深度学习提供了这样一种承诺:它可以绕过手动特征工程的流程,通过端对端的方式联合学习中间表征与统计模型。 然而,神经网络架构本身通常由专家以艰苦的、一事一议的方式临时设计出来。 神经网络架构搜索(NAS)被誉为一条减轻痛苦之路,它可以自动识别哪些网络优于手工设计的网络。
但是,无论是在研究进展还是炒作方面,这个领域都变得如此之快,很难得到一些基础问题的答案:NAS到底是什么,它与AutoML或超参数优化有什么根本的不同? 定制化的NAS方法真的有用吗? 它们使用起来不是很昂贵吗? 我应该使用定制化的NAS方法吗? 在这篇文章中,我们将回答每个问题。 我们的讨论涉及几个关键点:
- NAS与传统的超参数优化之间存在二分法是错误的; 实际上,NAS是超参数优化的子集。 此外,定制化的NAS方法实际上并不是完全自动化的,因为它们依赖于人工设计的神经网络架构作为搜索的起点。
- 虽然探索和调整不同的神经网络架构对于开发高质量的深度学习应用至关重要,但我们认为定制化的NAS方法还没到迎来黄金时段的水平:与高质量的超参数优化算法相比,它们引入了显著的算法和计算复杂度(例如ASHA),却无法证明在标准基准测试任务上带来性能提高。
- 尽管如此,定制化NAS方法在过去几年中,对于提高精度,降低计算成本和降低网络架构尺寸几个方面取得了显着进步,并且最终可能超越人类在神经网络架构设计方面的表现。
宏观而言,让我们首先讨论NAS如何适应更广泛的AutoML(自动机器学习)。
AutoML⊃超参数优化⊃NAS
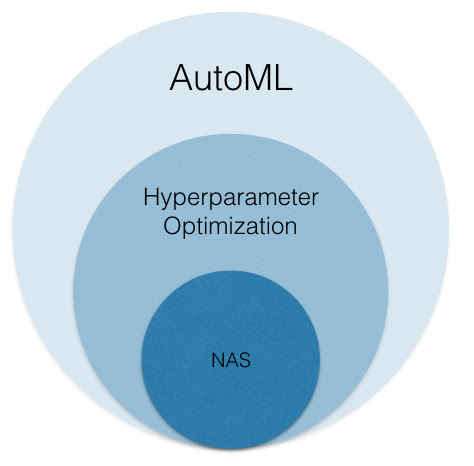
图1.感谢Determined AI提供图片
AutoML专注于自动化机器学习(ML)工作流程的各个方面,以提高效率,并带来了机器学习民主化,以便非专家可以轻松地将机器学习应用于他们的问题。 虽然AutoML包含与ETL(对数据的提取,转换,加载),模型训练和模型部署相关的各种问题的自动化,但超参数优化问题是AutoML的核心焦点。 此问题涉及对ML模型/算法行为的内部设置进行配置管理,返回高质量的预测模型。
例如,岭回归模型需要设置正则化项的值;随机森林模型要求用户设置每个叶子节点包含的最小样本数,以及总模型树的最大深度;训练任何需要随机梯度下降的模型,需要设置适当的学习率步长。 神经网络还需要设置多个超参数,包括(1)选择优化器及其相关的超参数集; (2)设置dropout比率和其他正则化超参数;如果需要的话还要(3)调整控制网络架构的参数(例如,隐层的层数,卷积核的数量)。
虽然对NAS的阐述可能暗示它是一个全新的问题,但我们上面的最后一个例子暗示了超参数优化和NAS之间的密切关系。 尽管用于NAS的搜索空间通常较大,而且涵盖了控制神经网络架构的方方面面,但是底层问题与超参数优化所解决的问题相同:在搜索空间内,找到在目标任务上表现良好的一组配置。 因此,我们将NAS视为超参数优化中的子问题。
虽然是一个子问题,不过NAS仍然是一个令人兴奋的研究方向,因为专注于一个专门的子问题,提供了利用额外结构来设计定制化解决方案的机会(许多专门的NAS方法都是这么做的) 在下一节中,我们将提供NAS的概述,并深入研究超参数优化和NAS之间的相似点和不同点。
NAS概述
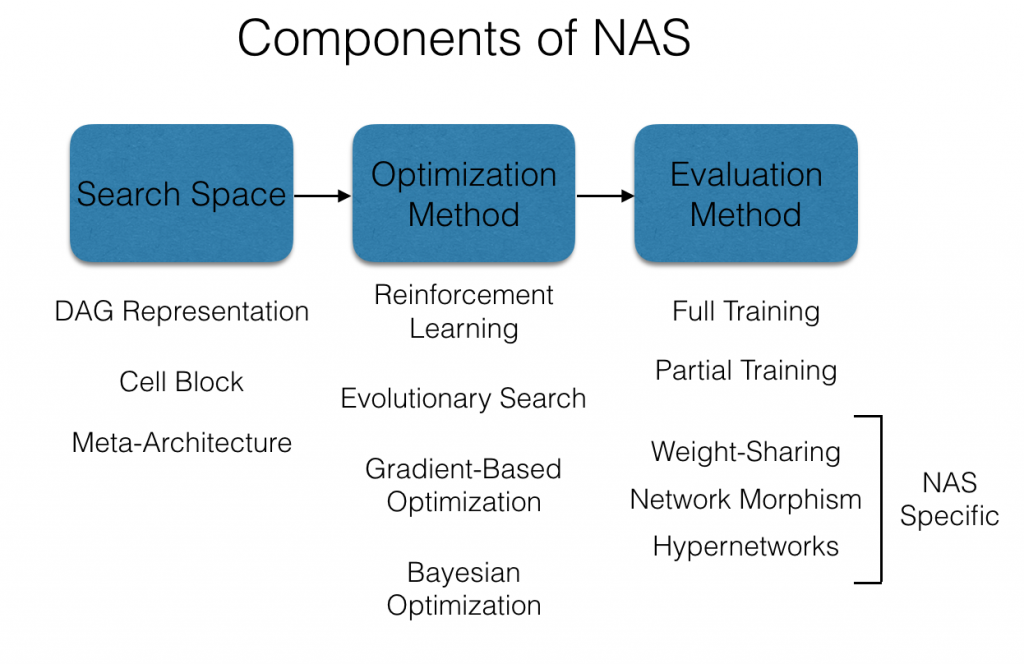
图2. 感谢DeterminedAI提供图片
在Zoph等人的工作之后,对NAS的兴趣激增。他们的工作使用强化学习来设计当时最先进的图像识别和语言模型架构。不过,尽管Zoph等人设计了用于NAS的第一代定制化方法,随之而来的是这种方法需要大量的算力(例如,数以百计的GPU实际运行时长上千天),这使得它们对于除了Google这样的公司以外的所有人而言,都是不切实际的。最近的方法利用各种重用方法来大幅降低计算成本,并且在研究界中还在快速引入新方法。
接下来我们将稍微深入地探讨与定制化NAS方法相关的核心设计决策(有关NAS的更详细概述,我们推荐阅读2017年Elsken等人做的优秀调研)。三个主要组成部分是:
- 搜索空间。 该组件描述了潜在可能的神经网络架构集合。这些搜索空间是针对应用而专门设计的,例如,针对计算机视觉任务的卷积网络空间,或针对语言建模任务的递归神经网络空间。 因此,NAS方法并非完全自动化,因为这些搜索空间的设计从根本上依赖于人为设计的架构作为起点。 即便如此,仍然存在许多架构参数需要决策。 实际上,在这些搜索空间中需要考虑的潜在架构的数量通常超过10的10次方。
- 优化方法。 此组件确定如何浏览搜索空间以便找到一个好的架构。 这里最基本的方法是随机搜索,同时还引入了各种自适应方法,例如强化学习,进化搜索,基于梯度的优化和贝叶斯优化。 虽然这些自适应方法在选择评估哪些架构上存在些许不同,但它们都试图搜索倾向于更可能表现良好的网络架构。 不出所料的是,所有这些方法都具有在传统超参数优化任务的情境下的对应方法。
- 评估方法。 该组件测量优化方法考虑的每种体系结构的表现。 最简单,但计算量最大的选择是完整的训练一个网络。 人们可以选择利用部分训练,使用类似于ASHA等超参数优化中常用的早期停止方法。针对NAS特定的评估方法,如网络同态映射,权重共享,以及超网络,也都可以引入,用于发掘神经网络的结构,提供更节省算力、启发式的模型质量评估。部分训练方法通常比完整训练的算力少一个数量级,而针对NAS的评估方法,比完全训练模型对算力的消耗低两到三个数量级。
值得注意的是,这些是传统超参数优化方法的三个必要成分。 研究界已经聚合了一些规范的基准数据集和任务,用来评估不同搜索方法的性能,接下来我们将使用这些基准来报告(1)用超参数优化方法调整的人工设计的架构以及(2)前沿的针对NAS设计的方法,通过NAS设计的架构。 (NAS专注于寻找与识别架构的问题,但仍需要辅助性的超参数优化步骤,来调整它所寻找到的的架构中,非架构的特定超参数。下表显示了这两个步骤后的测试误差率。)
NAS模型与人工设计的模型
用于基准NAS方法的两个最常见的任务是(1)设计在CIFAR-10数据集上评估的卷积神经网络(CNN)架构,以及(2)设计在PennTree Bank(PTB)上评估的递归神经网络(RNN)架构)数据集。 我们在下表中显示了CIFAR-10上不同体系结构的测试错误。
| 资源 | 参数数量(百万) | 测试误差 | 搜索方法 | 评估方法 | |
| PyramidNet + ShakeDrop | Yamada等人,2018年 | 26 | 2.31 | 人工设计 | – |
| NASNet-A +CutOut | Zoph等人,2017年 | 3.3 | 2.65 | 强化学习 | 全部训练 |
| AmoebaNet-B +CutOut | Real等人,2018年 | 34.9 | 2.13 | 基于进化 | 全程 |
| NAONET | 罗等人,2018年 | 28.6 | 2.98 | 基于梯度 | 部分训练 |
| DARTS +CutOut | H. Liu等,2018 | 3.4 | 2.83 | 基于梯度 | 权重共享 |
表1. 前沿的神经网络架构在CIFAR-10上的测试误差率表现,有些是人工设计,另一些是用各种搜索方法、评估方法通过定制化的NAS方法实现的。请注意,所有架构都通过标准的超参数优化方法进行了调整。
对于CIFAR-10基准测试,使用完全训练的的定制化NAS方法与手工设计的网络架构旗鼓相当;然而,它们非常昂贵,需要超过1,000个GPU天。 虽然利用部分训练或其他NAS特定评估方法的方法需要较少的计算来执行搜索(分别为400 GPU天和~1 GPU天),但它们的表现被表1中的人工设计架构所超越了。值得注意的是,NAS架构比人工设计的模型低几乎一个数量级的参数,表明NAS在显存约束、延迟约束的应用场合下可能还有希望。
表2中显示了PTB数据集上不同架构的测试混淆度。
| 来源 | 测试混淆度 | 搜索方法 | 评估方法 | |
| 带MoS的LSTM | Yang等人,2017 | 54.4 | 手工设计 | – |
| NASNet | Zoph等人,2016 | 62.4 | 强化学习 | 全部训练 |
| NAONET | 罗等人,2018年 | 56.0 | 基于梯度 | 部分训练 |
| DARTS | H. Liu等人,2018 | 55.7 | 基于地图 | 权重共享 |
表2.由人类设计或通过具有各种搜索和评估方法的专用NAS方法设计的领先架构的PTB测试困惑度。 请注意,所有体系结构都是通过标准的超参数优化方法进行调整的。
与手动设计的架构相比,定制化的NAS结果在PTB基准测试中的竞争力较弱。 然而,令人惊讶的是,简单评估方法优于全部训练;这可能是由于自2016年Zoph等人发表的2016年的论文以来,在LSTM方面取得的额外进展。
定制化的NAS方法是否马上会被广泛采用?
还没有!需要明确的是,探索各种网络架构,并执行大量的超参数优化,仍然是任何深度学习应用程序工作流程的主要组成部分。 然而,鉴于现有的研究结果(如上所述),我们认为虽然针对性的NAS方法已经在这两个基准测试中显示出比较有希望的结果,但由于以下原因,它们仍然离进入黄金时段存在距离:
- 由于高度手工调整、设计的架构,在CIFAR-10上和计算可行NAS方法相比具有竞争力,而且在PTB上优于针对性的NAS方法,我们相信,资源用于现有手动设计架构的超参数优化是更好的。
- 大多数定制化的NAS方法对于给定的搜索空间是相当特定的,并且需要针对每个新的搜索空间进行重新训练、重新组合。 另外,某些方法存在鲁棒性问题,难以训练。 这些问题目前阻碍了现有定制化NAS方法对不同任务的普遍适用性。
相关阅读:
- “迈向机器学习的飞速发展时代”
- “神经进化:一种不同的深度学习”
- “机器学习中的深度自动化”
- Ameet Talwalkar谈关于“如何训练和部署大规模深度学习模型”
- “开放性:你可能从未听说过的最后大挑战”
Liam Li
Liam Li是卡内基梅隆大学机器学习系的博士生,在那里他与Ameet Talwalkar合作。 他目前的研究重点是自动化机器学习中模型的选择,研究目标是开发工具和算法,使机器学习的实践更简单、更容易上手。
Ameet Talwalkar
Ameet Talwalkar是卡内基梅隆大学机器学习系的助理教授。 他还是Determined AI的联合创始人兼首席科学家,这是一家软件公司,它使机器学习工程师和数据科学家的工作效率大大提高。





该文章最初发表于Determined AI博客,经许可重新发表于此。