在Strata 2017我首次提出了一个新图表,帮助团队了解团队失败的原因以及何时失败:
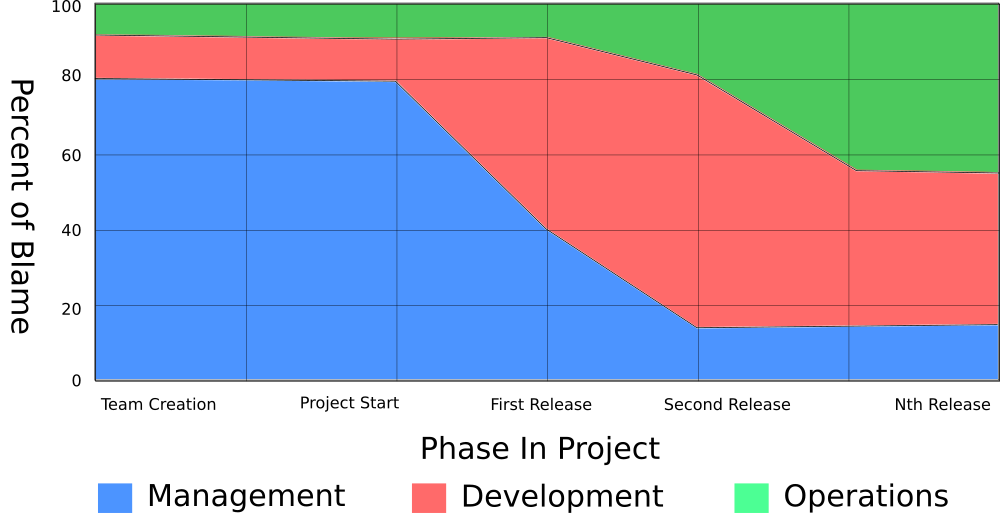
在项目早期,管理层和开发人员对项目成功负责。随着项目的成熟,运维团队也对项目成功负责。
当运维团队成员抱怨说没有人愿意做运维的时候,我曾经在这样的情况下教育团队。他们是对的。 数据科学是公司想要的“性感”。数据工程和运维团队并没有得到太多的爱护。 这些组织没有意识到数据科学站在数据运维和数据工程师巨人的肩膀上。
我们需要做的是给这些角色一个性感的头衔。 让我们如此称呼这些专注于大数据的运维团队:数据运维(DataOps)团队。
运维怎么说?
当您公开数据管线时,公司需要了解不同级别的操作要求。 数据管线需要爱和关注。 对于大数据,这不仅仅是确保集群进程正在运行。 数据运维团队不仅需要保证系统运行,还要留心关注数据。
对于大数据,我们经常处理来自不可靠来源的数据或者非结构化数据。 这意味着有人需要负责以某种方式验证数据。 这里是一个企业可能会陷入“垃圾数据导致垃圾产出”恶性循环,并导致项目失败的地方。 如果这些脏数据扩散并传播到其他系统,我们就打开潘多拉的盒子,引起一系列意外后果。 数据团队需要注意到数据问题,并在数据传播之前进行修正。
这些数据质量问题为实时系统带来了新的潜在问题。 最糟糕的情况是,数据工程团队没有正确处理特定问题,导致您手上有一系列连续的故障。 数据运维团队将在一线确定问题到底是关于数据的,还是关于代码的。
数据工程团队不应对此负责吗? 数据工程师本质上是软件开发人员。 我教导了很多人,并且与更多人进行互动。 我不会让我遇见的99%的数据工程师接近生产系统。 有几个原因,例如缺乏运维知识,缺乏运维思维,以及在精密的系统中横冲直撞。 有时,在开发和生产数据之间何时需要分离上,存在一些合规性问题。 数据工程团队不是处理这个问题的合适团队。
这使我们绝对需要一个了解大数据操作和数据质量的团队。 他们知道如何操作大数据框架。 他们能够找出代码问题和数据质量问题之间的区别。
实时性:大数据的涡轮增压加速按钮
现在让我们按下涡轮增压加速按钮(turbo button)并展开谈谈与它有关的点:这其中包括批处理系统和实时系统。
停机和数据质量问题对于批处理系统来说是痛苦的。 对于批处理系统,通常不会丢失数据。 你只是在处理以及获取数据方面比数据产生落后了。 您最终会赶上并回到稳定的数据状态并按时处理。
然后是实时处理问题。 实时系统的中断让痛苦程度达到了新高度。 你正在处理那些会永久丢失的数据。 事实上,在停机期间的这种痛苦是我如何确定公司是否真的需要实时系统的判断标准。 如果我告诉他们,为了保证实时性,他们需要一个全新的服务水平协议(SLA),而他们不同意,这可能意味着他们不需要实时性。 实时群集的运行停机时间应该是非常痛苦的,以至于您将尽一切力量防止中断。 您的实时系统中断6小时应该相当于一次五级火灾警报。
所有这些SLA都完全属于数据运维团队的处理范畴。 当他们出错时,他们不仅要负责解决问题; 它们将成为系统设计的积极组成部分。 数据运维和数据工程将选择能够预期到系统失效的技术。 数据运维团队将确保数据(最好是自动化确保)移动到灾难备份或移动到一个双活集群。 这就是你避免六小时停机的方法。
搞定实时技术和SLA级别是以增加概念复杂性和操作复杂性为代价的。 当我指导团队进行大数据系统向具备实时性过度时,我确保管理层了解架构师和开发人员并不是唯一需要新技能的人。 运维团队需要学习新技能,以及新技术如何运作。
数据运维(DataOps)一词中不存在“我(I)”
根据我的经验,从小数据到实时大数据的复杂度飞涨了15倍。 再一次,这强调了对数据运维的需求。 单个人很难跟上小数据和大数据技术的所有变化。 数据运维团队需要专注于大数据技术,并跟上与之相关的最新问题。
当我指导更多团队过渡到实时系统时,我看到了各个组织的共同问题。 这是因为向实时数据管道的过渡带来了跨职能的改变。
例如,使用REST API,运维团队可以负责管理这件事。 他们对谁能访问、如何访问以及为什么能够访问REST终端服务进行了细粒度的控制。 使用实时数据管线变得更加困难。 数据运维团队需要监控实时数据管线的使用情况。 首先最重要的一点是,他们需要确保所有数据都已加密,并且该访问需要登录。
数据运维的一个终极重要的方面,是处理数据格式的变化。 就算使用实时系统,数据格式也会发生变化。 这将是数据工程团队和数据运维团队需要协同工作的关键时刻。 数据工程团队将处理问题的开发和架构方面。 数据运维团队需要处理因这些更改而产生的生产问题,以及对于格式更改而导致的功能失效进行分类处理。
如果你仍没被说服,让我最后补充重磅发言
正确定位“数据运维”(DataOps)岗位职能,对于您的后期大数据项目至关重要。这是一个让您的框架保持运行并且拥有高数据质量的团队。 数据运维对于拥有良好数据的良性循环大有裨益。当您开始了实时化或批处理化数据的旅程时,请确保您的数据运维团队已准备好迎接未来的挑战。
这篇文章是O’Reilly与Mesosphere合作的一部分。 请参阅我们的编辑独立性声明。

Jesse Anderson
Jesse Anderson是Big Data Institute(大数据学院)的数据工程师,创意工程师和常务董事。 Jesse为员工提供大数据培训,培训内容包括Apache Kafka,Apache Hadoop和Apache Spark等尖端技术。 他教过成千上万的学生,这些学生遍布从初创到财富100强的各种公司,从他这里获得了数据工程师的技能。 他被广泛认为是该领域的专家,并因其新颖的教学实践而受到广泛认可。 Jesse受到O’Reilly、Pragmatic Programmers的宣传,并且吸引了类似Wall Street Journal, CNN, BBC, NPR, Engadget及Wired这种主流媒体的报道。你可以在Jesse-Anderson.com 了解关于他的更多信息。






不要错过作者在2019年6月18日至21日北京举行的AI大会上带来的培训课程Professional Kafka development。