解释机器学习模型是目前数据科学界一个相当热门的话题。 机器学习模型需要可被解释,以便先进的预测建模技术被更广泛地采纳,防止社会歧视性预测,防止对决策系统的恶意攻击,因为机器学习模型能够简单直接地影响我们的工作和生活。 与应用机器学习领域中的其他人一样,我和H2O.ai的同事在过去18个月左右的时间里一直在开发机器学习的可解释性软件。
我们可以在今年早些时候的O’Reilly报告中,对可解释性领域的应用问题进行总结。 接下来是该报告的摘录,以及一些新的额外阅读材料。 本文将重点介绍一点重要的,但似乎不太经常被讨论的可解释性问题:机器学习可解释性技术的近似性质,以及如何检验对模型的解释。
为什么我们需要测试可解释性技术?
最严肃的数据科学从业者理解这一点:机器学习可以在竞争激烈的受监管行业中,产生更准确的模型并最终获得财务收益……前提是它更容易解释。 那么为什么不是每个人都试试可解释的机器学习呢?简单回答之:从根本上说,这很难,这是一个非常新的研究领域。 机器学习可解释性中两个最棘手的问题是:1)大多数流行的机器学习模型具有组合、重组输入变量的趋势,以及 2)被称为“ 良好模型的多样性 ”的现象。这两个问题从某种意义上,共同构成了绝大部分机器学习可解释性技术。
机器学习模型对变量进行组合,但我们需要基于单个变量的解释
流行的机器学习模型可以比传统的线性模型生成更准确的预测的主要机制是,它学习到了输入变量之间的高阶交互作用。 图1显示了简单的人工神经网络(ANN)的简单图示。 我们可以看到原始输入变量x1−x5被组合在网络的第一个隐层中,得到神经元h11−h14 ,它们在网络的第二层隐层中重新组合,构成了神经元h21−h23,其在网络的第三层隐层再次被重组,构成了在最终做出预测之前所需要的神经元h31和h32。
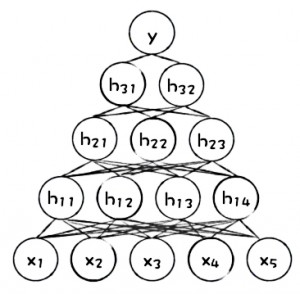
图1.人工神经网络的图示。 感谢由H2O.ai提供的图片
虽然学习如何权衡输入变量的复杂组合能够带来更准确的预测,但它使解释机器学习模型变得真的很困难。 绝大多数人,和一些非常严谨的监管法规,都偏好于那些可被解释的预测模型生成的决策,是由原始输入变量所带来的,而不是输入变量的任意高阶组合、缩放、加权组合所带来的。
如果您申请一张信用卡被拒绝,贷款人通常不会说这是因为您的负债/收入比率、储蓄账户余额、邮政编码、打网球倾向、信用记录长度以及信用评分的加权/缩放组合的反正切值等于0.57。 就算这可能是模型决定拒绝您的方式,贷方通常也需要打散这个决策,并尝试用简单的术语,每次仅使用一个原始输入变量,并且仅使用重要的原始变量向您进行解释。例如,陈述您的债务/收入比率太高,信用评分太低,而信用记录太短。 对于机器学习模型而言,这种分解过程通常只是近似的,并不真正代表机器学习模型实际就是这么进行预测的。 这也是我们应该使用几种不同类型的可解释性技术来相互校验、为什么我们应该对机器学习可解释性技术进行检验的一个主要原因。
好模型的多样性
在2001年开创性的论文中加州大学伯克利分校的教授Leo Breiman让这样一句话变得流行起来:“好模型的多样性。”这句话意味着对于同一组输入变量和预测目标,复杂的机器学习算法可以产生多个精确的模型,这些模型内部结构类似,但不完全相同。 (一些信用评分将这种现象称为“模型局部性”。)
图2是非凸面误差率曲面的形象描述,其表征了一个机器学习算法的误差函数,这个算法具有两个输入- 比如客户的收入和客户的利率 – 以及输出,例如同一客户的贷款违约概率。 这种没有明显全局最小值的非凸错误率曲面,意味着复杂的机器学习算法可以学到许多不同的方式来组合客户的收入和客户的利率,从而做出关于何时可能违约的准确判断。每一种不同的权重构建了一个不同的判断贷款违约的函数,每一个这样的函数都有着不同的解释。所有这些都是解释模型的障碍,因为来自非常相似的模型的非常类似的预测,仍然可以有不同的解释。 由于这种系统的不稳定性,我们应该使用几种可解释性技术来检验单个模型的数种解释,我们应该在多种建模和解释技术中寻求具有一致性的结果,并且我们应该检验我们的解释性技术。
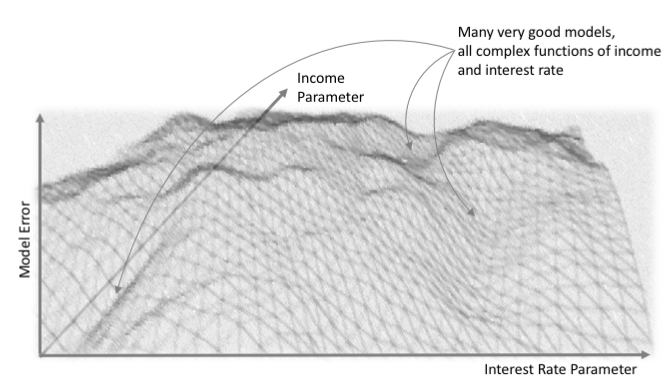
图2.机器学习模型错误率曲面的图示。 感谢由H2O.ai提供的图片
我们如何检验可解释性技术?
由于对机器学习解释的近似性质,能够引发且经常导致对模型解释性本身的质疑, 因此我们需要检验解释的准确性。 不要烦恼 —— 这当然是可行的!最初, 研究人员提出了检验机器学习模型解释的方法,通过模型的容量,帮助人们识别建模错误,发现新事实,减少模型预测中的社会学歧视,或使人类能够根据输入数据值正确地确定模型预测的结果。 人类的确认,可能是机器学习可解释性的最高门槛,但最近的研究强调了对先入为主,对简单性的倾向偏好,以及人类评估中的其他偏见等一系列问题的潜在担忧 。 鉴于专业的人工评估研究对于大多数商业数据科学或机器学习小组来说可能永远是不切实际的,我们在这里(也可能是其他地方)提出了几种其他用于检验模型解释的自动化方法:我们可以使用具有已知数字统计特征的模拟数据来对解释进行检验; 我们可以针对同一个数据集,将新的解释与旧的、可靠的解释进行比较; 我们可以检验解释是否具备稳定性。 使用模拟数据来对解释进行检验,对于我们在H2O的工作中显得卓有成效,因此我们将在本文中深入研究该方法的更多细节。
在完全随机的、一组输入变量和一个预测目标之间完全没有联系的数据上训练得到的模型,不应该对任何输入变量赋予很强的权重,也不该产生具有说服力的本地解释。 图3显示了全局变量重要性,由三个不同的工具计算: XGBoost, treeinterpreter和shap,用于检验在随机数据上训练的XGBoost GBM二分类模型。 从这三种相互确认的方法中,我们可以相当确定XGBoost模型没有过度拟合随机信号,给予任何一个变量远超过另一个变量的权重,我们可以看到全局解释性大致互相符合,也符合我们已知的随机生成的训练数据的情况。
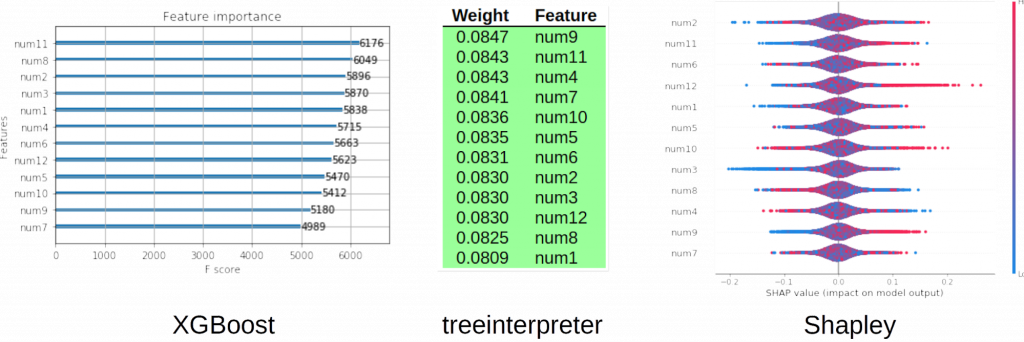
图3.在随机数据上训练的XGBoost模型的全局变量重要性。 感谢由H2O.ai提供的图片
我们也可以用同样的方式检验变量的局部重要性。 给定在随机数据上训练的相同XGBoost模型,对于代表中位数预测的但行数据,我们可以预期没有哪个变量对模型预测做出很大贡献,并且小的局部贡献大致随机分布在一定的正负贡献。 图4使用了LIME,treeinterpreter和shap方法向我们展示了这个结果,并且应该有助于增强对模型和解释的信任。 现在我们从局部的角度看,XGBoost没有在随机数据上发生过拟合,解释工具基本可以相互确认,并且和训练数据中的已知的信号随机性相符合。
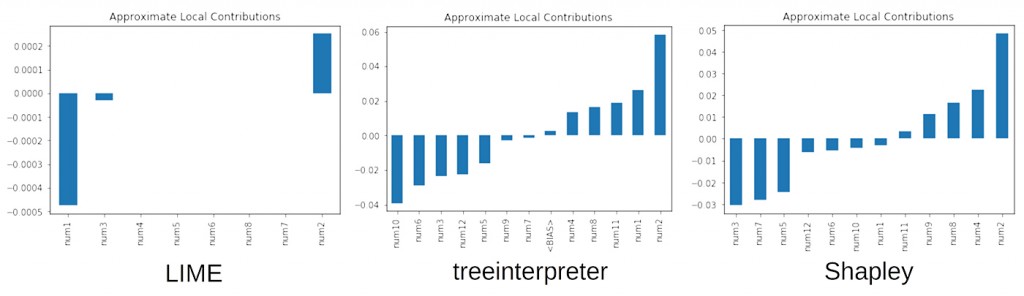
图4.对随机数据训练的XGBoost模型的局部变量重要性。 感谢由H2O.ai提供的图片
我们可以使用具有已知信号生成函数的模拟数据来检验一个事实,即“解释已经准确表达了那个已知函数”。 图5显示了,对于在已知信号生成函数上训练的XGBoost GBM二元分类器模型,XGBoost,treeinterpreter和shap工具给出的全局变量重要性,其中e是一个小的随机误差项:
num1∗num4+|num8|∗num92+e
在图5中,我们可以看到,虽然这三个工具没有按照完全相同的顺序对重要的变量进行排序,但模型明确知道,信号生成函数中的四个变量比我们生成的训练数据中的其他变量更重要。 这些解释,在我们的模拟数据实验中展示了已知的基本事实,因此这歌结果应该增加我们对建模和解释方法的信任度。
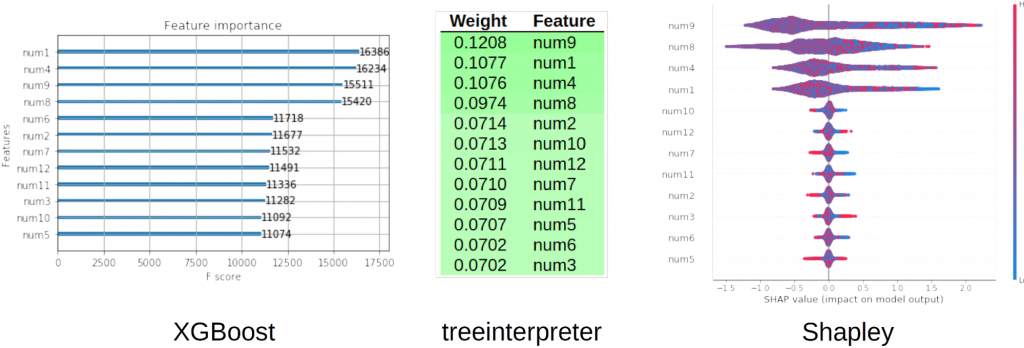
图5.在已知信号生成函数上训练的XGBoost模型的全局变量重要性。 变量num1,num4,num8和num9应该很重要。 感谢由H2O.ai提供的图片
图6展示的例子里,使用相同的XGBoost模型和模拟训练数据进行局部解释。 在这里,我们看到一些有趣的情形:虽然所有解释性技术都将num9,num8和num4视为重要,但它们也把噪音变量num2包括进来了。 如果只有一种解释性技术发现num2具有局部重要性,那么那种解释技术的有效性需要被质疑。但由于所有三种可解释性工具都将num2视为具有局部重要性,因此更有可能是模型本身认为num2是重要的。 这是可解释性技术能够帮助进行模型调错的一个例子。
尽管使用了验证集和L1和L2正则化,我们的XGBoost模型学到了一个不重要的变量num2在其预测的中位数范围内是重要的。 也许需要更多的训练数据,更多的验证数据,交叉验证,更多或不同的正则化,或者其他措施能够挽救这个问题。 这里的关键是,局部解释技术是发现这个问题所必需的技术,并且所有局部技术一致地给出了“该模型赋予num2太多权重”的结果。 此外,对于中位数预测,正如我们预期的那样,treeinterpreter和Shapley给出数值大致相当的局部正负权重。不过,LIME对所有重要变量都给出了负的局部权重。 LIME在这种情况下失效了吗? 不见得。 我们必须记住,LIME的解释有一个线性截距项的偏移。通过一点深入挖掘,我们可以看到,对于一个GBM给出0.3预测的样本,LIME的模型截距项为0.7。 基于此信息,LIME可能会认为num1,num4,num8和num9是重要的,但给予了它们负的局部权重。
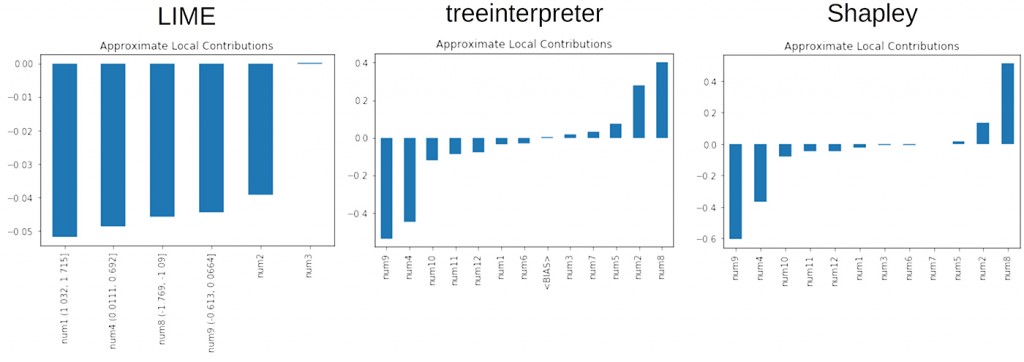
图6.在已知信号生成函数上训练的XGBoost模型的局部变量重要性。 变量num1,num4,num8和num9理应是很重要的。 感谢由H2O.ai提供的图片
我们已经展示了几种解释行为基本正确的情况,但我们有时会发现解释失效了,并且在生产环境应用上捕获和调试这些失效要比在模拟数据上更难。查看我们的Github仓库以参考某些失效的情况,我们讨论过的一些检验的细节,以及使用开源建模和模拟数据解释包来检验解释的更多例子。
除了针对模拟数据进行测试外,我们还采用了一些其他程序的方法来检验机器学习解释,您可能会发现这些解释也很有帮助。
随着预测精度变化,解释的稳定性
如果对于一个简单线性模型,之前存在一个已知的准确解释,我们可以将它们当成一个参照,用于检查一个功能相近,有希望精度更高,但是更复杂的模型。您可以执行检验,查看模型在其预测的解释偏离已知标准之前的仍然具有的准确程度。
在数据扰动下,解释的稳定性
对于输入数据的微小变化,可靠的解释应该不会发生巨大变化。 您可以在解释值允许的范围内,自动化地设置和检验输入数据扰动程度的阈值。
结论
我们在这总结一些重点:检验您的解释工具,使用多种类型的工具来解释您的机器学习模型,并在不同的解释方法中寻找一致性的结果。 此外,请记住,并非所有解释方法和工具都相同。 有些是基于严肃的理论,并且谨慎和严谨地实施。 有些就不是这样。 根据我们过去18个月左右的经验,Shapley给出的解释确实是超越其他方案的一种很好的解释方法,特别是在使用基于树的建模技术时。 LIME似乎是其他类型机器学习模型的最佳选择,不过有时候它表现的有些奇怪。本文中讨论的Shapley,LIME和treeinterpreter只是当今许多可解释技术中的一小部分。 还有许多其他可解释性方法和工具,它们各有利弊;还存在着许多类型的可解释模型,以及关于机器学习可解释性具有自己独特需求的问题和领域。 我们的长报告中更多地介绍了相关主题和内容 ,因此如果这篇文章有用,请务必查看长报告。
机器学习:快速简单的定义:获取机器学习的基本概述,然后通过推荐的资源进行深入了解。








2019年6月18-21日在北京举行的人工智能大会议题征集已经开始。