语音识别的梦想是一个能在不同的环境下、能应对多种口音和语言的、真正理解人类语言的系统。几十年来,对这个问题的尝试都没有成功。寻找一个能有效地创建这样的系统的策略看起来是不可能完成的任务。
然而,在过去的几年间,人工智能和深度学习领域的突破已经颠覆了对语音识别探索的一切。深度学习技术在语音识别领域的运用已经取得了显著的进步。现在我们已经在非常多样的产品(比如Amazon Echo、Apple Sir等)里面看到了展示出来的发展的跃升。在这篇博文里,我会回顾一下近期语音识别的发展,检查带来这些快速进步的因素,并会讨论一下未来的发展以及我们离完全解决这个问题还有多远。
一点背景知识
多年以来,人工智能的主要任务之一就是去理解人类。人们希望机器不仅能理解人说了什么,还能理解他们说的是什么意思,并基于这些理解的信息采取相应的动作。这个目标就是对话人工智能的精髓。
对话人工智能包括两个主要类别:人机交互界面和人与人交互界面。在人机界面里,人类主要是通过语音和文字与机器交互。机器能理解人类的意思(即使只是在一个有限的形式下)并采取某个动作。如图1所示,这个机器可以是个人助理(比如Siri、Alexa等),或是某种聊天机器人。
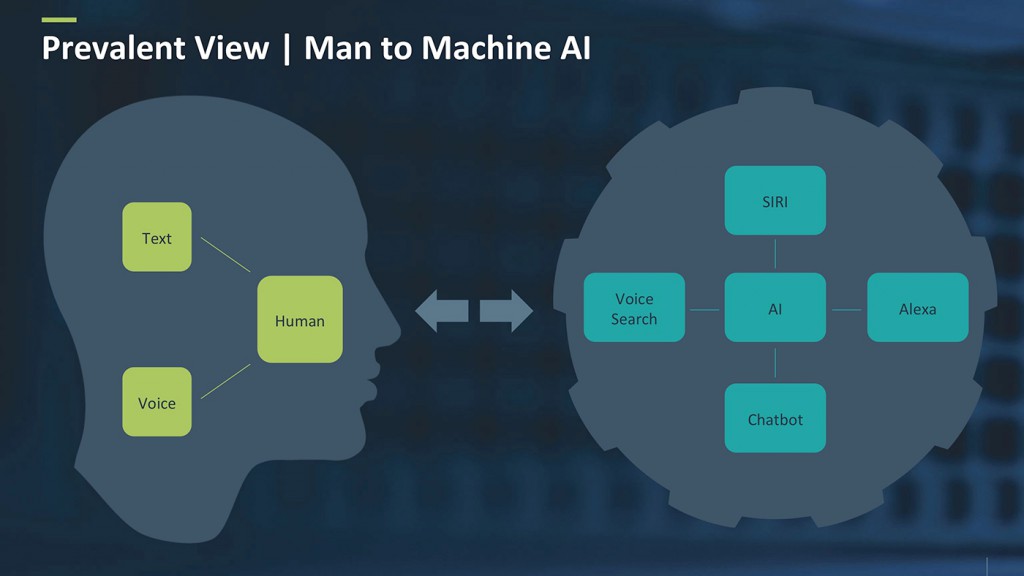
图1 人机人工智能。来源:Yishay Carmiel
在人和人交互里,人工智能形成了两个或多个人之间对话的桥梁,进行交互或是创造一些洞察(如图2所示)。一个这样的例子可能是人工智能参与一个电话会议,然后产生一个会议的纪要,并交付给相关的人。
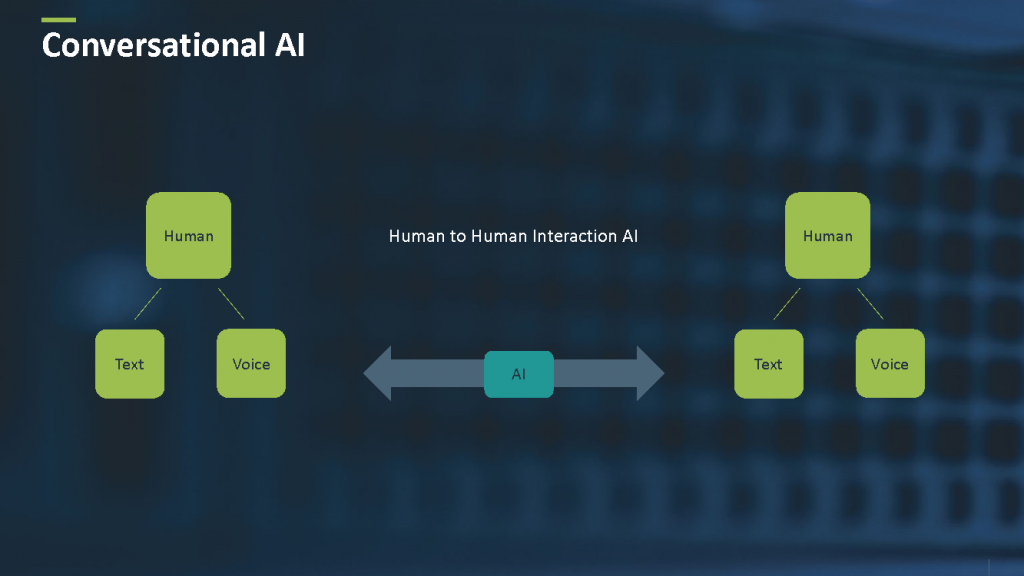
图2 人和人间的人工智能。来源:Yishay Carmiel
机器感知和认知
为了能更好地理解对话人工智能所面临的挑战和背后的技术,我们必须先看看人工智能里的基本概念:机器感知和机器认知。
机器感知是机器所具有和人类使用他们的感官去感知世界所类似的形式来分析数据的能力。换句话说,就是给予机器类似人的感官。很多使用计算机相机(例如目标检测和识别)的人工智能算法都可以归到计算机感知这一类里,他们关注的是视觉。语音识别和画像是机器使用听觉的感知技术。
机器认知是在机器感知产生的元数据上的推理能力。机器认知包括决策、专家系统、采取行动、用户倾向等。通常如果没有机器认知不会对机器感知的输出产生影响。机器感知为决策和采用什么动作提供合适的元数据信息。
在对话人工智能里,机器感知包括所有的语音分析技术,比如识别和画像;机器认知包括所有和理解语言相关的技术,它们是自然语言处理(Natural Language Processing, NLP)技术的一部分。
语音识别领域的演进
语音识别技术的研究和发展主要包括三个时期:
2011年之前
语音识别的研究已经有几十年了。实际上,甚至是在上世纪50和60年代,就已经有了构建语音识别系统的尝试了。不过,在2011年前,深度学习、大数据、云计算的进步尚未发生,这个时期的系统离能被广泛采用和商业化都很远。本质上,算法都不够好、没有足够的数据来训练算法、缺少必要的高性能计算机硬件都在妨碍研究人员尝试更复杂的试验。
2011-2014年
深度学习(在语音识别里)的第一个主要影响发生在2011年。一组来自微软的研究人员——Li Deng、Dong Yu和Alex Acero——与Geoffrey Hinton和他的学生George Dahl创造了第一个基于深度学习的语音识别系统,并立刻就产生了影响:错误率降低了25%多。这个系统是语音识别领域繁盛发展和提升的起点。凭借更多的数据、可用的云计算资源以及被诸如Apple(Siri)、Amazon(Alexa)和Google这样的公司重视,语音识别的性能得到了显著的提升,并伴随着不少商业化产品被投放到市场。
2015年至今
到2014年底,循环神经网络获得了更多的关注。它与关注模型、记忆网络和其他的技术一起,形成了第三波的进展。现在,几乎每种类型的算法和解决方案都使用某种类型的神经网络模型。实际上,几乎所有的语音研究都在转向使用深度学习。
近期语音领域里神经网络模型的进展
语音识别领域在过去6年里的突破比之前40多年加起来还要多。这些非凡的进展主要是来源于神经网络。为了更好地理解深度学习的影响和它的作用,我们需要先理解一下语音识别是如何工作的。
虽然语音识别作为一个活跃的研究领域已经存在几乎50年了,构建可以理解人类语言的机器依然是最具挑战的任务之一。它比看起来要困难得多。语音识别有一个清晰明确定义的任务:对于一些人类的语言,尽量把语音转化成文字。然而,语音可能是一个噪声信号的一部分,这就需要先把语音从噪音里面抽取出来,然后再转化成相应的有意义的文字。
语音识别系统的基本构造模块
基本上语音识别可以被分为三个层面:
信号层面:信号层面的目标是从信号里抽取出语音,增强它(如果需要),进行适当的预处理和清理,再提取出特征。这一层面的内容与其他机器学习任务很类似。换句话说就是对于一些数据,我们需要进行预处理和特征提取。
声音层面:声音层面的主要目标是把特性分到不同的声音类。另外一种说法就是,声音自身并没能提供足够精确的标准,而是有时被称为声音状态的音素来提供。
语言层面:因为我们假定这些不同类型的音是由人类产生的并有意义,我们需要把音组合成字和词,再把词组合成句子。这些语言层面的技术通常是一些不同类型的NLP技术。
深度学习带来的提升
深度学习对语音识别领域带来了显著的影响。这一影响是如此深远,以至于语音识别领域的几乎每个解决方案里都可能有一个或多个基于神经网络的算法嵌在其中。
通常,对语音识别系统进行的评估都是基于一个叫做Swithboard(SWBD)的行业标准。SWDB是一套语音库,由一些电话通话的内容所组成。SWDB包括语音和人工生成的文字记录。
语音识别系统的评估是基于一个叫词错误率(WER)的指标。WER是指识别系统错误地识别出来的词的数量。图3显示了从2008到2017年期间WER的提升情况。
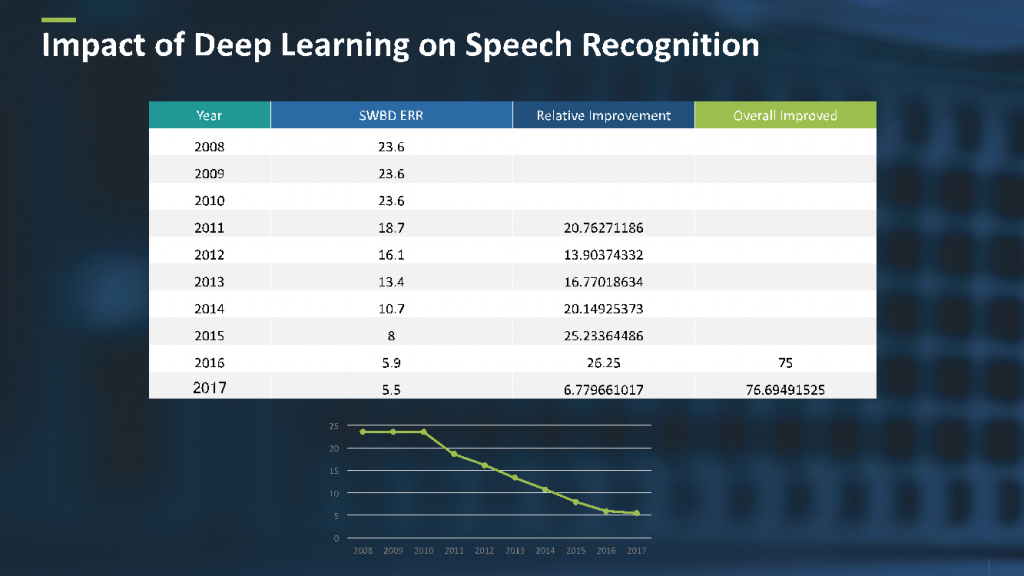
图3 词错误率的改进。来源:Yishay Carmiel
从2008年到2011年,WER处于一个比较稳定的状态,在23%到24%左右。深度学习在2011年出现,把WER从23.6%降到5.5%。这一改进是颠覆性的,取得了77%的提升。现在语音识别已经有了非常广泛的应用,比如Apple的Siri、Amazon的Alexa、微软的Cortana和Google的Now。我们也看到了由语音识别所激活的种类繁多的应用设备的出现,比如Amazon的Echo和谷歌的Home。
秘方
是什么带来了系统性能的显著提升?是某个技术把WER从23.6%降到5.5%吗?不幸的是,并不是一个单一的技术。深度学习和语音识别交织得非常紧密,它创造了一个涉及非常多种、不同的技术和方法的先进系统。
例如在信号层面,有不同的基于神经网络的模型来提取和增强语音里面的信号(如图4所示)。而且,还有使用复杂和高效的基于神经网络的方法替换掉经典的特征抽取的方法。
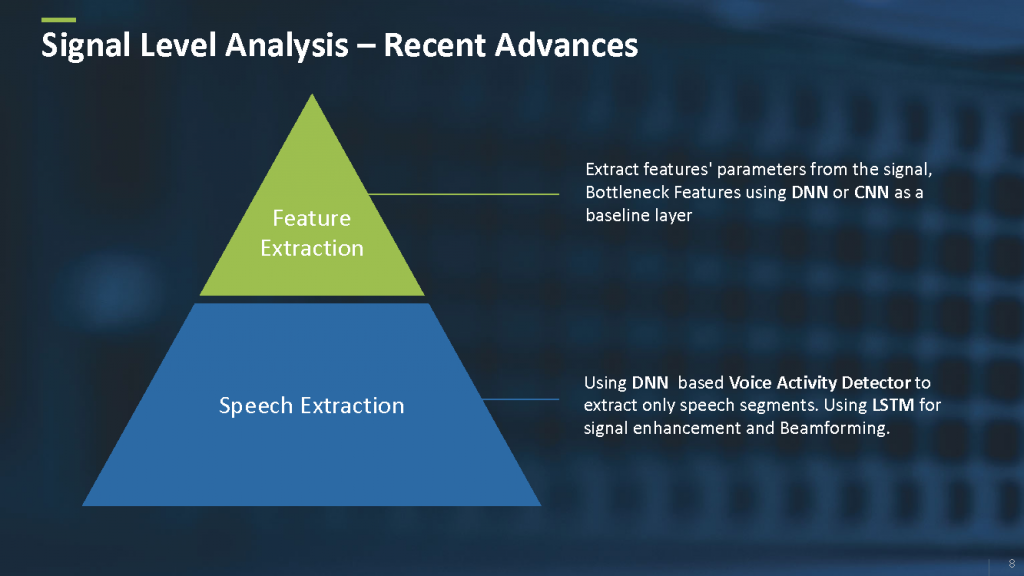
图4 信号层面的分析。来源:Yishay Carmiel
语音层面和语言层面也包括了多种深度学习技术,从使用不同的神经网络架构的声音状态分类,到语言层面的基于神经网络的语言模型。
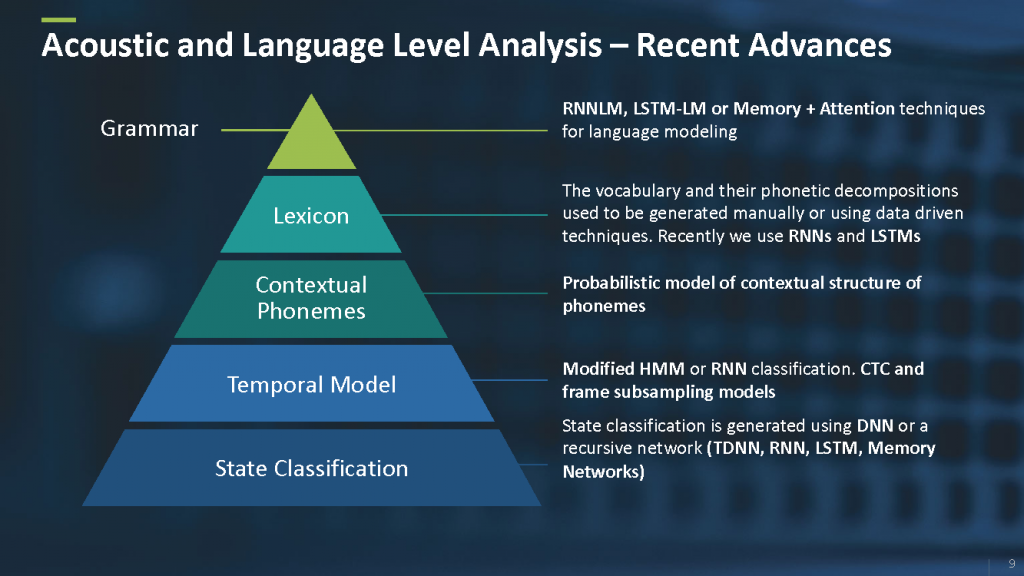
图5 语音和语言层面的分析。来源:Yishay Carmiel
创造一个最前沿的系统并不是件容易的事情,包括实现和集成上面所说的不同的技术。
最前沿的研究
看到语音识别领域在近期有如此多的突破,读者可能会很自然地问:下一步会发生什么?下面三个领域看起来会是近期主要受关注的研究领域:算法、数据和可扩展性。
算法
随着Amazon的Echo和Google的Home的成功,很多公司都在开发和投放能理解语音的智能音箱和家用设备。然而这些设备带来了一个新的问题,即用户不会像和手机通话那样靠近麦克风,而是离的比较远。应对远距离语音已经成为很多研究组正在挑战的一个问题了。现在,创新性的深度学习和信号处理技术已经能提升识别的质量了。
当前最有趣的研究主题之一就是找到新的、奇特的神经网络拓扑结构。我们已经在应用语言和语音模型方面看到一些有希望的结果。其中的两个例子是语音模型里的Grid-LSTM和基于注意力的记忆网络的语言模型。
数据
语音识别系统的一个关键问题就是缺乏真实世界的数据。例如,很难获得高质量的远距离语音数据。不过有很多其他来源的数据可用。一个问题就是,我们能创造合适的合成器来生成训练数据吗?产生合成的数据并用它来训练系统目前正在获得很多的关注。
为了训练一个语言识别系统,语音和标注数据我们都需要。人工标注是一项繁琐的工作,对于海量语音数据进行标注有时候会带来问题。相应的,使用半监督训练和构建恰当的识别器的置信测量就成为了一个活跃的研究主题。
可扩展性
由于深度学习和语音识别是高度交织的,它会使用非常多的计算资源(CPU和内存)。当用户广泛采用了语音识别系统后,如何构造一个高效的云端解决方案就成为一个有挑战性的重要问题。正在进行的研究就包括如何降低计算花销和开发更有效的解决方案。现在大部分的语音识别系统都是基于云端的,这就带来两个需要解决的主要问题:网络延迟和长时间连接。网络延迟是那些需要立刻反应的设备(比如机器人)面对的关键问题。对于一个需要持续监听的系统,因为带宽的费用,长时间连接就是一个问题。对此,已经有研究关注面向边缘设备的、和云端系统有一样质量的语音识别能力的系统。
完全解决语音识别问题
近几年,语音识别领域无论是性能还是商用都取得了跨越式的提升。那么离完全解决这个问题还有多远?我们能在5年或许10年内宣布最终胜利?答案是:有可能,不过还是有不少挑战性的问题需要时间来解决。
第一个问题是对于噪音的敏感性。语音识别系统对于靠近麦克风的无噪音环境可以工作的很好。但是远距离语音加上噪音数据会很快地降低系统性能。第二个问题是语言的扩展问题。人类世界有大约7000种语言,目前的大部分语音识别系统支持了大概80种。扩展到更多的语言带来了大量的挑战。另外,对很多语言我们缺乏数据,而语音识别系统在数据源很少的情况下很难被构建出来。
结论
深度学习已经在语音识别和对话式人工智能领域留下了烙印。因为近期的突破,我们已经处在革命的前沿。现在最大的问题就是,我们能取得最终的胜利,解决语音识别的问题,从而可以像其他很多商业化的技术那样使用语音识别吗?或者是还有一个新的解决方案在等待被发现?毕竟,语音识别近期的进步仅仅只是整个问题的一个部分的答案。这个问题就是理解语言,它本身是一个复杂的谜题,甚至是一个更大的问题。

Yishay Carmiel
Yishay Carmiel是Spoken Labs的主管。Spoken Labs是Spoken Communication公司的一个战略性人工智能和机器学习研究中心。Spoken Labs为自动语音识别(ASR)、自然语言处理(NLP)和先进的语音数据抽取进行研究和实现业界领先的深度学习和人工智能技术。Yishay和他的团队近期正致力于先进的边缘设备创新,从而使实时的大规模的客户体验成为现实。作为算法科学家和技术领导,Yishay有着近20年的构建大规模机器学习算法的经验,并是一名深度学习专家。






更多人工智能内容请关注2018年4月10-13日人工智能北京大会。