在这篇文章中我分享5月底我在伦敦Strata数据会议上演讲中使用的幻灯片和笔记。 我的目标是提醒数据社区,数据本身中存在着许多有趣的机遇和挑战。 近期新闻报道的重点主要集中在算法和模型,尤其是深度学习日益增长的应用领域。由于大型深度学习架构非常依赖大量数据,这使得数据的重要性日益增长。 在这篇简短的演讲中,我描述了一些关于数据是如何被估值、收集和共享的趋势。
数据的经济价值
众所周知,公司非常重视数据,以及那些产生关键数据特征的数据管线。 在机器学习(ML)广泛被采纳的的早期阶段,公司专注于确保他们有足够数量的有标注的(训练)数据,把这些数据应用于他们想要解决的问题。 然后,他们会研究可用于扩充现有数据的附加数据源。 实际上,在许多从业者眼中,数据仍然比模型更有价值(许多人公开谈论他们所使用的模型,但他们不愿意讨论他们为这些模型输入了什么特征。
如果数据很珍贵,我们该如何评估其价值呢? 对于我们之中构建机器学习模型的人,我们可以通过检查获取训练数据的成本来估算数据的价值:

- 在数据科学工作中,我们中不少人在不同程度上已经开始使用付费的外部数据源,以扩充我们已有的数据集。 Bloomberg,Nielsen,Dun&Bradstreet,以及Planet Labs这种新进入行业的数据提供商围绕许多数据集提供数据订阅服务。
- 我们还确切地知道,从头开始构建训练数据集需要多少成本。 随着类似深度学习等大量需要数据方法的兴起,对Figure Eight和Mighty AI等公司提供服务的需求不断增长,这些服务可帮助公司对图像,视频和其他数据源进行标注。
- 对于特定的数据类型(如图像),一些新兴的公司,如Neuromation,DataGen和AI.Reverie等,可以通过生成人工合成数据的工具,帮助企业降低采集训练数据的成本。
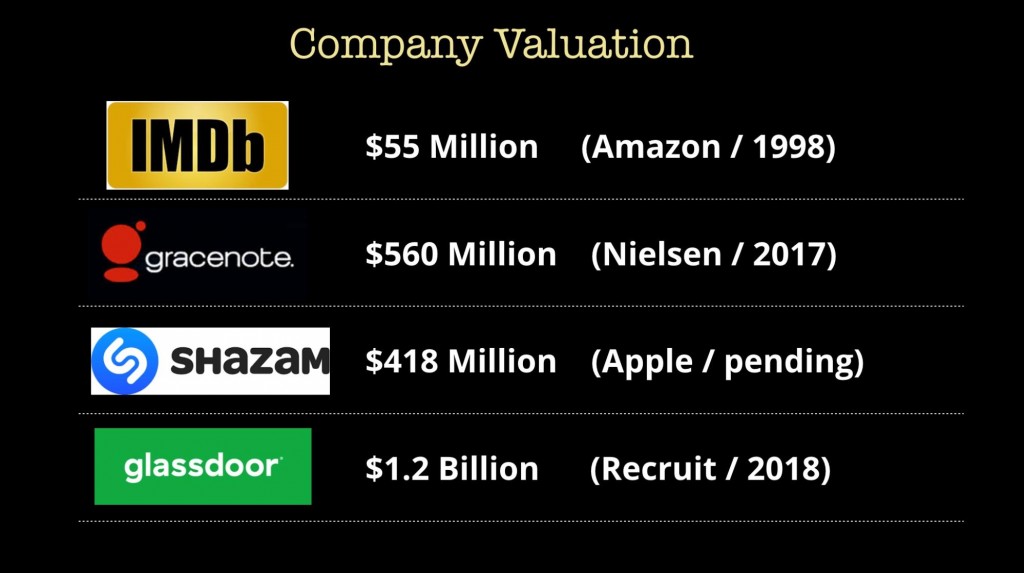
我们可以收集数据价值的另一种方法,是查看那些知名度主要来自于其拥有数据集的初创公司的估值。 我列举了不少媒体行业的例子,不过也有很多新的创业公司收集航拍图像,天气数据, 体育赛中数据和物流数据等。 如果您是一位有抱负的企业家,请注意,您可以通过专注于数据来建立有趣且高估值的公司。
数据科学家和数据工程师需要更多数据的原因,是他们可以因此衡量数据对其数据产品的影响。 这导致了另一种可以估计数据价值的方法:通过观察新数据源对现有数据产品的增量影响来核定数据价值。
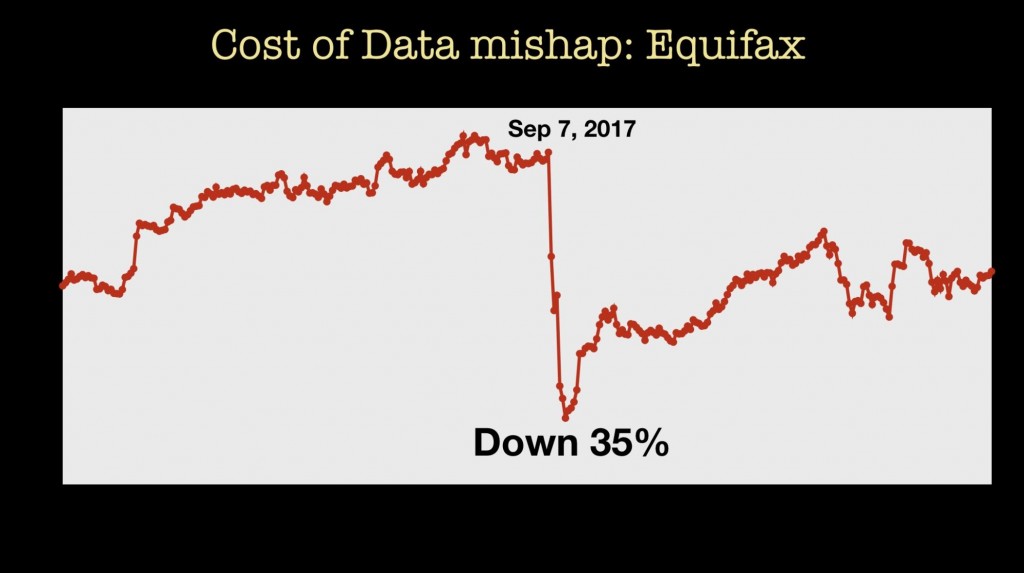
依靠外部数据并非没有风险。 安全漏洞和其他技术原因可能会导致您的数据供应中断。 更可能的原因是,由于对数据收集和数据隐私的顾虑变得日益强烈,共享和销售数据的行为受到更多的审查。 访问权限的丢失也可间接证明数据是多么有价值:
- 数据事故对公司市值的影响是可观察到的
- 在您所建立的机器学习模型上发生了数据源“失去访问权”的影响是可以度量的
数据隐私的现状:来自关键利益相关者的观点
最近几个月,围绕数据隐私和数据收集,我们的期望和态度发生了变化。 让我们从一些关键利益相关者的角度来审视当前的情况:这些利益相关者包括用户,监管机构,公司和数据专业人士。
用户对“什么可能发生在他们自己产生的数据”的期望已经发生了变化。 根据最近的头条新闻( Facebook和Cambridge Analytica),公众对数据收集,存储和共享已经变得更加关注。沟通已经不局限于数据隐私,用户的诉求包括:
- 更大的透明度 – 他们想知道哪些数据正在被收集,又共享给了谁
- 控制他们的数据如何被共享和使用
- 限制数据共享的属性和持续时间
许多国家和地区的监管机构正在推进具有里程碑意义的立法:针对那些部署数据分析产品的公司,欧洲( GDPR)和加利福尼亚( 消费者隐私法案)将“用户控制”和“设计隐私”等概念置于最高优先级。 澳大利亚最近在其现有数据隐私规则中添加了数据泄露通知。
数据隐私和数据货币化的立场正在成为一些小型和大型企业的竞争切入点。 特别值得一提的是苹果公司,它正在提高数据隐私和收集的标准,不过其他公司也纷纷效仿。 展望未来,一些公司将不得不调整其服务 – 不仅要考虑到监管,也要考虑用户不断变化的期望。
数据专业人员也非常重视数据隐私问题。 许多人已经在他们的公司内部实施了培训计划,有些人已经在探索新的隐私保护工具和方法论来构建数据分析产品。 除了隐私,更进一步的是,下一代数据科学家和数据工程师正在接受培训并参与关于道德的讨论。 许多大学提供了相关课程,像加州大学伯克利分校提供了多门课程。

隐私时代的数据流动性:新型数据交换
处于一个用户对对数据隐私和用户控制的认知被提高的时期,我们在这个背景下进行公司运营。 在机器学习模型需要如此多数据的时代,我们该如何继续提供数据的流动性?
许多机构都在维护数据孤岛:数个独立系统在内部团队间限制彼此的访问,还有一些系统存储着他们不愿意与外部用户共享数据。 与此同时,公司通常会拥有愿意与他人分享的数据。 问题是,没有方便的机制或通用格式能让数据共享变得更容易。 想象一下如果有工具和机制(通过公共数据标准)使这些数据集可共享会是怎样的情形。 这意味着,独立的数据孤岛现在可以建立在外部数据的坚实基础上,所有参与组织都可以使用这些数据孤岛来增强其ML模型。

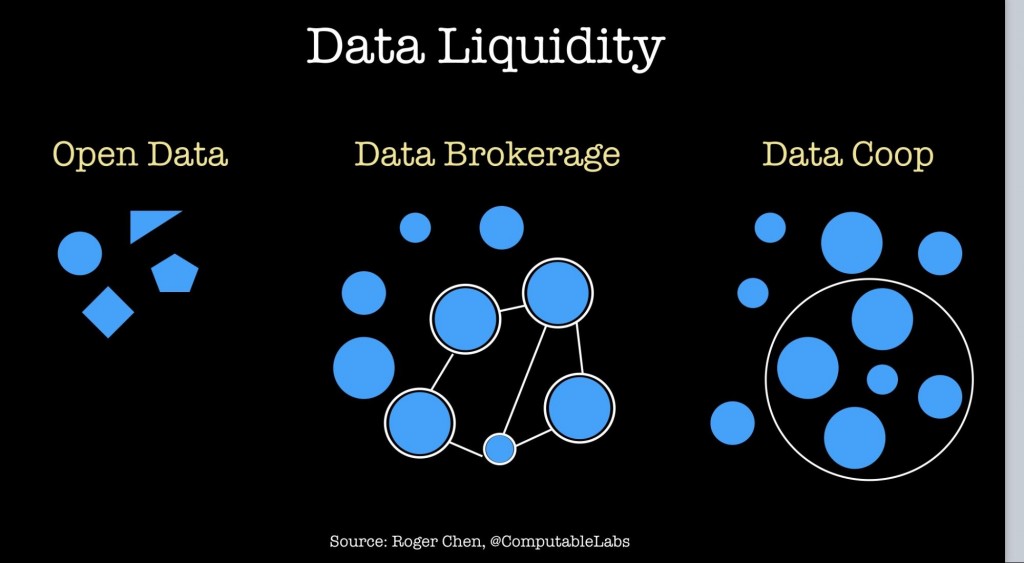
在2017年的一篇文章中Roger Chen描述了公司在构建数据交易所(或“数据网络”)时采取的三种主要方法:
- 开源数据 :缺乏市场激励使得开源数据模型难以线性扩展,并且它们尤其容易受到数据异构性的挑战。
- 数据合作 :需要最大程度的信任,因此受到冷启动的挑战。 话虽如此,为生物医学领域中的公共数据标准建立工具已经有了长足的进步,在该领域中学到的经验教训应该转化到其他领域中。
- 数据中间商 :参与者获得汇总和销售数据的经济回报,潜在地可以带来更大的规模和更好的流动性。
我最近遇到的一个趋势是去中心化的数据网络。这个想法是,建立使用基于区块链和分布式账本的技术,以及使用加密货币的激励结构,建立去中心化的数据交易所。 这个领域的一些初创公司是专门针对机器学习的 —— 他们希望数据科学家能够“在不看数据的情况下训练模型”。
最有趣的原创性思考来自于旧金山一家名为Computable Labs的创业公司。 他们正在构建开源、去中心化的基础架构允许公司安全地共享数据和模型。 在此过程中,他们希望“使区块链网络与机器学习计算兼容”。
结束语:一些思考

尽管模型和算法占据了大部分媒体报道版面,现在正是考虑针对数据构建工具的不错时机。 我们正处于机器学习模型需要大量数据的时代,许多公司才刚刚开始部署机器学习模型。 安全和隐私的核心主题一直存在,但还有许多其他引人注目且具有挑战性的问题和机会涉及道德,经济价值,数据流动性,用户控制和去中心化。
相关资源:
- “建立更强大的数据生态系统”
- 用于训练AI模型的去中心化数据市场
- “数据推断计算时代的数据流动性”
- “如何在数据隐私变得至关重要的时代构建数据分析产品”
- “数据监管和隐私的讨论仍处于早期阶段”:AuréliePols关于GDPR,道德规范和电子隐私
- “管理机器学习模型中的风险”:Andrew Burt和Steven Touw关于公司如何管理他们无法完全解释的模型。

Ben Lorica
本· 罗瑞卡是O'Reilly的首席数据科学家和关于数据方面的内容策略主管。在多个领域里(包括直销市场、消费者和市场研究、精准广告、文本挖掘和金融工程),他曾经进行了商业智能、数据挖掘、机器学习和统计分析的工作。他曾效力于投资管理公司、互联网创业企业和金融服务公司。





