强化学习(RL)是关于训练智能体来完成一些任务。一般认为这能够达成某个目标,例如,我们可能想要训练机器人来打开一扇门。强化学习可以作为一个框架,允许机器人用试错的方法来学习打开门。但是,如果我们更感兴趣的是让智能体不仅只是解决一个目标,而是一个可能随时间变化的目标集合,又会怎么样呢?
在本文以及GitHub上对应的notebook文件中,我将介绍和演示机器学习中传统的强化学习范式,以及一种新出现的用于扩展强化学习的范式,它可以应对复杂的随着时间变化的目标。
首先,我将演示如何构建一个简单的Q-learning智能体,它由一个单一的奖励信号为引导,在一个环境里自我导航来投递包裹。然后我将展示Q-learning这个简单的公式在更复杂的行为情况下会出现的问题。为了获得更大的灵活性,我将描述如何构建一类强化学习智能体,它可以对 “直接未来预测”(DFP)的各种目标进行优化。所有使用TensorFlow的代码都在这个iPython Jupyter Notebook文件中。
能获得最大累积奖励的Q-learning
强化学习涉及到智能体通过和环境进行交互来随着时间的推移获得最大的回报。典型的形式化这一过程的方式是:一个智能体从环境中接收一个状态(s),再产生一个动作(a)。给定这个状态和动作对,环境就会反馈给智能体一个新的状态(s)以及一个回报(r)。这样强化学习的问题就变成了如何发现一个从状态到行为的映射,从而能产生最大的累积奖励的问题。
解决问题的一种方法叫做Q-learning。在这个方法中,我们学习一个状态动作对(s,a)和值估计(v)之间的直接映射。这个值估计应该与在状态(s)期间采取行动(a)的折扣预期奖励相对应。使用Bellman方程,我们可以迭代地更新对所有可能状态动作对的Q(s,a)的估计。这种迭代更新Q值的能力来自于优化Q函数的以下特性:
Q*(s, a) = r + γmaxa’Q(s’, a’)
此公式意味着给定状态和动作的当前Q值可以分解为当前的奖励,加上下一状态下的预期未来奖励。通过收集经验,我们可以训练一个神经网络来预测更精确的Q值,并且通过采取行动来优化期望值。在理想情况下,最终我们可以根据环境获得最大的累积奖励。利用一个通用的函数逼近器(如神经网络),我们可以将我们的Q估计泛化到未见过的状态,从而使我们可以学习任意大的状态空间的Q函数。
基于目标的强化学习的快递无人机场景
Q-learning和其他传统的公式化的强化学习算法都是只学习一个单一的奖励信号,因此一次只能应对一个单一的“目标”。例如,我们希望一架无人机学习如何将包裹投递到城市各个地点。这个“快递无人机”的场景将是下面我们在讨论基于目标的强化学习的指导范式。
在这种环境中,智能体在5×5的网格中占据一个位置,而快递目的地占据另外一个位置。该智能体可以在任意四个方向上移动(向上、下、左、右)。如果我们想让无人机去学习投递包裹,我们只需要在无人机成功地飞到一个标记的位置并进行投递后,给一个+1的正奖励即可。

图1.简单的无人机快递环境的渲染。来源:Arthur Juliani
图1所示的内容可以用来帮助我们直观地理解智能体正在学习什么。我们使用一个简单的状态表示,即一个5×5的网格和RGB像素(总共75个值)来表示这个环境。这把使用一台笔记本电脑来进行训练学习的过程从数小时降到几分钟。每一循环无人机走100步。在每一循环的开始,我们会随机分配智能体和投递的地点。
使用TensorFlow进行Q-learning
下面所示的Q-learning的TensorFlow的实现是该算法的一个异步版本。它允许多个智能体并行地学习。这种方法同时加速了训练的过程和健壮性。实现的代码在这个Jupyter Notebook文件里。
使用由4个worker的机器进行训练。在每个worker进行6000次循环的训练后,我们最终得到的性能曲线应该类似于图2所示。智能体在每次循环可以持续投递大约20个包裹。考虑到我们这个环境的尺寸大小,可以认为这是在100步中近似最优投递数量。点击这里观看动画演示。
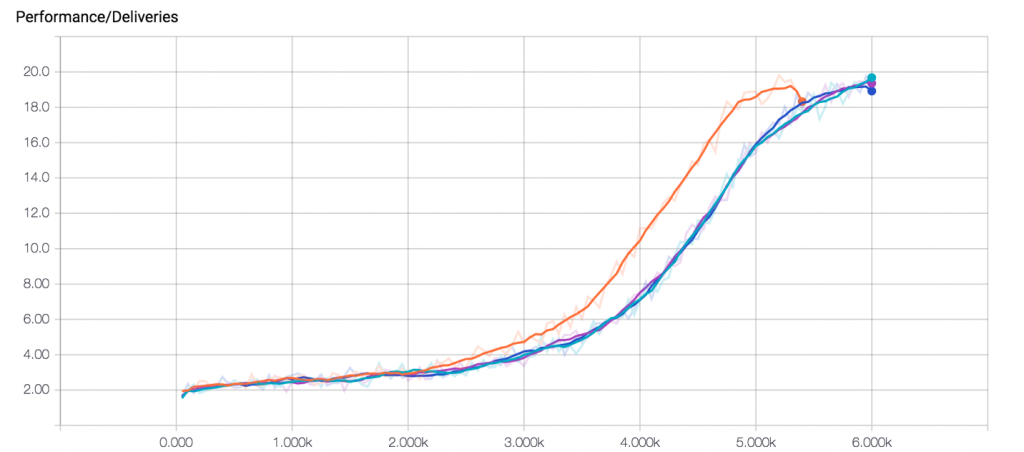
图2.性能曲线。在4个worker上每个worker进行6000次循环后的表现。来源:Arthur Juliani。
直接未来预测
一个真实世界中的无人机并不能无休止地投递包裹,因为它的电池容量是有限的,需要经常性地充电。每次移动,智能体的电池电量都会略有下降。因为电池容量有限,耗尽电量就意味着从空中掉下来,不再能够递送包裹——没有投递更多的包裹就意味着没有更多的奖励。
我们可以在环境中增加一个位置,让我们的智能体飞到这个位置来给它的电池充电。现在所有的智能体都需要在电池电量不足时,学会飞到充电站去充电,其他时候就正常地投递包裹。
创造一个最优的奖励函数
在有足够的时间和正确的超参数调优的情况下,Q-learning算法可能最终会发现,对电池充电有利于在长期内投递更多的包裹。这涉及到要学习采取一系列复杂的没有立刻的奖励的行动,并学会理解更大的奖励在后面。在这种情况下,增加鼓励电池奖励行为的信号是一个诱人的选择。一种简单粗暴的方法可以是提供一个奖励(比如+0.5)给飞行到指定的位置充电。然而在这种情况下,我们的智能体会学到的是总飞去充电,因为每次充电的时候都保证有奖励。我们现在遇到的问题是想出一个奖励函数来描述我们认为最优的行为。虽然对于一些问题来说这很简单,但不正确的奖励函数却常常会带来意想不到的后果。想看一些例子的话,可以看看最近的这篇OpenAI的文章《Faulty Reward Functions(有缺陷的奖励函数)》。
改变目标
如果我们想要避免有缺陷的奖励工程的坑,我们需要一个更直观的方式来将任务的结构传达给智能体。事实证明,通过给智能体提供一个明确的同时也能根据事件和特定的时刻变化的目标,我们可以更好地得到我们想要的动态行为。在考虑电池的情况下,只要电量低于一定的值,我们就可以把目标从“投递包裹”改为“给电池充电”。这样我们就不用担心奖励方程,神经网络可以只专注于学习环境的动态本身。
图3.在加入电池充电情况下的投递环境。来源:Arthur Juliani
形式化目标搜索
为了使这个概念可行,我们需要让描述更正式一些。在强化学习中,实现目标的形式有多种。我关注的是在2017年International Conference on Learning Representations会议上发表的一篇论文。这篇论文的题目是《Learning to Act by Predicting the Future(通过预测未来来学习行动)》。而这正是我们想要训练我们的智能体去做的事情!
首先,有一点需要申明的是,这里展示的模型并不完全是论文作者——Alexey Dosovitskiy和Vladlen Koltun在他们的论文中描述的内容。在论文中,他们将其网络称为“直接未来预测”(DFP)。我们所做的类似于DFP。我调整了一些因素,以使它们对本文中讨论的例子更加直观。
在原论文中,作者训练他们的智能体去玩第一人称射击游戏“Doom”。这是一个令人印象深刻但比本文介绍的内容更复杂的环境。
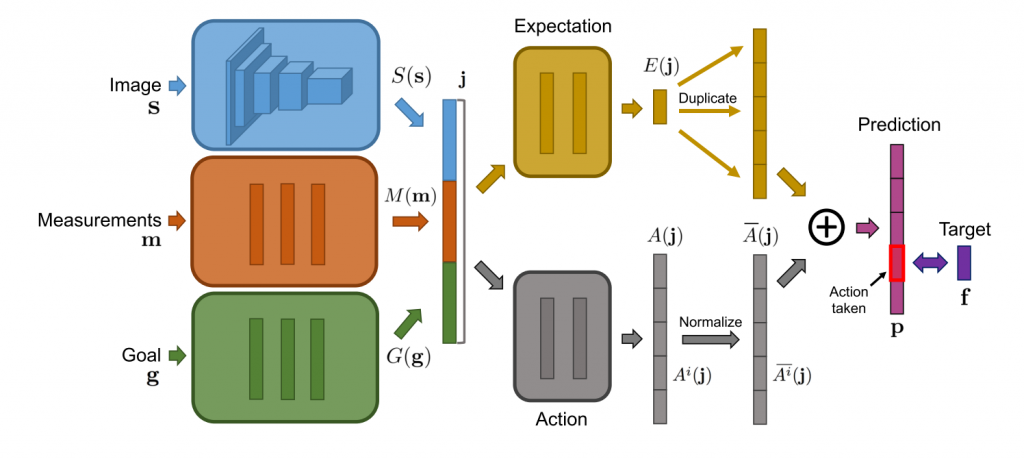
图4.“直接预测未来”的网络架构图。来自论文Dosovitskiy and Koltun (2016),授权使用
这里我们并不是训练智能体去完成状态(s)到Q值估计Q(s,a)的映射,然后获得环境反馈的奖励(r)。相对的,在状态(s)之外,我们还维护了一套测量(m)和目标(g),然后训练网络来预测每个行动(a)导致的未来测量(f)的变化。
训练我们的网络来预测期望的未来
在无人机场景里,我们需要维护两个测量值:电池剩余电量和投递的包裹数量。我们没有预测像Q-learning这样的值函数,而是训练网络来预测在未来的1、2、4、8、16和32步后期望的电量的和投递数量的变化。这可以写成公式:
f=<mT1–m0,mT2–m0…mTn–m0>
其中,T是我们的时间偏移量列表,[1, 2, 4, …等]。
在这个范式中,不再有明确的奖励。相反,衡量成功与否的标准是目标和测量的一致程度。在投递无人机的场景下,这将意味着最大化投递包裹的数量和确保电量低的时候去充电。
如果我们的智能体在预测行为的未来测量方面是完美的,那么我们只需要采取优化我们感兴趣的测量值的操作。我们的目标允许我们在任何给定的时间指定我们关心的测量值。
制定更复杂的目标
由于我们并不是简单地预测像Q-learning中的单个标量值,我们可以制定更复杂的目标。设想我们有一个测量向量[电池,投递]。如果我们想要最大化电池电量而忽略投递,那么我们的目标向量将是[1,0],这会对应于未来电池的正测量值,而不在乎投递量。
但如果我们是想最大化投递量,我们的目标向量就会是[0,1]。因为是我们(而不是环境或网络本身)制定了目标,我们就可以随时按照我们认为合适的那一步去改变它。通过这种方式,只要电池测量低于某个阈值(在我们的例子中是30%),我们就可以明确地从优化投递量改变目标为优化剩余电量。通过这种方式结合目标和测量,我们现在可以基于人类操作员的愿望,随时灵活地调整智能体的行为。这与Q-learning相反。在Q-learning中,Q值在经过训练就是固定的,只有一种行为模式是可能的。
这个新公式以几种方式改变了我们的神经网络。不仅只有一个状态,我们还会提供给网络当前的测量和目标作为输入。我们的网络现在将输出一个形式为[测量 X 行动 X 偏移量]的预测张量,而不再是Q值。通过计算预测未来的变化的和与目标乘积,我们可以选择最能满足目标的行动:
a=gT∗∑p(s,m,g)
其中 ∑p(s,m,g)是对未来时间步骤的网络输出的求和,也是目标向量的转置。
通过利用简单的回归损失来预测未来的真实测量变化,我就可以训练这种新型的智能体:
Loss=∑[P(s,m,g,a)−f(m)]2
其中P(s、m、g、a)是指所选动作的网络的输出。
到此我们总结一下。我们有一个智能体可以熟练地投递包裹,并同时维持一定的电量。我们将再次使用在TensorFlow中的异步实现。可用的模型notebook文件可以在这里下载。
用TensorFlow的异步实现
在每个worker(共4个worker)进行了1万次循环训练后,我们最终得到了如图5所示的训练曲线。该智能体已经学会了保持一定的电量 (平均每一循环的长度接近100步),以及在一次循环中提供近乎最优的包裹投递数量。点击这里观看动画演示。
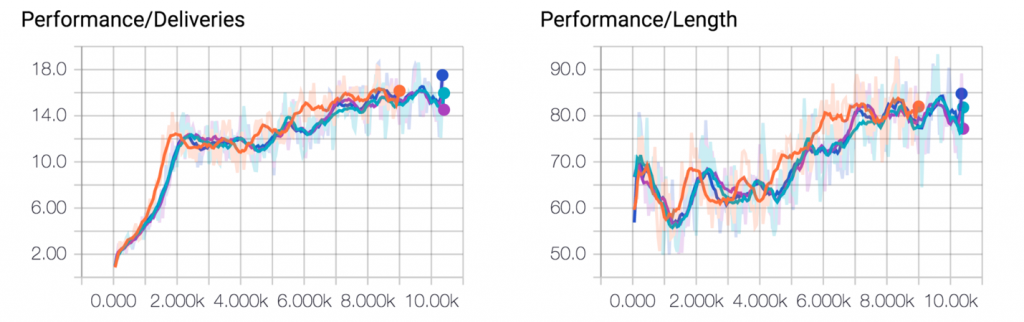
图5.每一循环的投递量(左图),和每一循环里的步骤数(右图)。来源:Arthur Juliani
需要注意的是,这里提供的环境是真实世界场景的一个非常简化的版本。一个网格化的环境可以让网络在一个合理的时间内完成训练,从而达到演示目标学习的目的。现实世界中的无人驾驶机很可能会利用平滑、连续控制,而这显然是一个视觉上更加复杂的世界。
增强这一技术
如果您能够接触到更强大的计算资源,我鼓励你尝试使用更复杂的环境,例如OpenAI universe提供的环境。一个简单的变化是通过使用卷积层来为视频流提供一个更好的编码器,而不是使用本文里用的全连接层。但是,基本的架构应该是可扩展的。
我希望本教程能够为读者了解强化学习能够解决的各种问题提供一些见解,以及在新环境中重新制定任务所带来的好处。这里描述的多目标方法可能并不是在所有情况下都是最好的方法,但是它提供了另一种可能的方法来设计智能体去应对世界上复杂的任务。
这篇博文是O’Reilly和TensorFlow的合作产物。请阅读我们的编辑独立声明。






{kind=link}
{kind=link}
更多人工智能内容请关注2018年4月10-13日人工智能北京大会。