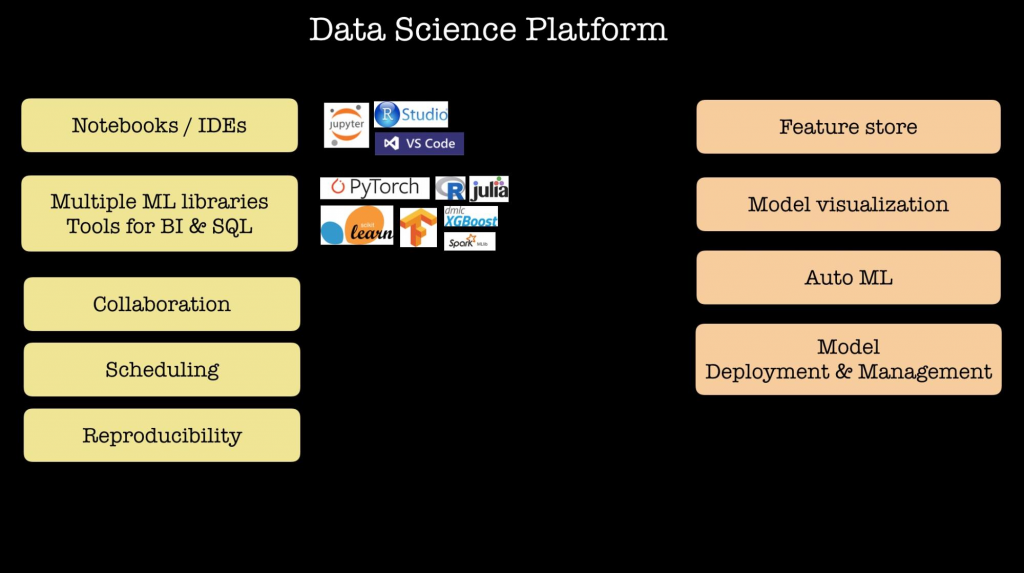
图2 许多数据科学平台的关键特性。资料来源:O’Reilly
那么云服务呢?在我们最近的调查中,我们发现大多数人已经在部分数据基础设施中使用公共云服务,超过三分之一的人一直在使用serverless(无服务器技术)。我们在最近的会议上已经举办了许多关serverless的培训课程、辅导课和讲座,包括Eric Jonas讨论UCBerkeley最近一篇关于serverless论文的演讲,还有一个Avner Braverman的讲座,阐述了serverless在人工智能和数据应用中的作用。
公司刚刚开始构建机器学习应用程序,我相信机器学习的应用将在未来几年继续增长,原因如下:
- 5G正开始推出,5G将导致机器对机器应用程序的发展,其中许多应用程序将包含机器学习。
- 机器学习(特别是深度学习)的专用硬件将上线:我们已经看到了用于边缘设备和服务器模型推断的新硬件。在2019年第三季度/第四季度左右,用于训练深度学习模型的专用硬件将会推出。想象一下让数据科学家和机器学习专家以很少的成本和时间运行实验的系统。这种用于机器学习训练和推理的新一代专用硬件将允许数据科学家探索和部署许多新类型的模型。
有几个早期的迹象表明机器学习将继续在公司内部发展,这两个迹象都表明越来越多的公司对机器学习感兴趣。首先,几年前当我们在媒体上已经读到大量关于数据科学家的文章时,一个致力于机器学习进入生产环境的新岗位才刚开始出现。
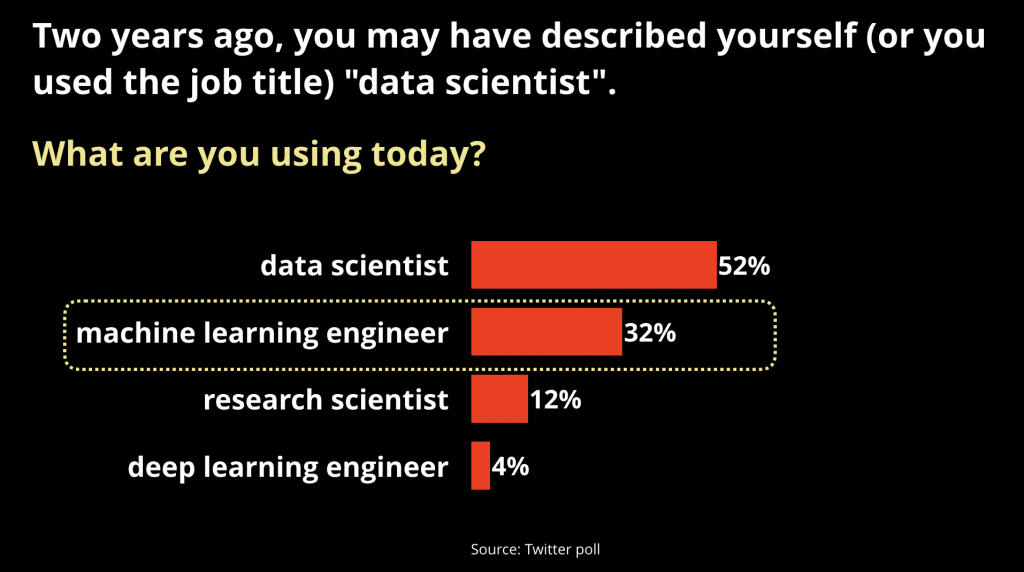
图3 数据来自推特的投票。资料来源:O’Reilly
机器学习工程师介于数据科学和工程运维之间,他们的工资往往比数据科学家高,而且他们通常拥有更强的技术和编程技能。正如我在推特上的投票调查显示的那样,似乎有早期迹象表明数据科学家正在将自己为符合这个新岗位进行“重塑”。

图4 像MLflow这样的模型开发工具正在流行起来。资料来源:O’Reilly
另一个机器学习兴起的信号是,有一些像MLflow这样具有很大吸引力的新项目。在它推出后的大约10个月内,我们已经看到许多公司对此很感兴趣。正如我们在最近一篇文章中提到的,MLflow的一个常见用例是实验跟踪和管理—在MLflow出现之前,还没有好的开源工具。MLflow和Kubeflow等项目(以及comet.ml和Verta.AI等公司的产品)使机器学习的开发更容易管理。
MLflow是一个有趣的新工具,但是它专注于模型开发。随着您的机器学习实践扩展到组织的许多部分,很明显您将需要其他专门的工具。在与许多已经为机器学习构建了数据平台和基础设施的公司交谈时,出现了一些在设计工具链时必须考虑的重要因素:
- 支持不同的建模方法和工具:虽然深度学习变得更加重要,但事实是,即使是领先的技术公司也使用各种建模方法,包括SVM、XGboost和统计学习方法。
- 模型训练的持续时间和训练频率会有所不同,这取决于用例、数据量和所使用的特定算法类型。
- 具体应用中涉及到多少模型推理?

图5 设计您的移动语言平台时的重要注意事项。资料来源:O’Reilly
正如数据是需要专门工具(包括数据治理解决方案和数据目录)管理的资产一样,模型也是需要管理和保护的宝贵资产。正如我们在之前一篇文章提到的,模型管理和模型维护工具也将变得越来越重要:机器学习民主化的下一个重要步骤是使其更易于管理。模型治理和模型维护将需要包含以下项目的解决方案:
- 用于授权和安全的数据库:谁对某些模型具有读/写权限
- 列出模型的目录或数据库,包括模型的测试、训练和部署时间
- 审计所需的元数据和中间组件
- 用于部署、监控和警报的系统:谁批准模型将其推到生产环境,谁能够监控其性能并接收警报,以及谁对此负责
- 为各种主体(运维部门、机器学习工程师、数据科学家、企业主)提供自定义视图的仪表板
公司正在了解到,随着机器学习使用的兴起,随之而来的是有许多重要的需要考虑的方面。万幸的是,研究团体已经开始推出技术和工具来解决机器学习提出的一些重要挑战,包括公平性、可解释性、安全性和可靠性,尤其是安全性和隐私性。机器学习经常与用户互动并影响用户,因此公司不仅需要制定流程,让他们负责任地部署机器学习,还需要构建基础技术,让他们保持对模型的监督,尤其是在出现问题时更是如此。我上面提到的技术——数据治理、数据谱系、模型治理——都将有助于管理这些风险。特别是,审计和测试机器学习系统将依赖于我上面描述的许多工具。
风险和考虑是真实存在的,而不仅仅是只存在于理论中。这些基本工具将越来越重要,不再可有可无。例如,最近一个DLA Piper调查提供了向监管机构报告的GDPR违规事件的估计:截至2019年2月,有超过59000起个人数据违规滥用事件。
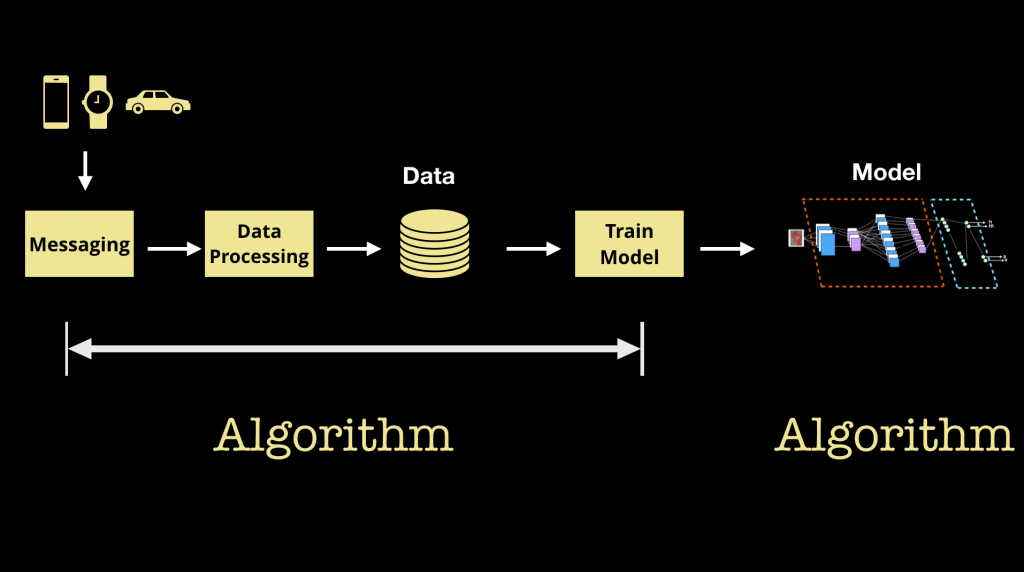
图6 机器学习涉及一系列相关的算法。资料来源:O'Reilly
虽然我们倾向于认为机器学习产生一个我们部署的“模型”或“算法”,但是审计机器学习系统可能是一项挑战,因为实际上有两种算法需要跟踪:
- 在产品应用中部署和使用的实际模型
- 使用数据来产生最优化某些目标函数的模型的算法(“训练优化器”和“数据管线”)。
因此,管理机器学习意味着构建一套工具来管理一系列相关的算法。基于我在上面描述的调查结果,公司开始构建重要的基础技术——数据集成和ETL、数据治理和数据目录、数据谱系、模型开发和模型治理——这些对于维持负责任的机器学习实践非常重要。
但是挑战依然存在,尤其是那些公司,在不得不应付大量信息技术、软件和云解决方案( 管理“保持灯光常亮”这种基本任务除外)的同时,机器学习的使用还在增加。好消息是,有早期迹象表明,公司开始认识到,构建或获取必要的基础技术是必须的。
相关资源:
- “在企业中持续进行机器学习”
- “用于机器学习开发和模型治理的专用工具变得至关重要”
- “机器学习中的风险管理”
- “什么是机器学习工程师?”: 一种专注于创建数据产品,使数据科学在生产中发挥作用的新岗位
- “机器学习对软件开发而言意味着什么”
- “机器学习中的深度自动化”
- “在实践中,什么是硬核数据科学?”:将数据科学引入生产环境的架构剖析
- “将机器学习模型转化为真实产品和服务时,所获得的经验教训”

Ben Lorica
Ben Lorica是O'Reilly Media, Inc. 的首席数据科学家,也是Strata数据会议和人工智能会议的日程主管。 他在各种场景中应用了商业智能,数据挖掘,机器学习和统计分析,这些场景包括:直销,消费者和市场研究,精准广告,文本挖掘和金融工程。 他的背景涵盖了投资管理公司,互联网创业公司和金融服务公司。





