在之前的一篇博文里我介绍了在首次Ray聚会里出现的一些早期Ray的应用场景。Ray是由加州大学伯克利分校的RISE实验室开发的一个分布式计算框架。第二次Ray聚会在几个月后举行。在这两次聚会上都可以看到一些使用Ray构建的早期应用。在Ray自身的开发层面,它的核心API已经稳定下来,并且很多工作都致力于提升和改进Ray的性能和稳定性。现在在GitHub上Ray项目已经得到了5700颗星,吸引了来自多个机构的100多名贡献者。
在现阶段,应该如何向一个不熟悉Ray的人介绍它?RISE实验室的成员把Ray描述成一个“面向集群或云环境编程的通用框架”。把这个项目放到上下文里看,Ray和云功能(比如FaaS和Serverless)目前处于极度灵活的系统和更聚焦、强调易用性这两个极端的中间。更确切的说,一方面,目前用户可以利用极度灵活的集群管理和虚拟化工具,如Docker、Kubernete、Mesos等;另一方面,可以利用领域专用的灵活的系统,如Spark、Kafka、Flink、PyTorch、TensorFlow、Redshift等。
实践上这些是怎么实现的?Ray对于无状态和有状态的计算都支持,也支持调度里面的细粒度控制,允许用户在其上面实现多种多样的服务和应用。

图1 可以构建在Ray之上的库的例子。来源:Robert Nishihara和Philipp Moritz授权使用
基于Ray之上的库已经出现了,例如:RLib(可扩展的强化学习库)、Tune(一个超参数优化的框架),以及很快就会发布的一个流计算库等。如下面介绍的,我认为更多的库将会出现。
上面所说的库都很好,但是大部分的开发人员、数据科学家和研究人员不必也不会开发库。他们对直接能使用的库更感兴趣。如果你是一个使用Python的数据科学家或开发人员,下面是一些你应该研究一下Ray的原因:
- Modin库:这个库可以让你只修改一行代码就能扩展pandas工作流。鉴于大部分数据科学家已经喜欢使用pandas,Modin库是扩展和加速你已有代码的一个极度简单的方法。
- 易扩展的数据科学:还没有被充分注意到的是Ray为Python使用者提供了一个简单的并行运行他们代码的方法。在最近的加州大学伯克利分校的《数据科学100》课程里,Ray是分布式计算内容的核心。这个课程是由Jupyter的一个发明人参与教学的。
- 强化学习(RL):强化学习是数据科学家开始探索的课题之一。但是就如很多机器学习使用者利用了已有的机器学习库(例如scikit-learn)一样,大部分强化学习的使用者不会自己从零开始编写相关的库。好消息是RLib为不同类型的强化学习训练提供了统一的API接口,而且所有RLib的算法都是分布式的。因此强化学习的使用者和研究人员都可以从RLib里获益。
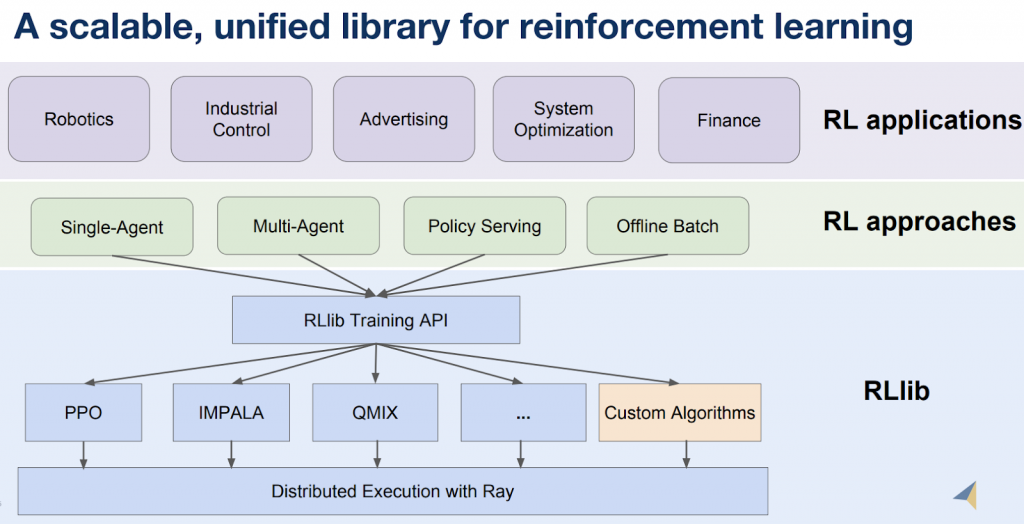
图2 Ray和强化学习。来源:Eric Liang授权使用
- 自动机器学习(AutoML):在近期的一篇博文里随着模型构建成为一个重要的组件,我介绍了一些自动化机器学习项目的不同阶段的工具。Ray的使用者已经在利用Tune这一易扩展的超参数优化工具。超参数调优是一个非常重要且常见的机器学习模型探索和构建的步骤。也已经有了一些使用Ray的自动机器学习的项目,有希望其中的一些会在近期被开源发布出来。
那么具体的Ray的使用案例有哪些?贡献者的增加以及库和工具的增多,这些都带来了更多的Ray应用案例和它在生产系统上的部署。在之前的博文里我列举了加州大学伯克利分校研究组(他们研究混合自主化交通)和蚂蚁金服(他们已经在生产系统的几个场景里使用Ray)作为Ray的使用案例。在那之后,我又听到了多个不同场景里使用Ray的案例。
- 金融服务和工业自动化应用。
- Ray被用在文本挖掘上,构建知识图谱和图谱查询。
- 一些企业在探索使用Ray来进行实时推荐,其中包括了针对实时数据进行建模。
另外,在人工智能、机器学习、机器人和工程等领域采用Ray的研究群体数量也在增加。随着Ray开始在云平台上(亚马逊的SageMaker强化学习里包括进了Ray)可用,我认为会听到更多的使用Ray的有趣案例出现。
综上所述,现在是开始探索Ray的一个好时间。它的核心API已经稳定下来,相关的库在被进一步改进和增强,更多的生产级应用部署开始出现。更重要的是整个用户社区和贡献者也在增加。
相关内容:
- RISE实验室团队提供的《Ray编程——给首次使用者的诀窍》
- 来自首次Ray聚会的记录
- Cathy Wu的《在混合自主化交通里使用强化学习》
- Robert Nishihara和Phillipp Moritz写的《Ray是如何让持续学习可用和易于扩展的》
- 《深度学习里的深度自动化》
- Danny Lange写的《释放强化学习的潜能》
- 《克服采用人工智能的障碍》

Ben Lorica
Ben Lorica是O’Reilly Media公司的首席数据科学家,同时也是Strata数据会议和O’Reilly人工智能会议的内容日程主管。他曾在多种场景下应用商业智能、数据挖掘、机器学习和统计分析技术,这些场景包括直销、消费者与市场研究、定向广告、文本挖掘和金融工程。他的背景包括在投资管理公司、互联网初创企业和金融服务公司就职。





