在过去的几年间,数据社区已经在关注收集和整理数据,为此目的构建基础设施,并使用数据来改善决策制定。现在我们看到,在很多垂直领域,对于高级分析和机器学习的兴趣高涨。
在本博文里,我会分享和解释我在今年9月的Strata数据纽约大会上的演讲,以此来为那些希望增加机器学习能力的企业提供一些建议。这些信息来自于和业界从业人员、研究人员和企业家的对话,他已经把机器学习应用在非常多的不同领域的问题里。
和其他的技术与方法类似,一个成功的机器学习项目是从找到一个正确的应用场景开始的。机器学习有非常多可能的应用,例如推荐系统和降低客户流失等。一个有用的机器学习应用的分类如下:
- 能增强决策制定的应用
- 能带来业务运营改进的应用
- 能产生收入的应用
- 能预测或者防止欺诈或风险的应用
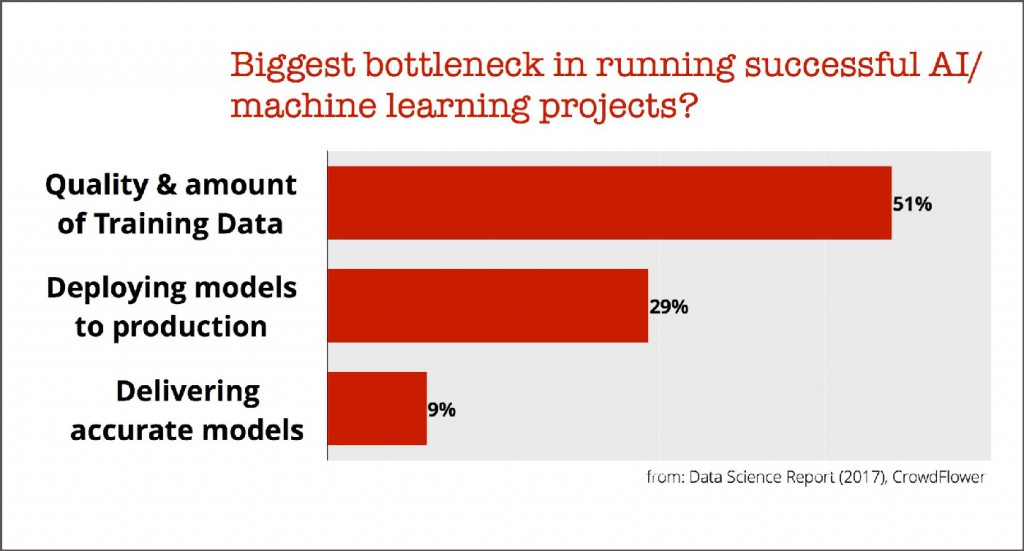
为了能成为“机器学习型企业”,让你自己了解开始部署模型时将会面临的困难是非常有益处的。如果你去咨询那些机器学习的先行者,通常会得到如下三个东西:
- 数据:目前大部分应用个都依赖于监督学习。因此一切都要从拥有高质量的标注(训练)数据集开始。
- 工程化:你怎么能把一个原型变成生产系统?你如何在模型部署上线之后监控它的表现?
- 模型:现在的机器学习库已经能把模型和数据适配变得很容易,那还有什么挑战?
在文章下面的内容里,我会逐个讲述这些挑战。

在构建标注数据集来训练你的机器学习模型时,重要的一点就是使用你已经能找到的数据。新的数据源在持续地出现,数据集成是大部分公司都在做的工作。你目前在数据基础设施上的投入可能已经给你足够的数据来开始了。你也可以使用公共(开源)的数据来增强你现有的数据集,或是去从第三方购买数据来增强。

好消息是机器学习社区已经意识到训练数据是一个主要的瓶颈。研究人员已经在研究一些能用比较少的训练数据开始的技术(弱监督),以及可以让你把一个问题里获得的知识用于另外的场景(迁移学习)。
随着数据重要性的增加,已有一些创业公司和企业在探索数据交易。数据交易让企业间相互分享一些数据成为可能,同时还能保证私密性和隐秘性。目前已经有一些研究成果来开发安全机器学习算法。对一些应用,如消费金融业里的欺诈检查,能在保证隐私和安全的情况下,分享私密数据可能被证明是有价值的。
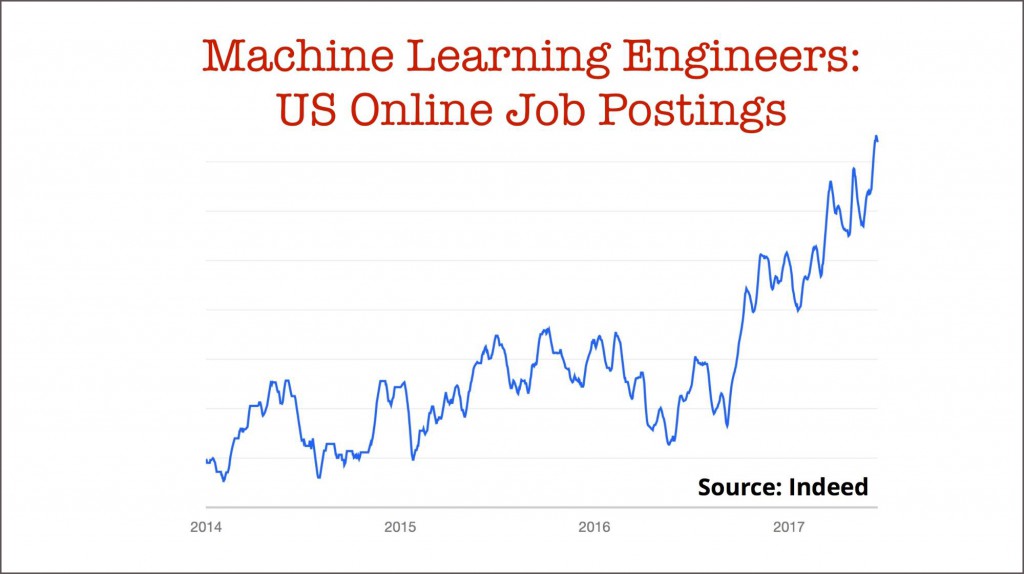
今年早些时候,我们注意到企业已经开始定位一个新的角色,它专门把机器学习的模型进行生产化部署,并监控部署后的表现。但是这个机器学习工程师的角色就真的必要吗?
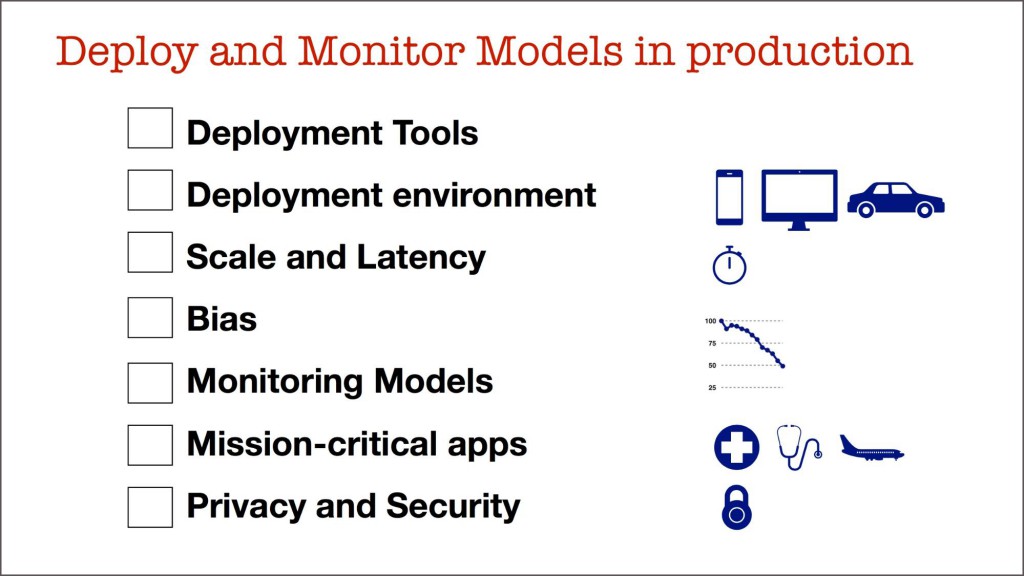
对越来越多的公司来讲,答案是肯定,这样的专业技能是必须的。如果要列出一个能生产化并监督模型必须了解的事情的清单,最后你会看到一堆工具和技术的列表。更具体的细节,建议你看看我之前的一篇博文《应用数据科学的现状》。
机器学习研究的发展速度是很快的。可以公平地说,大部分企业是无法跟上研究出新技术和工具的速度。思考一下这个思维试验:想象一下未来五年,所有的研究进展都暂停(绝不可能,但是请允许我幽默一下)。我坚定地认为依然有足够的工具能让企业忙活一阵子来学习。

用深度学习这一已经成功地应用于计算机视觉和语音的技术作例子。绝大部分的企业依然处于应用深度学习的早期阶段,不管是把它用于企业已经熟悉的数据(文本、时间序列数据、结构化数据)或是使用它来代替现有的模型(包括他们现有的推荐系统)。我认为在未来的几年里会看到很多使用深度神经网络(DNN)的有趣案例。

深度学习带来了所有令人激动的东西,但也因此我们时常会忘记还有很多有趣的新数据应用并不依赖于神经网络。请选择适合你的技术和业务需求的那些技术。
随着模型被推入边缘设备,我对近期在联合与协作学习方面的研究进展非常感兴趣。展望AI,可获得的在线和持续学习的工具将会变得非常重要。

数据社区正在开始明白对于模型而言,远远不仅仅只是优化一个定量或是业务指标那么简单。模型足够鲁棒从而能应对对抗攻击吗?对特定的应用模型来说,可解释与可理解是必须的吗?
- 公平:你是否理解你的训练数据的分布?如果不是的话,请意识到过去的歧视将很有可能导致未来的歧视。
- 透明:随着机器学习变得无处不在,用户正越来越想知道企业在对什么指标进行优化,并想对此发表意见。

尽管机器学习领域在近几年已经取得了很多进步,但是依然有很多研究人员和理论家不知道的东西。我们尚处在“试错”的阶段。深度学习可能是降低了特征工程的必要,但是在构建深度神经网络时依然有很多需要决定的东西(包括网络架构和非常多的超参数)。
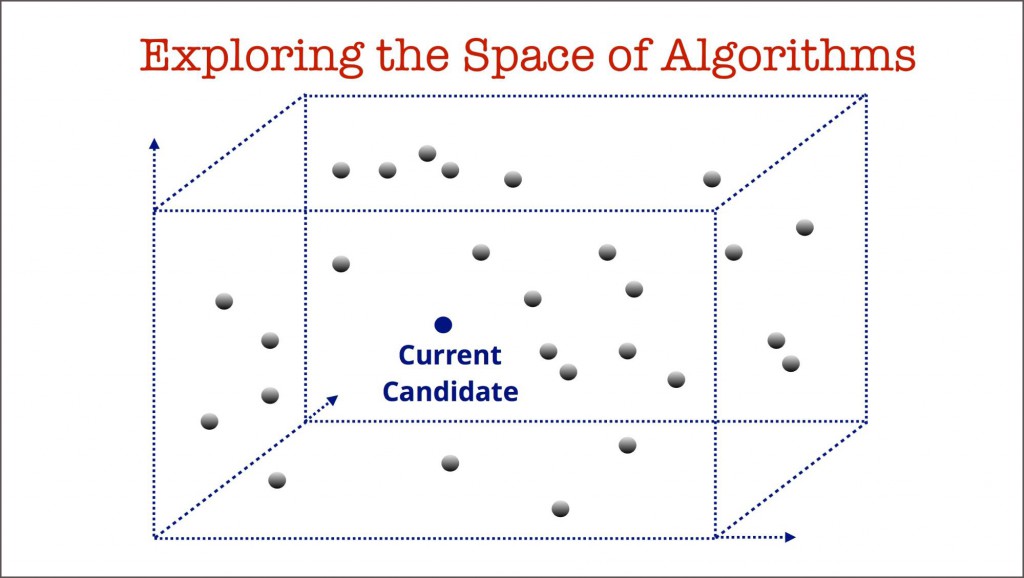
可以把模型的构建看成是对机器学习算法空间的探索。企业需要能以有原则和高效的形式来进行探索。这意味着企业要维护可再生的管道、保存试验里的元数据、拥有协作的工具和利用最新的研究成果。
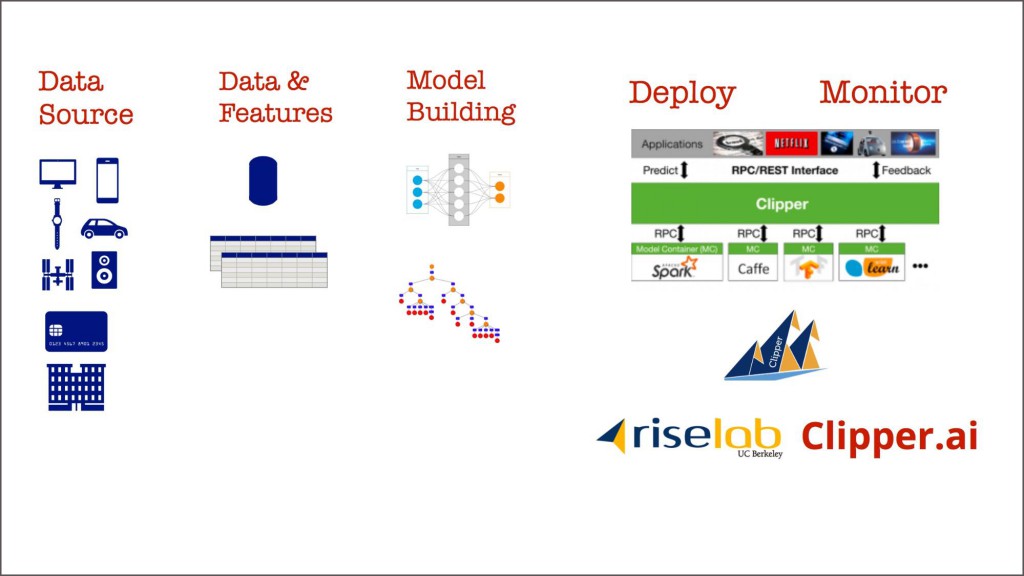
那么,企业正在构建的什么东西可以让这一探索成为可能?大部分机器学习都要求有标注(训练)数据,因此任何数据平台开始都要有鲁棒的数据管道,能够把数据导入存储系统,让数据科学家和机器学习工程师可以使用。数据集成不是一件无足轻重的事情,是所有的企业都要做并会持续做的工作。
企业也正在赋能数据科学家来分享特征和能产生这些特征的数据管道。为了给你一个关于特征的重要性的概念,看看这个事实:大部分企业都能很容易地告诉你它们用了什么算法;但是他们却很难描述哪些特征对模型最有用。
领先的企业让他们的数据科学家使用多种机器学习库。强迫你的数据科学家只使用一到两个“保佑”过的库时很疯狂的。因为数据科学家们要能做实验,这可能就意味着让他们能使用多种库。
已经出现了一些公司,他们能提供生产化部署机器学习模型的工具,并可以在部署后监控模型。一些企业也在利用开源技术来开发自己的部署和监控工具。如果你在寻找一个开源的工具来部署和监控模型,可以看看加州大学伯克利分校RISE实验室的新项目——Clipper。它可以让你很容易地部署用多种流行的机器学习库编写的模型。更为重要的是,Clipper团队最近加入了模型的监控部分。(一些企业将会在2018年3月的Strata数据圣何塞大会上介绍他们部署和监控模型的方法。)
想成为“机器学习型企业”, 你需要工具和流程来克服数据、工程和模型方面的挑战。很多企业仅仅是刚开始在他们的产品里使用和部署机器学习。工具正在被持续地改进,最佳实践也开始出现。

Ben Lorica
Ben Lorica是O'Reilly Media公司的首席数据科学家和数据内容策略总监,他还是Strata数据大会和O'Reilly人工智能大会的项目主管。他将商务智能、数据挖掘、机器学习和统计分析应用到了各种领域,包括直接营销、消费者和市场研究、精确广告投放、文本挖掘以及金融工程。他曾在投资管理公司、互联网创业公司以及金融服务业任职。






更多人工智能内容请关注2018年4月10-13日人工智能北京大会。