情感分析是数据科学界里一个常见的任务。一个企业可能想监控它的产品在Twitter或是Facebook上被提及的次数,从而能主动察觉(和解决)客户满意度的问题。但是人类的语言是丰富和复杂的,对一些东西有异常多的方式表达正面和负面情绪。反过来,对每种感情也有非常多的表述的方式。在众多的情感分析的机器学习技术里,深度学习已经被证明是能极好地理解这些复杂的内容了。
在本教程里,我们将会使用Apache MXNet构建一个神经网络来对情感进行分类。最终,我们会构建一个分类器,使用电影评论作为输入,试图去识别出对于它所评论的电影是有正面还是负面观点。我们会从一个简单的密集连接模型开始,然后会构建一个和Yoon Kim的这篇论文里类似的卷积网络架构的模型。我们还会使用t-sne这一展示高维数据的技术来可视化输出结果。在最后,我们将会使用迁移学习技术。我们会使用预先建立好的词向量模型glove到我们的神经网络里来分类句子。虽然有非常多的深度学习的框架,例如TensorFlow、Kera、Torch和Caffe,但我们会使用Apache MXNet。因为MXNet的灵活性和跨多GPU的扩展性,它正变得流行起来。
我强烈建议你下载这些Notebook文件。其中有我写好和运行通过的代码。去尝试它们!调整一些超参数,对神经网络架构或是数据准备过程试验不同的方法,看看你能否在准确度上超过我。
Notebook文件里面的内容要求你对卷积运算、神经网络、激活单元、梯度下降和Numpy库有基本的理解。
在学习完本文的内容后,你将能够:
1.理解情感分析的复杂性。
2.理解词向量和它的应用。
3.为训练神经网络准备数据集。
4.为使用不同的模型进行情感分类来实现神经网络架构的定制。
5.使用t-sne来可视化输出的结果。
6.凭借已有的词向量(如glove)来用有限的数据(小数据集或是短句子)进行训练。
情感分析
情感分析是一个复杂的任务。理解一个句子是表达的正面还是负面观点是非常困难的。例如这个句子,“这个电影够无脑、无厘头的,还相当得土,但是我喜欢。”尽管这个句子里包含了好几个负面的词语(无脑、无厘头和土),但这个句子却表达的是正面的观点(“但是我喜欢”)。另外一个不能仅凭单个词语来简单理解的句子是:“这部电影并不关心任何的聪明、智慧和任何类型的智能。”虽然句子里包含了不少的正面词汇(聪明、智慧和智能),但它是一个负面的评论。
一些句子是带有嘲讽性的,或者它们的意思取决于上下文。比如“《飓风营救3》让《飓风营救2》成为一部佳作”。我们能理解这句话其实是贬义,因为我们知道它的上下文(《飓风营救2》并不是一部好片子)。
由于上下文的关系,情感分析是一项非常困难的任务。它的准确性很多时候依赖于要处理的数据。一个情感分析器可能在一套数据上表现得很好,但在另外一套上就表现很糟。机器学习的开发人员应该意识到这一点,并检查他们的模型是否能捕获到数据的变化从而避免尴尬的失败。
编码数据集
越远离表格化数据,数据的处理就越复杂。相比于文字,即使是把图像编码成数字这样的工作都是一个相对简单直接的过程。每个像素只能在RGB色彩空间的0-255之内取值,这些值被存储在一个二维的数组里。对一张图片重设尺寸并不会影响其内容,因此我们可以相对容易地(基于图像处理专家的工作之上)把图像标准化输出为可比较的数组。
但是,把自然语言(词汇)编码成数字就不那么容易了。一种语言可以有海量的词汇,用这些词汇形成的句子就能有各种变化。有时,重设句子的尺寸就会完全改变它们的意思。
让我们看一个样例来帮助理解编码自然语言的过程。看看这组词{我、爱、蛋糕、不喜欢、披萨}({I、love、cake、hate、pizza})。它们构成了我们整个的词汇表。下面两个句子就是用这个词汇表里面的词汇构成的:“我爱蛋糕”(I love cake),“我不喜欢披萨”(I hate pizza)。
我们如何能把这些句子编码成数字?一种方法是使用one-hot编码法把这个词汇表表示成一个如下所示的编码矩阵。
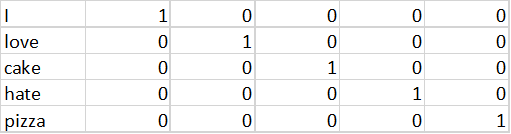
在这个表示方法里,如果词汇表里有N个词,我们就需要一个N×N的矩阵。这个矩阵被叫做词汇表矩阵。这个词汇表矩阵就是查找词汇的表。
现在,让我们试着编码句子。“我不喜欢披萨”将会成为下面这个矩阵。

如果一个词出现在句子里,相应的词汇的行就被从词汇表矩阵里复制过来。这就和在MXNet(或是其他的深度学习框架)的神经网络里的向量层所做的操作是一样的。这一“向量层”就仅仅是进行查找操作,请不要和“词向量”搞混了。关于词向量,我们很快就会介绍的。
有比one-hot编码词汇表更好的方法吗?有更好的表征词的方式吗?词向量就能解决这个问题。与离散化词汇不同,词向量对词汇提供了一个连续值的表征。一个词向量矩阵可以像下面这个样子。
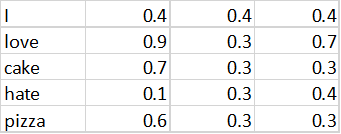
与使用N×N矩阵的词汇表示法不同,我们这里使用一个N×3的矩阵来表征词汇。这里的3就是向量的长度。因此,每个词被表示成了一个3维的向量,而不是N维向量。
词向量不仅能降低词汇表矩阵的尺寸,还能够编码词和词之间的语义关系。例如,“披萨”和“蛋糕”在词汇表里有相似的向量表示,因为它们二者都是食物。“喜爱”和“不喜欢”在第二维上有相同的值,因为它们都表达了感受;但在第一维度上却截然不同(分别是0.9和0.1),因为它们表示的是相反的情感。
这些向量是哪里来的?这些词向量可以是由你的深度神经网络在自动进行情感分类过重中学习到的。特定词的词向量可以被理解成你的深度神经网络需要去学习的权重。这些向量技术也可以被用于图片和其他类型的数据;它们通常被认为是自编码器网络。通常,自编码器试图去用一个更低维的空间来表征输入内容,同时保证最小的信息损失。关于自编码器的详细解释可以在这里找到。
句子的卷积
当用向量层把句子编码成矩阵后,我们就可以对编码矩阵进行一维卷积。这和对两维的图像进行两维卷积很类似。卷积滤波器的尺寸取决于我们想要使用的n-gram。
在边缘的卷积运算会假定输入的边缘是零。这一卷积运算将会帮你基于n-gram从句子里学习。
下面,我们用一个真实的电影评论数据集来看看如何使用MXNet来进行情感分类。
准备你的环境
如果你在使用AWS云服务,你可以使用一个Amazon Machine Image镜像文件来节省安装的工作。这是一个预先配置好的用于深度学习的镜像。使用它可以让你忽略下面的1-5步。
需要注意的是,如果你使用Conda的环境,在启动一个环境后,请记得使用conda install pip命令在conda里安装pip。这么做会为你后面的操作免掉很多的麻烦。
下面是如何设置环境:
1.首先是获取Anaconda,这是一个包管理器。它将帮助你轻松地安装各种Python的依赖库。
2.接下来安装一个通用的科学计算库scikit learn。我们将使用它来预处理我们的数据。你可以使用 conda install scikit-learn命令来安装它。
3.然后使用conda install jupyter notebook命令安装Jupyter Notebook。
4.下面是MXNet,一个开源的深度学习库。
接下来的三步是实现词向量的可视化所需要的。它们不是必须要执行的,但是我强烈建议你可视化结果。
1.下面我们需要安装cython,这是bhtnse库所需要的。
2.我们还需要btsne,这是一个用c++写的tnse的python实现。不要使用scikit-learn自己的tnse实现,它会让python的内核崩溃。
3.最后,我们需要安装matplotlib来画图和进行可视化。
下面是在启动一个anaconda环境后,我们需要在这个环境里使用的安装命令。
1.conda install pip
2.pip install opencv-python
3.conda install scikit-learn
4.conda install jupyter notebook
5.pip install mxnet
6.conda install -c anaconda cython
7.pip install bhtsne
8.conda install -c anaconda matplotlib
数据集
为了学习深度神经网络,我们需要数据。对本文的任务而言,我们将会使用来自Stanford的电影评论数据。你可以在这里下载这个数据集。
这个数据集包含25000个训练样本的训练集和25000个测试样本的测试集。每个数据集里都有一半是正面情感,一半是负面情感。出于速度和简单化的考虑,我们将只使用训练集。我们把它随机地分成了训练、验证和测试三个部分。但就如前面所说的,情感分析是一个复杂的任务,它的准确性会依赖于数据集本身。因此你的模型应该在多个数据集上被测试通过后才能部署到生产系统上去。
这里是加载数据的代码。 我们为正面情绪分配标签1,为负面情绪分配标签0。 因为我们将使用MXnet中的softmaxoutput层来执行分类,所以我们不会对单个标签进行one-hot编码。
在另一个深度学习框架中,对标签进行one-hot编码可能是必要的。
import os
def read_files(foldername):
import os
sentiments = []
filenames = os.listdir(os.curdir+ “/”+foldername)
for file in filenames:
with open(foldername+”/”+file,”r”, encoding=”utf8″) as pos_file:
data=pos_file.read().replace(‘\n’, ”)
sentiments.append(data)
return sentiments
#contains positive movie review
foldername = “easy/pos”
postive_sentiment = read_files(foldername)
#contains negative movie review
foldername = “easy/neg”
negative_sentiment = read_files(foldername)
positive_labels = [1 for _ in postive_sentiment]
negative_labels = [0 for _ in negative_sentiment]
准备数据集和编码
我们需要从标准的数据准备任务开始。需要进行删除URL、特殊字符等操作来清理数据。你还可以使用nltk库来预处理文本。在我们这个场景里,我们使用自定义函数来清理数据。一旦数据被清除,我们需要形成词汇表(数据集中所有可用的唯一词)。
接下来,我们需要找到评论中最常用的单词。这可以防止诸如director name或actor name这样的相对罕见的词语影响分类器的结果。我们还将每个单词(根据出现频率降序排列)映射到一个名为word_dict的字典中的唯一编号(idx)。我们也会有从idx到单词的逆映射。我们这里使用一个5000字的词汇表,也就是说,我们只把最常见的5000个单词视为重要的。词汇表的大小、句子长度和向量尺寸也可以作为参数,在构建神经网络的同时进行实验。我们使用的词汇量为5000,句子长度为500字,向量尺寸为50。
#some string preprocessing
def clean_str(string):
“””
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
“””
string = re.sub(r”[^A-Za-z0-9(),!?\’\`]”, ” “, string)
string = re.sub(r”\’s”, ” \’s”, string)
string = re.sub(r”\’ve”, ” \’ve”, string)
string = re.sub(r”n\’t”, ” n\’t”, string)
string = re.sub(r”\’re”, ” \’re”, string)
string = re.sub(r”\’d”, ” \’d”, string)
string = re.sub(r”\’ll”, ” \’ll”, string)
string = re.sub(r”,”, ” “, string)
string = re.sub(r”!”, ” ! “, string)
string = re.sub(r”\(“, ” “, string)
string = re.sub(r”\)”, ” “, string)
string = re.sub(r”\?”, ” \? “, string)
string = re.sub(r”\s{2,}”, ” “, string)
string = re.sub(r”,”, ” “, string)
string = re.sub(r”‘”, ” “, string)
string = re.sub(r”\[“, ” “, string)
string = re.sub(r”\]”, ” “, string)
return string.strip().lower()
#Creating a dict of words and their count in the entire dataset{word:count}
word_counter = Counter()
def create_count(sentiments):
idx = 0
for line in sentiments:
for word in (clean_str(line)).split():
if word not in word_counter.keys():
word_counter[word] = 1
else:
word_counter[word] += 1
#Assigns a unique a number for each word (sorted by descending order based on the frequency of occurrence)
#and returns a word_dict
def create_word_index():
idx = 0
word_dict = {}
for word in word_counter.most_common():
word_dict[word[0]] = idx
idx+=1
return word_dict
#inverse mapping
idx2word = {v: k for k, v in word_dict.items()}
接下来,我们使用word_dict将这些句子编码成数字。以下代码执行这一操作。
#Creates encoded sentences.
#Assigns the unique id from wordict to the words in the sentences
def encoded_sentences(input_file,word_dict):
output_string = []
for line in input_file:
output_line = []
for word in (clean_str(line)).split():
if word in word_dict:
output_line.append(word_dict[word])
output_string.append(output_line)
return output_string
def decode_sentences(input_file,word_dict):
output_string = []
for line in input_file:
output_line = ”
for idx in line:
output_line += idx2word[idx] + ‘ ‘
output_string.append(output_line)
return output_string
接下来,我们填充或截断一个句子,把它的长度定为500字。也可以根据句子字数的统计来选择不同的长度。
def pad_sequences(sentences,maxlen=500,value=0):
“””
Pads all sentences to the same length. The length is defined by the longest sentence.
Returns padded sentences.
“””
padded_sentences = []
for sen in sentences:
new_sentence = []
if(len(sen) > maxlen):
new_sentence = sen[:maxlen]
padded_sentences.append(new_sentence)
else:
num_padding = maxlen – len(sen)
new_sentence = np.append(sen,[value] * num_padding)
padded_sentences.append(new_sentence)
return padded_sentences
下面,将数据分成训练、验证和测试集:
#train+validation, test split
X_train_val, X_test, y_train_val, y_test_set = train_test_split(t_data, all_labels, test_size=0.3, random_state=42)
#train, validation split of data
X_train, X_val, y_train, y_validation = train_test_split(X_train_val, y_train_val, test_size=0.3, random_state=42)
构建deepnet
现在我们已经准备好了数据集,让我们编写神经网络。构建神经网络就像是科学研究——它涉及到很多实验。 我们可以选择自己做实验或使用其他研究人员用来解决类似问题的现成的神经网络。我们将从一个简单的密集网络开始,然后使用复杂的神经网络架构。
下面的神经网络的代码非常简单明了。这多亏了MXNet的符号化API:
#A simple dense model
input_x_1 = mx.sym.Variable(‘data’)
embed_layer_1 = mx.sym.Embedding(data=input_x_1, input_dim=vocab_size, output_dim=embedding_dim, name=’vocab_embed’)
flatten_1 = mx.sym.Flatten(data=embed_layer_1)
fc1_1 = mx.sym.FullyConnected(data=flatten_1, num_hidden=500,name=”fc1″)
relu3_1 = mx.sym.Activation(data=fc1_1, act_type=”relu” , name=”relu3″)
fc2_1 = mx.sym.FullyConnected(data=relu3_1, num_hidden=2,name=”final_fc”)
dense_1 = mx.sym.SoftmaxOutput(data=fc2_1, name=’softmax’)
让我们把代码分开了仔细看看。首先,它创建了一个数据层(输入层)来存储训练期间用的数据集:
data = mx.symbol.Variable(‘data’)
vocab_embed层负责查询向量矩阵(在这一过程中会被学习出来):
embed_layer_1 = mx.sym.Embedding(data=input_x_1, input_dim=vocab_size, output_dim=embedding_dim, name=’vocab_embed’)
这个扁平层把向量层所产生的(seq_len×向量维度)的权重矩阵转换成一个只有一列的1×(seq_len×向量维度)的向量,作为下一密集层的输入。
flatten_1 = mx.sym.Flatten(data=embed_layer_1)
全连接层把来自扁平层(上一层)的每个输入都连接到当前层的每个神经元上(输出)。
mx.sym.FullyConnected(data=flatten_1, num_hidden=500,name=”fc1″)
relu3_1层对输入进行一次非线性激活来学习复杂的功能。
relu3_1 = mx.sym.Activation(data=fc1_1, act_type=”relu” , name=”relu3″)
最终的密集层(softmax)完成分类。MXNet里的SoftmaxOutput层完成one-hot编码的输出,然后对它使用softmax函数。
训练这个网络
我们会使用GPU对网络进行训练,因为这能提高训练速度,可以把训练时间减少91%。 这将会提高开发速度和产品发布时间,也能降低开发成本。训练集的一次使用被称为一个“epoch”,我们用3个epoch(设“num_epoch = 3”)来训练网络。 我们还定期将训练好的模型存储在JSON文件中,并用它测量训练和验证的准确性,以查看我们的神经网络“学习”的如何了。
下面是代码:
#Create Adam optimiser
adam = mx.optimizer.create(‘adam’)
#Checkpointing (saving the model). Make sure a folder named models exists.
model_prefix = ‘model1/chkpt’
checkpoint = mx.callback.do_checkpoint(model_prefix)
#Loading the module API. Previously MXNet used feedforward (deprecated)
model = mx.mod.Module(
context = mx.gpu(0), # use GPU 0 for training; if you don’t have a gpu use mx.cpu()
symbol = dense_1,
data_names=[‘data’]
)
#actually fits the model for 3 epochs.
model.fit(
train_iter,
eval_data=val_iter,
batch_end_callback = mx.callback.Speedometer(batch_size, 64),
num_epoch = 3,
eval_metric=’acc’,
optimizer = adam,
epoch_end_callback=checkpoint
)
可视化
下面的代码将帮助我们对结果进行可视化,可以提供对于我们的模型的一些理解。我们可以获得由我们的模型生成的向量的权重,然后使用tnse可视化展示结果。
以二维展示vocab-size * embedding_dim(5000 * 500)维的向量是不可能的。 我们需要降低数据的维度以便可视化。t-sne是一种流行的可视化技术,它可以降低维数,使得在N(500)维中更接近的向量在较低维度(2)也靠近。它基本是把N维向量组合成一个简化的维度,同时信息损失最小。 t-sne与PCA非常相似。
下面是提取向量权重,然后将它们可视化为散点图的代码:
# obtains the weights of embeding layer for visualizing
params = model.get_params()
print(params)
weights_dense_embed = model.get_params()[0][‘vocab_embed_weight’].asnumpy()
weights_dense_embed = weights_dense_embed.astype(‘float64′)
#tnse visualization for first 500 words
size = 500
Y= tsne(weights_dense_embed[:size])
plt.figure(0)
plt.scatter(Y[:, 0], Y[:, 1])
for idx, (x, y) in enumerate(zip(Y[:, 0], Y[:, 1])):
plt.annotate(idx2word[idx], xy=(x, y), xytext=(0, 0), textcoords=’offset points’)
下面的t-sne图展示了前500个词的权重。
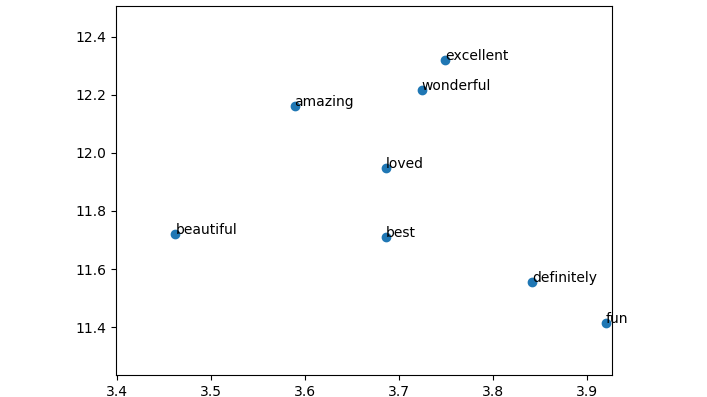
这个可视化的图展示了模型自动学习到“excellent(精彩)、wonderful(完美)、amazing(神奇)”都是同一个意思。这相当得不错!下面我们写一个简单的预测函数来使用这个模型。
样本预测
我们用这个模型来预测句子的情感。为此,我们需要加载保存的模型:
# Load the model from the checkpoint . We are loading the 10 epoch
sym, arg_params, aux_params = mx.model.load_checkpoint(model_prefix, 3)
# Assign the loaded parameters to the module
mod = mx.mod.Module(symbol=sym, context=mx.cpu())
mod.bind(for_training=False, data_shapes=[(‘data’, (1,500))])
mod.set_params(arg_params, aux_params)
接着用word_dict的索引来编码要预测的句子,再把它传给模型分类器。
from collections import namedtuple
Batch = namedtuple(‘Batch’, [‘data’])
#a simple predict function
def predict(sen):
# compute the predict probabilities
mod.forward(Batch([mx.nd.array(sen)]))
prob = mod.get_outputs()[0].asnumpy()
# print the top-5
prob = np.squeeze(prob)
return prob
#our custom sentences for testing
my_sen =[“the movie was awesome. Loved it”]
my_sen_encoded = encoded_sentences(my_sen,word_dict)
my_sen_encoded_padded = pad_sequences(my_sen_encoded)
输出是[0.09290998 0.90709001],这意味着分类器以0.90的概率认为句子的情感是正面的。
然而,这个模型只用单个的词做出预测。如果考虑到单词之间的关系,我们可以做得更好。为了做到这一点,我们需要建立一个一次可以考虑多个连续的单词(n-gram)的卷积神经网络。 接下来,我们将构建一个可以捕获n-gram里的信息的卷积网络,用于情感分类。
构建卷积模型
如前所述,为了开发一个基于n-gram的模型,我们需要一个卷积神经网络。 所以,我们构建一个。 这与之前的模型非常相似,只是卷积滤波器的尺寸变成了5。
#a model with convolution kernel of 5 (5-grams)
input_x_2 = mx.sym.Variable(‘data’)
embed_layer_2 = mx.sym.Embedding(data=input_x_2, input_dim=vocab_size, output_dim=embedding_dim, name=’vocab_embed’)
conv_input_2 = mx.sym.Reshape(data=embed_layer_2, target_shape=(batch_size, 1, seq_len, embedding_dim))
conv1_2 = mx.sym.Convolution(data=conv_input_2, kernel=(5,embedding_dim), num_filter=100, name=”conv1″)
flatten_2 = mx.sym.Flatten(data=conv1_2)
fc2_2 = mx.sym.FullyConnected(data=flatten_2, num_hidden=2,name=”final_fc”)
convnet = mx.sym.SoftmaxOutput(data=fc2_2, name=’softmax’)
唯一棘手的是conv_input_2输入层。该层将向量层的输出重新整形为卷积层所需的格式。模型的其他一切都保持不变。可以使用model.fit函数来训练该模型,并且可以获得各种见解。
构建“多卷积”模型
这个模型和之前的一样,除了我们使用了多个卷积的尺寸(3,4,5)来构建3-gram、4-gram和5-gram的模型,然后对输出进行了裁剪和扁平化。一个最大池化层被加入进模型来防止过拟合。下面是python代码:
# a model with convolution filters of 3, 4, 5 (3-gram,4-grams,5-grams)
input_x_3= mx.sym.Variable(‘data’)
embed_layer_3 = mx.sym.Embedding(data=input_x_3, input_dim=vocab_size, output_dim=embedding_dim, name=’vocab_embed’)
conv_input_3 = mx.sym.Reshape(data=embed_layer_3, target_shape=(batch_size, 1, seq_len, embedding_dim))
# create convolution + (max) pooling layer for each filter operation
filter_list=[3, 4, 5] # the size of filters to use
num_filter=100
pooled_outputs = []
for i, filter_size in enumerate(filter_list):
convi = mx.sym.Convolution(data=conv_input_3, kernel=(filter_size, embedding_dim), num_filter=num_filter)
relui = mx.sym.Activation(data=convi, act_type=’relu’)
pooli = mx.sym.Pooling(data=relui, pool_type=’max’, kernel=(seq_len – filter_size + 1, 1), stride=(1,1))
pooled_outputs.append(pooli)
# combine all pooled outputs
total_filters = num_filter * len(filter_list)
concat = mx.sym.Concat(*pooled_outputs, dim=1)
# reshape for next layer
h_pool_3 = mx.sym.Reshape(data=concat, target_shape=(batch_size, total_filters))
fc2_3 = mx.sym.FullyConnected(data=h_pool_3, num_hidden=2,name=”final_fc”)
convnet_combined = mx.sym.SoftmaxOutput(data=fc2_3, name=’softmax’)
使用glove的迁移学习
我们使用神经网络生成的词向量给了我们很多见解。但是为了生成词向量,我们需要大量的数据。如果我们只有少量的数据呢?从不同的预先训练的神经网络传递权重可能是非常有用的。这有助于在即使只有少量的数据的情况下建立一个模型。
在这里,我们将使用Stanford大学开发的glove词向量。我们使用维基百科-2014年glove词向量,它是在60亿词的维基百科语料库上训练的。词向量本身具有40万个唯一的单词(词汇),并包含各种维度尺寸(50,100,200,300)。我们将使用50维词向量来训练神经网络。词向量维度这个值也是一个超参数,你应该尝试不同的值,看看哪一个给你最好的结果。以下函数将词向量加载到向量矩阵(一个numPy矩阵)中:
#loads glove word embedding
def load_glove_index(loc):
f = open(loc,encoding=”utf8″)
embeddings_index = {}
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype=’float32′)
embeddings_index[word] = coefs
f.close()
return embeddings_index
#creates word embedding matrix
def create_emb():
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for word, i in word_dict.items():
if i >= vocab_size:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
return embedding_matrix
embeddings_index = load_glove_index(“glove/” + ‘glove.6B.50d.txt’)
embedding_matrix = create_emb();
让我们用t-sne来可视化一下glove的词向量:
#visualization of word embedding.
size = 500
Y= tsne(embedding_matrix[:size])
plt.figure(1)
plt.scatter(Y[:, 0], Y[:, 1])
for idx, (x, y) in enumerate(zip(Y[:, 0], Y[:, 1])):
plt.annotate(idx2word[idx], xy=(x, y), xytext=(0, 0), textcoords=’offset points’)
下图是对glove的头500个词进行t-sne可视化的结果:
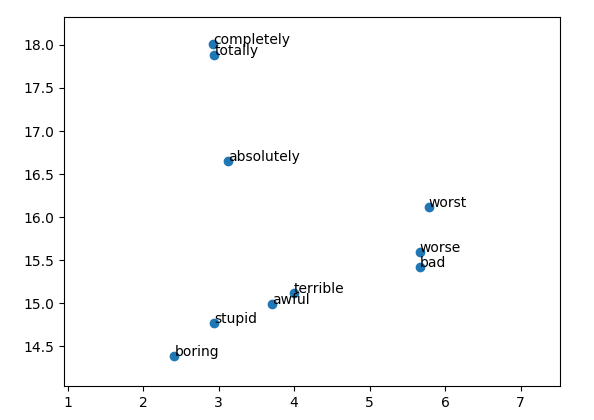
正如你所看到的那样,词向量已经将类似的单词“worse”(比较差),“worst”(最差),“bad”(差),“terrible”(恐怖)分组在一起。 让我们用这个词向量来创建一个神经网络进行句子情感分类。将预先训练的权重添加到神经网络可能有点棘手。以下是代码:
#creates a model with convolution and pre-trained word embedding.
weight_matrix = mx.nd.array(embedding_matrix)
input_x_3= mx.sym.Variable(‘data’)
the_emb_3 = mx.sym.Variable(‘weights’) #the weight variable which will hold the pre trained embedding matrix
embed_layer_3 = mx.sym.Embedding(data=input_x_3,weight=the_emb_3, input_dim=vocab_size, output_dim=embedding_dim, name=’vocab_embed’)
conv_input_3 = mx.sym.Reshape(data=embed_layer_3, target_shape=(batch_size, 1, seq_len, embedding_dim))
conv1_3 = mx.sym.Convolution(data=conv_input_3, kernel=(5,embedding_dim), num_filter=100, name=”conv1″)
flatten_3 = mx.sym.Flatten(data=conv1_3)
fc2_3 = mx.sym.FullyConnected(data=flatten_3, num_hidden=2,name=”final_fc”)
convnet_word2vec = mx.sym.SoftmaxOutput(data=fc2_3, name=’softmax’)
在这里,我们首先将glove的embedding_matrix转换成mx.nd.array。 然后我们创建一个名为权重的符号变量,并将其赋值给变量the_emb_3。该变量作为参数传递给mx.sym.Embedding中的embed_layer_3。
下一步是通过将weight_matrix作为embed_layer_3的默认权重来训练神经网络。此外,我们需要冻结词向量的权重,以便在反向传播时,embed_matrix的权重不会被更新。记得在模块API中传入fixed_param_names =[‘weights’]以冻结词向量层的权重。此外,在使用glove词向量权重进行拟合时,传入arg_params={‘weights’: weight_matrix}。 下面是python代码:
adam = mx.optimizer.create(‘adam’)
#Checkpointing (saving the model). Make sure there is folder named model4 exist
model_prefix_3 = ‘model4/chkpt’
checkpoint = mx.callback.do_checkpoint(model_prefix_3)
#Loading the module API. Previously MXNet used feed forward (deprecated)
model_3 = mx.mod.Module(
context = mx.gpu(0), # use GPU 0 for training; if you don’t have a gpu use mx.cpu()
symbol = convnet_word2vec,
fixed_param_names =[‘weights’] # makes the weights variable non trainable. Back propagration will not update #this variable
)
#fits the model for 5 epochs.
model_3.fit(
train_iter,
eval_data=val_iter,
batch_end_callback = mx.callback.Speedometer(batch_size, 64),
num_epoch = 5,
eval_metric=’acc’,
optimizer = adam,
epoch_end_callback=checkpoint,
arg_params={‘weights’: weight_matrix}, #loads the pretrained glove embedding to weights variable
allow_missing= True
您可能已经注意到,对于这个特定的数据集使用glove词向量(预先训练的词向量)并不能带来更好的结果。试验不同维度的词向量和使用更高容量的模型(更多的神经元)可能会提高性能。在这里下载Notebook文件,看看你是否能让它工作得更好! 您也可以考虑使用像LTSM或GRU这样的递归神经网络来提高表现。
结论
在本教程中,我们对电影评论数据集进行了情感分类。 我们使用MXNet开发了不同复杂度的模型,并理解了词向量这一重要概念,学习了如何可视化我们模型学习的权重的方法。最后,我们还进行了使用glove词向量的迁移学习。
在后续教程中,我们将学习如何使用深度学习来生成新的图像、声音等。这些类型的模型被称为生成模型。
这篇博文是O’Reilly和Amazon的合作产物。请阅读我们的编辑独立声明。
Manu Jeevan
Manu Jeevan是人工智能公司AI Solutions的联合创始人,该公司为企业构建人工智能解决方案。他是一名自学成才的数据科学家,喜欢用人工智能和机器学习来解决复杂的业务问题。 可以在LinkedIn上找到他。
Suresh Rathnaraj
Suresh Rathnaraj是人工智能公司AI Solutions的联合创始人,该公司为企业构建AI解决方案。 他是一名机器学习工程师,拥有计算机科学硕士学位。 他非常热衷于深度学习,并认为它可以彻底改变整个科技行业。 业余时间里,他会打橄榄球并练习瑜伽。可以在LinkedIn上找到他。






更多人工智能内容请关注2018年4月10-13日人工智能北京大会。