在处理序列数据(如自然语言处理任务)这类问题时,递归神经网络(RNN)通常是首选方法。 尽管RNN的时间序列性质与文本数据相关的问题是天然匹配的,但是在处理视觉任务中曾获得巨大成功的卷积神经网络(CNN)在这些问题上也同样有效。
在我们的LSTM教程中,我们深入了解了长短期记忆模型(LSTM)的工作机制,并使用TensorFlow构建了一个多层LSTM网络,通过社交媒体信息对股市情绪进行建模。 在这篇文章中,我们将简要地讨论如何将CNN应用于文本数据,同时提供一些示例TensorFlow代码来构建CNN,以执行与我们的股票市场情绪模型类似的二分类任务。
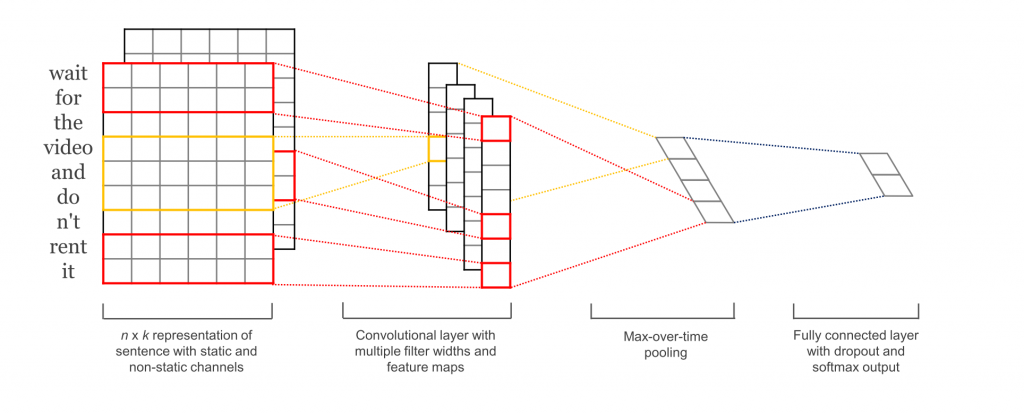
图1.用于文本分类的示例CNN模型结构。Garrett Hoffman提供图片,来自于论文《用于句子分类的卷积神经网络》
我们在图1中,看到了一个用于文本分类的样本CNN网络结构。首先,我们从输入句子(长度为seq_len)开始,它表示为一个矩阵,其中行是我们的词向量,列是分布式词嵌入。 在计算机视觉问题中,我们通常会看到RGB的三个输入通道;不过,对于文本我们只有一个输入通道。 当我们在TensorFlow中实现我们的模型时,我们首先为输入定义占位符,然后建立词嵌入矩阵和嵌入查找表。
# Define Inputs
inputs_ = tf.placeholder(tf.int32, [None, seq_len], name=’inputs’)
labels_ = tf.placeholder(tf.float32, [None, 1], name=’labels—)
training_ = tf.placeholder(tf.bool, name=’training’)
# Define Embeddings
embedding = tf.Variable(tf.random_uniform((vocab_size, embed_size), -1, 1))
embed = tf.nn.embedding_lookup(embedding, inputs_)
注意CNN如何将输入作为一个完整的句子来处理,而不是像LSTM一样逐字地处理。对于CNN,我们将句子中所有单词索引的张量传递给我们的词嵌入查找表,并针对句子将返回的矩阵用作我们网络的输入。
现在,我们已经拥有了输入句子的嵌入表达,我们构建了卷积层。在我们的CNN中,我们将使用一维卷积,而不是通常用于视觉任务的二维卷积。我们将只定义一个高度,而不是为我们的卷积核定义一个高度和一个宽度,宽度总是嵌入维度。与图像在CNN中的表现方式相比,这是非常直观的。当我们处理图像时,每个像素都是一个分析单位,这些像素存在于我们输入图像的两个维度上。对于我们的句子,每个单词都是一个分析单位,用我们的词嵌入维度(我们的输入矩阵的宽度)表示,所以单词只存在于我们的”行”这一单一维度中。
我们可以使用尽量多的一维卷积核,而且我们喜欢不同的大小。图1显示了大小为2的卷积核(红框输入)和大小为3的卷积核(黄框输入)。我们还为每个图层定义了统一数量的卷积核数量(与我们对于二维卷积图像采用相同的方式),这将是卷积的输出维数。我们使用relu激活函数,并为我们的输出添加一个时间轴上的max-pooling (极大值池化),使每次卷积时,从每个卷积核中获得最大输出,每个卷积核中提取单独的模型特征。
# Define Convolutional Layers with Max Pooling
convs = []
for filter_size in filter_sizes:
conv = tf.layers.conv1d(inputs=embed, filters=128, kernel_size=filter_size, activation=tf.nn.relu)
pool = tf.layers.max_pooling1d(inputs=conv, pool_size=seq_len-filter_size+1, strides=1)
convs.append(pool)
我们可以将这些卷积层看作是“并行的” ,即一个卷积层不会再把输入送进下一层,它们都接受相同的输入,得到独立的输出,我们对其拼接,得到结果。
# Concat Pooling Outputs and Flatten
pool_concat = tf.concat(convs, axis=-1)
pool_flat = tf.layers.Flatten(pool_concat)
然后,我们现在用一个Sigmoid函数激活来构建一个全连接层,以便用我们拼接的卷积输出预测。 请注意,如果问题是多于两类的分类问题,我们也可以在这里使用tf.nn.softmax激活函数。 我们在这里还包括一个Dropout层来对模型进行正则化,让模型获得更好的泛化性能。
drop = tf.layers.Dropout(inputs=pool_flat, rate=keep_prob, training=training_)
dense = tf.layers.Dense(inputs=drop, num_outputs=1, activation_fn=tf.nn.sigmoid)
我们可以使用model_fn将这些代码封装到一个自定义的tf.Estimator中,制作一个简单的用于模型训练,模型评估和做预测的API。
现在我们就有了“用于文本分类的卷积神经网络结构”。
与任何模型间比较相似的是,CNN和RNN之间在文本分类方面互有胜负。尽管RNN似乎是语言的一种更为自然的选择,但是CNN被证明训练速度比RNN快5倍,并且在特征检测非常重要的文本上表现良好。然而,当对输入序列的长期依赖性是重要因素时,RNN变体通常优于CNN。
最终,不同研究领域的语言问题会有所不同,因此在您的库中使用多种技术是非常重要的。这只是我们在不同研究领域成功应用趋势性技术的一个例子。虽然卷积神经网络传统上一直是计算机视觉世界的明星,但是我们开始看到将它们应用于序列数据时,会有更多突破。
这篇文章是O’Reilly和TensorFlow的合作。在此查看我们的编辑独立性声明。





