几年前我们开始发布文章(参见本文末尾的“相关资源”),了解数据团队开始接受更多机器学习(ML)项目时所面临的挑战。 在此过程中, 我们描述了一个新的工作角色/岗位: 机器学习工程师,其专注于创建数据产品,并使数据科学在生产环境中发挥作用,这一角色在两年前开始在旧金山湾区出现。 当时,没有任何流行的工具可以解决机器学习落地团队所面临的问题。
大约10个月前,Databricks发布了MLflow,这是一个用于管理机器学习开发的新开源项目(完全披露利益相关:Ben Lorica是Databricks的顾问)。 我们认为,由于缺乏明确的开源竞品替代方案,MLflow有很大的机会吸引用户使用,事实证明情况确实如此。 在相对较短的时间内,MLflow在GitHub上获得了超过3,300颗星,来自40多家公司有80多名工程师成为了代码贡献者。 最重要的是,超过200家公司正在使用MLflow。
那么,为什么这个新的开源项目会引起数据科学家和机器学习工程师的共鸣呢? 回想一下机器学习项目的关键属性:
- 与目标是满足功能参数的传统软件不同,在机器学习中,我们的目标是优化指标。
- 质量不仅取决于代码,还取决于数据,优化方法,定期更新和重新训练。
- 参与机器学习的人通常希望尝试新的库,算法和数据源 – 因此,必须能够将这些新组件投入生产环境。
MLflow的成功可归功于轻量级的“开放式界面”,允许用户连接他们喜爱的机器学习库,以及用户可以选择的三个组件的可用性(即,他们可以使用其中的一个,两个或全部三个):
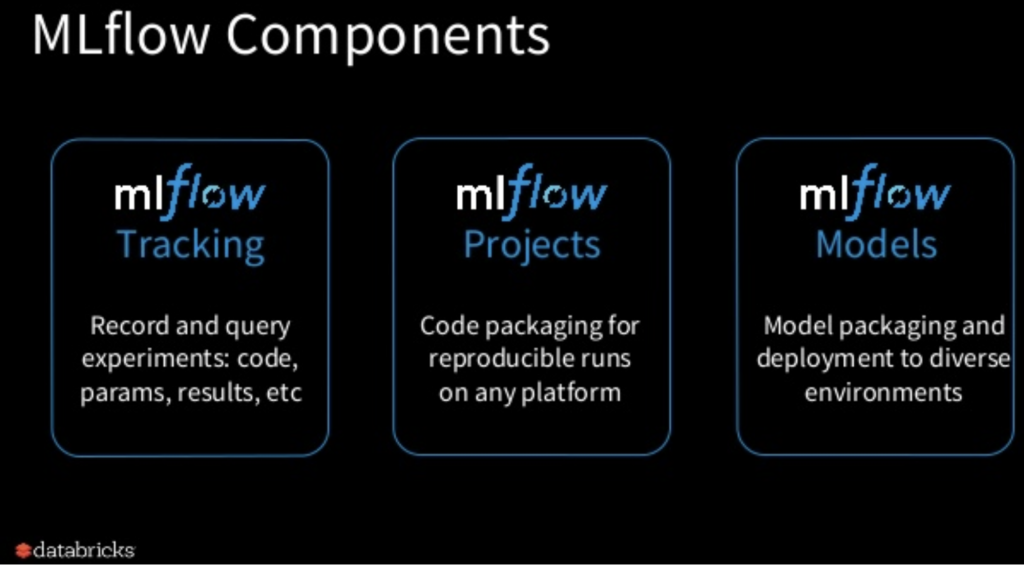
图1. Matei Zaharia提供图片,经许可使用
事实上,人们可以按需选择任意MLflow组件,意味着项目能够快速满足各种用户的需求。 根据我们对MLflow用户正在进行的调查,以下是一些最常用的用例:
- 跟踪和管理大量机器学习实验:MLflow对于跟踪他/她自己的实验的个别数据科学家非常有用,但它也被设计用于拥有大型机器学习开发团队的公司,他们使用它来跟踪数千个莫O型。
- MLflow用于管理多阶段的机器学习管线。
- 模型封装:公司正在使用MLflow将自定义逻辑和依赖关系作为模型包抽象的一部分,然后再将其部署到生产环境中(例如:推荐系统可能被硬编码为,不向未成年人显示某些图像)。
即将发布的0.9.0版本具有许多新功能,包括支持MLflow跟踪服务器的数据库存储,这将使大型团队更容易查询和跟踪正在进行的和过去的实验。
我们仍处于支持团队开发机器学习模型的工具的早期阶段。 除了MLflow之外,像Comet.ml和Verta.ai这样的初创公司正在构建工具来缓解类似的痛点。 随着软件开发在未来几年开始倾向于变得像ML开发,我们期望看到更多在基础工具上的投入。
模型治理
公司需要认真研究开发机器学习模型的改进工具,这些工具是更有野心的工具套件的一部分。 机器学习不仅限于拥有博士学位的研究人员; 人手远远不够。
机器学习正处于民主化的过程中; 让软件开发人员能够使用工具构建和训练模型对于民主化进程至关重要。
我们还说过,在生产环境中部署的机器学习模型数量将急剧增加:许多应用程序将由许多模型构建,许多公司将希望自动化其业务的方方面面。 这些模型将会因太旧而失效,需要定期重新训练。 我们已经习惯于数据治理、数据来源管理,理解和控制流行“数据驱动类应用”的数据库。 我们现在也意识到,对模型而言也是如此。 公司需要跟踪他们正在建造的模型以及他们在生产中的模型。
像Datatron这样的初创公司开始使用术语“模型治理”来描述跟踪和管理模型的任务,他们开始在产品套件中构建模型治理工具。 该术语描述了企业和大公司开始使用的流程,这样能够了解团队正在开展的许多ML计划和项目。 监管机构也表示,他们对构建在人工智能和机器学习之上的产品感兴趣,因此管理ML开发的系统将需要遵守未来的法规。 以下是一些将在构建模型治理解决方案中发挥作用的要素:
- 管理授权/安全性的数据库:谁具有对某些模型的读/写访问权限
- 模型的目录/数据库:包括测试,训练和部署模型的时间
- 审计所需的元数据和中间件:例如,MLflow组件的输出与审计非常相关
- 用于部署,监控和警报的系统:谁批准并将模型推向生产,谁能够监控其性能并接收警报,以及谁对模型负责
- 一个仪表板,为所有主体(操作,ML工程师,数据科学家,企业主)提供自定义视图
传统软件开发人员长期以来一直有管理项目的工具。 这些工具提供版本控制,库管理,部署自动化等功能。 机器学习工程师知道并使用所有这些工具,但这些工具还不够。 我们开始看到适合提供机器学习工程师所需功能的工具,包括模型治理,跟踪实验和打包模型的工具,以便结果可重复。 机器学习民主化的下一个重要步骤是使其更加易于管理:不仅仅是手工制作解决方案,还有使机器学习在企业级规模上可管理、可部署的解决方案。
相关资源
- “什么是机器学习工程师?” :一个新的角色,专注于创建数据产品和使数据科学在生产中工作
- “机器学习对软件开发意味着什么”
- “机器学习中的深度自动化”
- “什么是硬核的数据科学实践?” :将数据科学投入生产的架构解剖
- “从机器学习模型转化为真实的产品和服务过程中获得的经验教训”
- Harish Doddi谈“简化机器学习生命周期管理”
- Jesse Anderson和Paco Nathan撰写“机器学习工程师需要了解的内容”
- “数据工程师与数据科学家”







