这是本系列博客的第三篇,也是最后一篇。这个系列之前的博客比较了两个主要的开源自然语言处理软件库:John Snow Labs的Apache Spark-NLP和Explosion AI的spaCy。在前两篇中,我带着读者一起过了一下训练分词和POS模型的代码,然后在一个基准数据集上运行了这些代码,并评估了一下结果。在这一篇中,我会比较这两个库在其他基准测试上的准确性和性能,同时也会给出这两个库在哪些应用场景里比较适合的建议。
准确性
以下是本系列的第一篇中训练的模型的准确性比较。
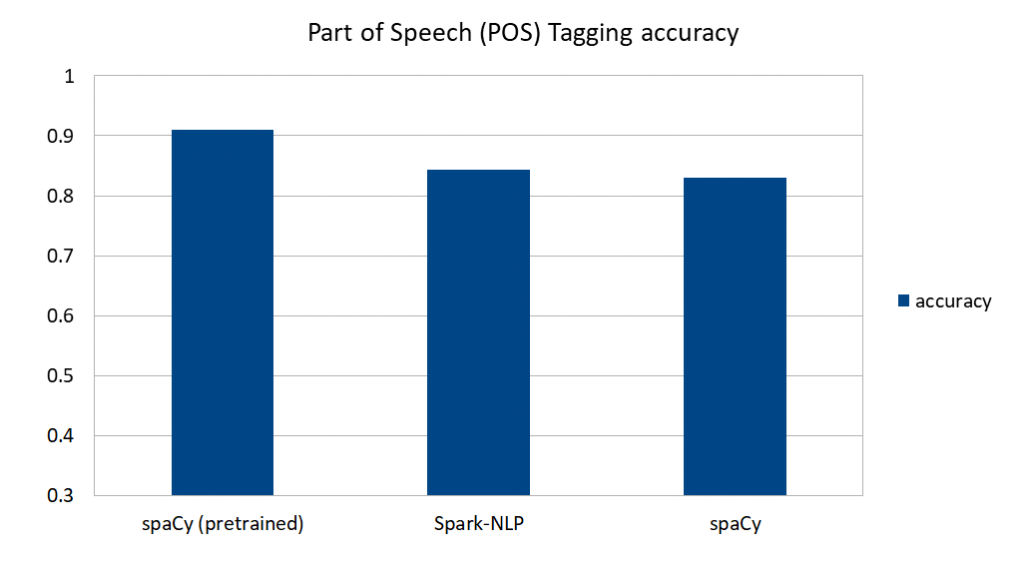
图1 模型的准确性比较。图片由Saif Addin Ellafi提供
spaCy的预先训练模型在预测英语文本中的词性标记(POS)方面做得很好。如果你的文本是标准的、基于新闻或文章的文本(例如,不是像法律文件、财务报告或医疗记录这样的专业领域的文本),并且是spaCy支持的七种语言之一写成的,用spaCy的预先训练的模式是一个很好的方法。需要注意的是,我的预先训练的模型里包括我自定义的分词器,否则精度(特别是分词的匹配率)将下降(参见图2)。
spaCy自带的预训练模型和Spark-NLP在使用相同训练数据时的表现相似,准确率都在84%左右。
对spaCy的准确性的主要影响似乎不是来自于训练数据,而是来自于其英语vocab的内容。Spark-NLP对语言没有任何的依赖(它是完全语言不可知的),而且只从管道里的标注器中学习。这意味着相同的代码和算法,在训练另外一种语言的数据时,不用改变。
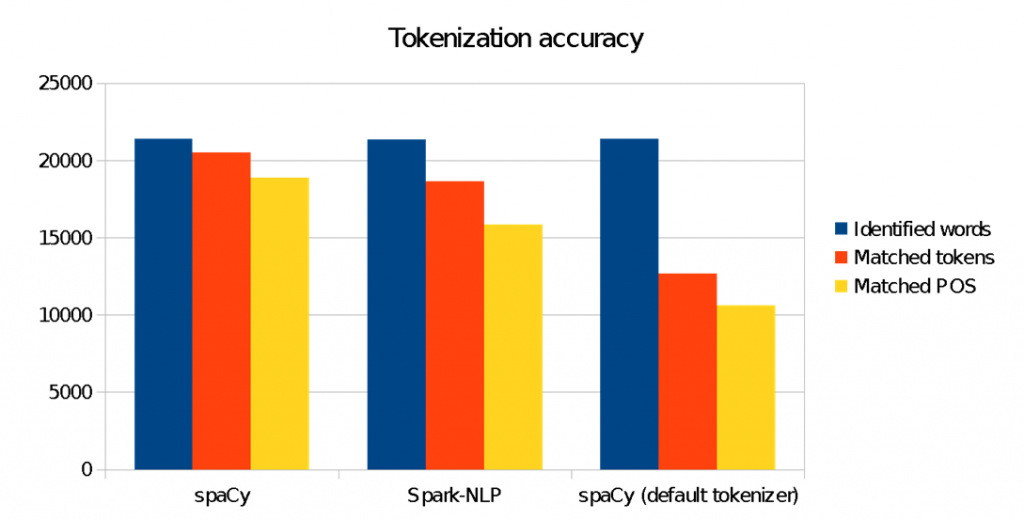
图2 分词的准确性比较。图片由Saif Addin Ellafi提供
我们在这里看到,对spaCy分词器的修改对匹配目标ANC语料库的分词造成了重要的影响。使用“开箱即用”的spaCy将会有比较差的结果。这在自然语言理解中非常常见,必须训练特定领域的模型才能学习输入文本里的细微差别、上下文、专业俚语和语法。
性能
训练并预测大约77KB的txt文件(对21000个单词进行预测和比较)时,一切看起来都挺好的。但当我们训练的文件数量增加到原来的两倍,预测9225个文件而不是14个文件时,事情看起来就不那么好了。当然,从任何维度来看,这都不是“大数据”,但却比玩一玩或调试更贴近现实场景。下面是结果。
Spark-NLP 75mb prediction
Time to train: 4.798381899 seconds
Time to predict + collect: 311.773622473 seconds
Total words: 13,441,891
用spaCy进行训练有点麻烦,因为训练数据里有一些奇怪的字符和文本格式的问题,我已经在之前的训练算法中进行了清理。但在使用了这些规避方法后,训练的时间出现了指数级的增加,所以我只能估计可能需要的时间。基于扩展后的训练文件夹中的文件的数量,训练时间大约是两小时或更多。
SpaCy 75mb prediction
Time to train: 386.05810475349426 seconds
Time to predict + collect: 498.60224294662476 seconds
Total words: 14,340,283
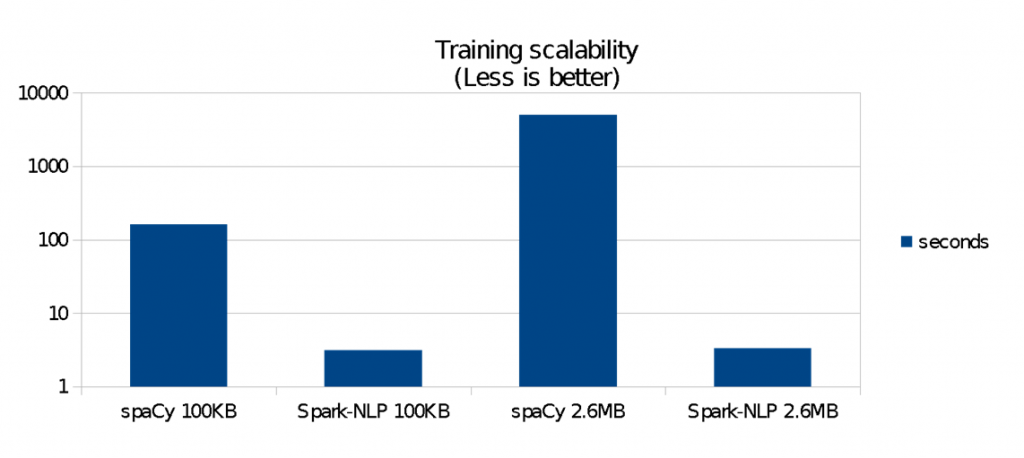
图3 训练的可扩展性。图片由Saif Addin Ellafi提供
图3显示了在这个75MB的基准上的结果:
- 相比spaCy,Spark-NLP在100 KB数据上的训练速度快38倍,在2.6 MB的数据上的速度快80倍。可扩展性上的区别是显著的。
- 当数据从100 KB增加到2.6 MB 时,Spark-NLP的训练时间没有显著地增长。
- spaCy的训练时间在数据量变大的时候呈指数增长。
图4显示了运行Spark-NLP管道时(即在训练阶段结束后使用模型进行预测)的性能比较。spaCy在小数据集上是很快,但是它不像Spark-NLP那样扩展性良好。对于这些基准测试:
- spaCy在140 KB数据集上更快(两个库都在不到1秒内完成)。
- 在15 MB数据集上,Spark-NLP快1.4倍 (约40秒对70秒)
- 在75 MB数据集上,Spark-NLP快1.6倍,用了大约spaCy一半的时间完成(大概5分钟对9分钟)
spaCy针对单机运行进行了高度优化。它用Cython从零开始编写,并在2015年(Spark-NLP出现之前两年)就被证明比用Python、Java和C++编写的其他库具有最快的语法解析器。spaCy没有像Spark-NLP那样的JVM和Spark开销,这使得spaCy在小数据集上具有优势。
另一方面,Spark多年来所做的大量优化(尤其是对于单机、standalone的模式)在这里发挥了重要作用,即使数据集只有几兆字节。自然,随着数据量的增长或管道复杂性(例如,更多自然的语言处理阶段,加入机器学习或深度学习的阶段等)的增加,这种优势会更加明显。
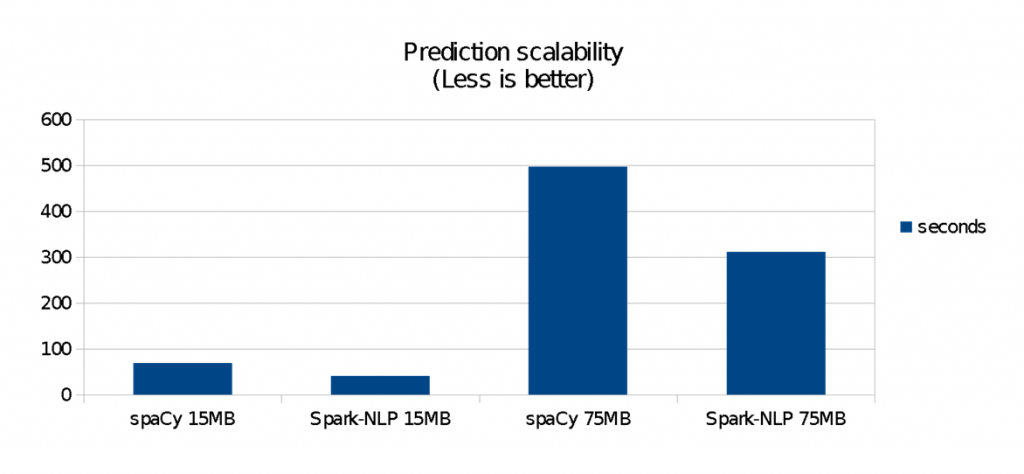
图4 运行时性能的比较。图片由Saif Addin Ellafi提供
可扩展性
在这些基准之外,Spark按自身的方式进行扩展。可扩展性的好坏取决于如何划分数据,是否有宽表或高表(后者在Spark中更好),最重要的是,是否使用集群。在这里,所有的数据和代码都在本地机器上。我对文件名运行了groupBy操作,这意味着我的表的宽比高要大,因为对于每个文件名都有大量的单词。如果可以,我可能还会避免调用collect()操作,这会严重影响我的driver程序内存,不如将结果存储在分布式存储中。
transform()操作后的groupBy操作是在预测之后进行POS和分词的合并。它变换一个比前一个表高得多的表(960302行,而不是表示文件的数量的9225行)。我还可以控制是否将CPU内核过度分配给Spark(例如,local[6])以及向转换操作中注入的分区数量。在调试Spark性能时,性能通常呈现出正态分布。在我的例子中,最优的情况大概是分配6个核和指定24个分区。
在spaCy方面,我在前几段中使用的并行算法并没有显著地影响性能,而只是让总的预测时间少了几秒钟。
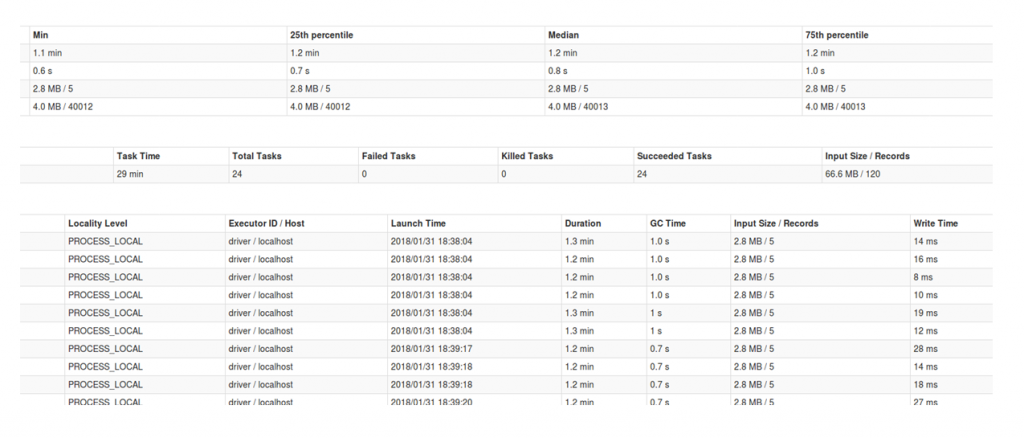
图5 并行算法的影响不显著。图片由Saif Addin Ellafi提供
使用一个Amazon EMR集群,对相同算法进行简单的比较。相对单一节点,使用一个分布式yarn管理的集群,POS预测的速度提升了2.5倍。集群中的数据集被放在HDFS中。在实际情景里,这意味着仅仅依靠调整配置和线性扩展即可以实现不同的成本/性能权衡。这是Spark、Spark ML和Spark-NLP的核心优势。
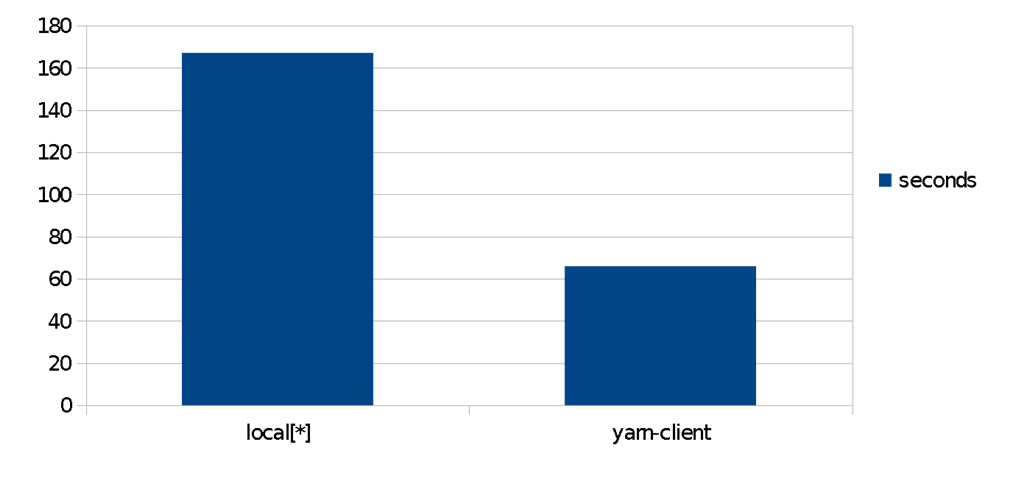
图6 使用亚马逊EMR集群的比较。图片由Saif Addin Ellafi提供
结论
这两个库的应用场景是非常不同的。如果只是使用一个小数据集并想快速获得输出,那么spaCy是赢家。可以下载它的某个自然语言的模型,处理数据,并将其逐行传递给NLP对象。spaCy包含了大量关于自然语言的策略词汇集,以及一系列经过训练的非常先进的模型。这些模型拥有用C++ (Cython) 高度优化的性能。如果想要并行化任务,可以定制一个组件(就像我们为分词器所做的那样),或者为特定领域的数据训练一个模型,接着利用spaCy的API来编写更多的代码。
另一方面,如果你有一个很大的任务,那么Spark-NLP就会非常快。并且从一定的规模开始,它是唯一的选择。当使用更大的数据集或扩展Spark集群时,它会自动扩展。对于训练NLP模型来说,它的速度比spaCy快1到2个数量级,同时能保证同样的准确度。
spaCy为各种常见的NLP任务提供了一组超级优化的模型。Spark-NLP没有(在撰写本文时)预先训练好的模型。spaCy的模型是“黑盒子”,如果你自己的文本数据和模型的训练内容相似的话,结果表现通常会在顶尖的1%以内。当使用Spark-NLP训练特定领域的模型时,管道是语言不可知的,最终的结果严格地说是各部分的总和。每个注释器都根据被提供的知识进行工作,每个注释器都将与其他注释器进行通信,以实现最终的结果。你可以加入一个拼写检查器、一个句子检测器或一个正归化器,并产生结果,而不必编写额外的代码或自定义脚本。
我们希望你喜欢对这两个库的概述,它将帮助你更快更好地交付下一个NLP项目。如果你有兴趣学习更多的话,可以在查看2018年3月的Strata数据圣何塞大会和5月的Strata数据伦敦大会上进行的为期半天的“使用spaCy和Spark ML进行大规模自然语言理解”的课程。
相关资料:

Saif Addin Ellafi
Saif Addin Ellafi是一名软件开发者、分析师、数据科学家,并永远是一名学生。他同时还是一名极限运动和游戏爱好者。他在银行和金融行业的数据领域拥有丰富的解决问题和测试的经验。现在他在John Snow Labs,并是Spark-NLP的主要贡献者。





