在这篇文章中,我分享了在2018年3月进行的加利福尼亚州Strata数据会议上所发表演讲,提供了和“公司如何在数据隐私变得关键的时代如何搭建数据分析产品”相关的幻灯片和笔记,它提供了一些建议。自从我发表演讲以来,很多事情已经发生了变化:有关Facebook的隐私政策的文章很多,其首席执行官在美国国会面前作证两次,而且我已经停用了我基本处于休眠状态的Facebook帐户。 最终的结果是,人们对数据隐私的认知极大的提高,并承认,这个问题的影响范围远远超出了少数公司或少数人。
首先,我从列出一些有关数据隐私的观察开始阐述这个话题:
- 我们倾向于在安全漏洞的语境下讨论数据隐私,但在许多情况下隐私侵权涉及被授予数据访问权限的人。
- 我们的连接设备越来越多,这意味着我们最敏感的数据正在被收集和贩卖,参见智能家居的这篇文章。
- 实际上世界各地的监管机构正以不同的方式解决数据隐私问题。更进一步地,许多公司在欧盟开展业务,出台的通用数据保护法规( GDPR )将就“如何搭建和设计数据服务和产品”这一点上对全球的机构造成影响。
这让我想到了本演讲的主题:在数据隐私成为了一个重要问题的时代,我们该如何搭建分析服务和产品? 对数据平台进行架构设计和搭建,是我们许多人所关注的核心问题。 我们早就认识到数据安全和数据隐私是我们数据平台所必需的功能,但我们如何对分析进行限制?
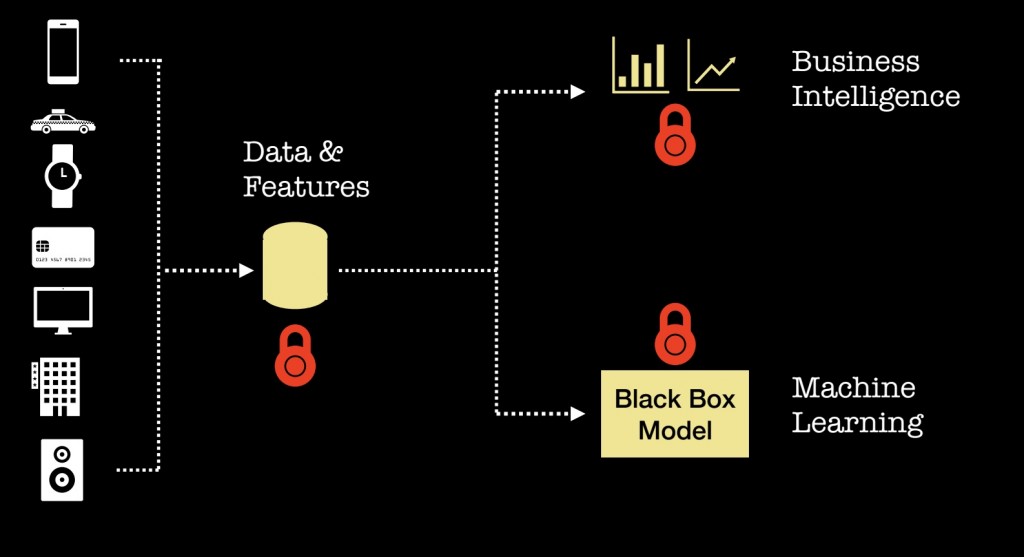
一旦我们安全地获取数据到本地,我们接下来会以两种主要方式继续使用它:(1)做出更好的决策(商业智能)和(2)以实现某种形式的自动化(机器学习)。 事实证明,有一些新工具可用于构建能够保护隐私的数据分析产品。 让我们快速概览一下您今天可能要尝试的一些东西。
商业智能和分析
对于大多数公司而言, 商业智能意味着SQL数据库。 你可以在保护隐私的同时运行SQL查询吗? 已经存在使用硬件孤岛在敏感数据上进行商业智能决策的系统,并且有一些原型系统,允许您查询或使用加密数据 (一位朋友最近向我展示了HElib,一种同态加密的开源、快速的实现 )。 让我来介绍优步与加州大学伯克利分校RISE实验室最近的合作成果。
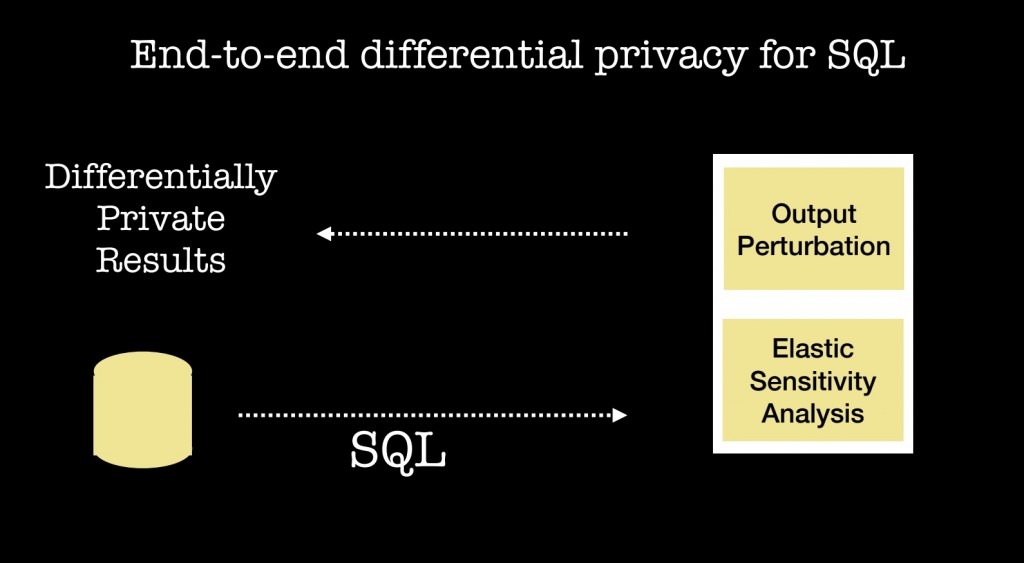
他们对在优步执行的数百万个SQL查询的联合分析导致了一个系统的产生,该系统允许分析师提交查询,在满足最新差分隐私要求的条件下获得结果 (差分隐私形式化地保证了能够提供稳健的隐私保障)。 正如我上面提到的, 隐私侵犯可能涉及被授予访问数据权限的人。 这个新的优步/ RISE实验室系统意味着,分析师可以被授予访问数据库的权限,以进行基于SQL查询的标准分析,同时维持了数据隐私。 他们的系统是开源的,可以与任何SQL数据库一起使用,并且它已经在Uber的试验性部署中开始被使用了(参见论文和代码)。
这将针对那些依赖SQL数据库做出的报告来保护商业智能。不过,有可能构建一个既能保护隐私,又能收集数百万用户的实时数据的系统吗? 回答是肯定的:在最近Apple和Google的发布中,详细描述了如何设计分析工具,以帮助他们理解“用户如何和设备进行交互”。例如,Apple和Google的分析师可以运行查询,以帮助他们收集输入法的统计信息,以及浏览器上的行为。

苹果在一篇非常详尽的博客文章中描述了他们的系统:
我们的系统的设计是,“可以选择性加入”以及“透明”。 在用户明确选择上报使用信息之前,不会对数据进行任何记录或传输任何数据。 在用户的设备上,数据是使用本地模型中的事件级差分隐私进行了隐私保护的。这里的事件,举例来说,可能是用户键入的emoji表情符号。 此外,我们限制每个用例传输的私有化事件的数量。 到服务器的传输每天在加密通道上进行一次,没有设备标识符。 记录到达限制访问服务器,其中IP标识符立即被丢弃,并且多个记录之间的任何关联也被丢弃。 此时,我们无法区分,例如,表情符号记录和Safari Web域记录是否来自同一用户。 处理记录以计算统计数据。 然后,这些汇总统计信息将在内部与Apple的相关团队共享。
微软等其他公司正在开发涉及其他智能设备的类似系统 。
机器学习
对于机器学习而言,让我先聚焦于最近涉及深度学习的工作(目前最热门的机器学习方法)。 2015年德克萨斯大学和康奈尔大学的研究人员表明,人们可以“设计、实施和评估一个实用系统,使多方能够共同学习一个给定目标的准确的神经网络模型,而无需共享他们的输入数据集。” 一种潜在的应用是,一些医疗机构在无需向机构外部人员共享数据的条件下,希望构建、学习一个更加准确的联合模型。
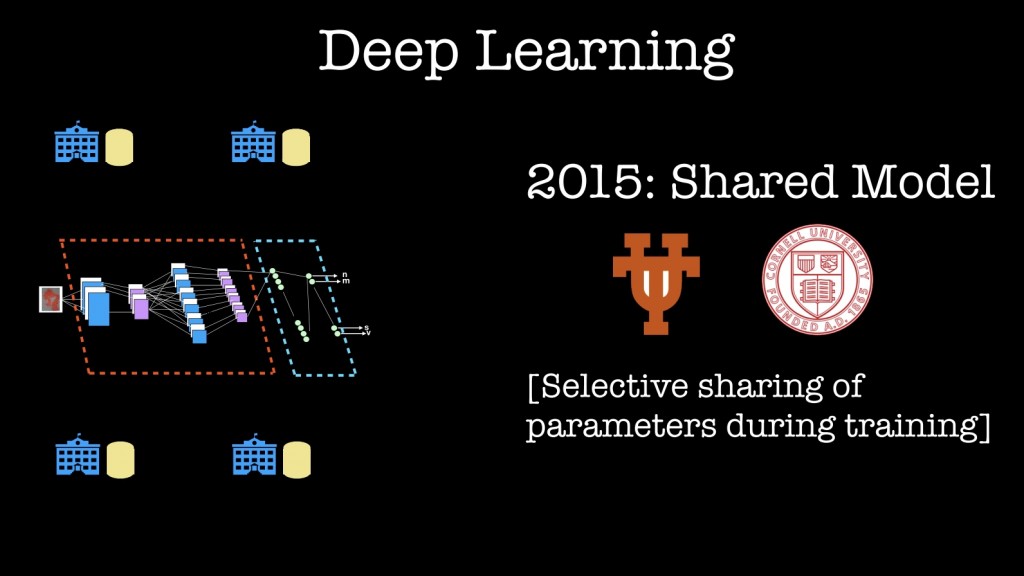
2016年,Google采用了这种“共享模型”概念,并将其扩展到边缘设备! 他们将其用于设备上的智能回复和他们的移动端视觉识别接口等产品。这个新产品被他们称之为“联合学习”,能够将训练数据分发到移动设备上,再把本地计算的更新进行汇总,学习一个共享模型。

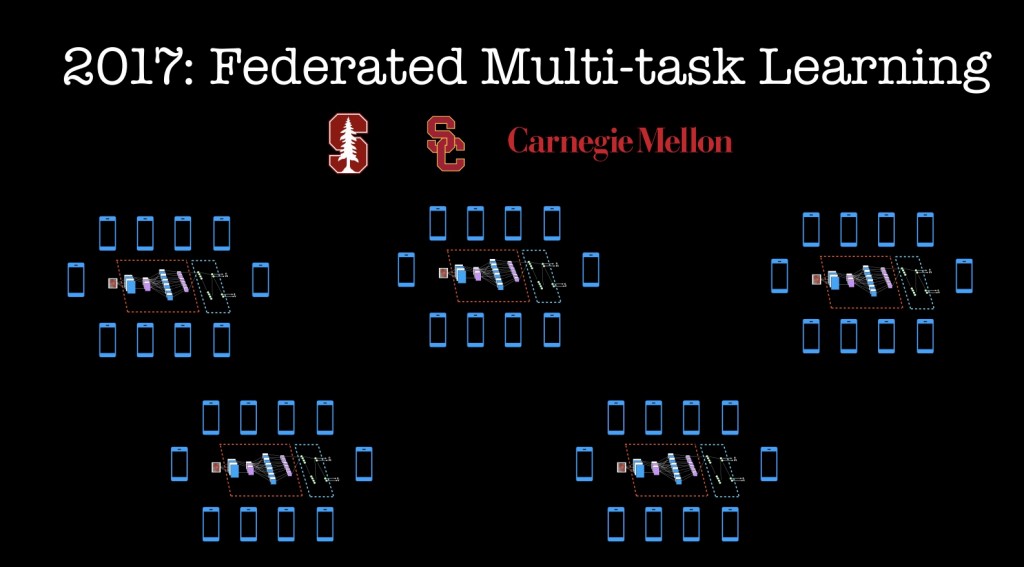
前两个例子涉及学习一个共享的(单)模型,而不共享数据。 在某些情况下,您可能需要高度个性化的模型,或者您可能天然拥有(人口学/使用上的)你的用户群体,这个群体可以从专门调整过的模型中受益。 这些情景是斯坦福大学、CMU和南加州大学研究人员近期工作的重点:他们使用多任务学习的思想来训练个性化的深度学习模型。 在多任务学习中,目标是考虑同时拟合独立而相关的模型。
结束语:一些思考
我主要想传达的信息是,无论是对于商业智能而言,还是对于机器学习而言保护隐私的分析是非常可能实现的,也您今天应该考虑做的一件事之一 。这不仅是为您的用户做的正确的事情,随着GDPR上线隐私成为您的数据产品中所必需要包含的东西:
从本质上讲, 隐私设计要求在系统设计开始时具备数据保护能力,而非作为一个可添加的模块。
最后一件要强调的是:我非常关注的两个技术趋势是自动化(AI)和去中心化(区块链,密码学,等等)。 有些人积极地致力于重建关键服务 —— 身份管理,数据存储,支付,数据交换,社交媒体 —— 以及将它们从中心化的系统中移除。 我相信,数据科学和大数据社区能够居其位谋其政,为自动化和去中心化两个方面同时做出贡献。 我们的社区花了数年时间致力于将重要的组件推向生产环境,这些组件包括机器学习和分布式系统,它们将继续作为未来平台的核心而存在。
相关内容
- “我们需要建立机器学习工具来强化机器学习工程师的能力”
- “人工智能的伦理”
- 您的数据正在被操纵:danah boyd探讨了系统如何被游戏化,数据是多么脆弱易受攻击,以及我们需要做些什么来构建技术抗体
- “现在是时候在晚餐桌上进行关于数据伦理的讨论了”
- 受数据困扰:Maciej Ceglowski提出了能够采纳可执行的数据存储上限的场景。

Ben Lorica
Ben Lorica是O’Reilly Media的首席数据科学家和数据主题内容策略的主管。他已经在多个领域里(包括直销市场、消费者和市场研究、精准广告、文本挖掘和金融工程)进行了商业智能、数据挖掘、机器学习和统计分析的工作。他之前曾效力于投资管理公司、互联网创业企业和金融服务公司。





