随着越来越多的公司开始在不同的情景中试验和部署机器学习,展望未来的系统大致的样子应该是一个好主意。现在机器学习典型的顺序是先收集数据,再学习一些不明显的模式,最后部署一个算法来系统地捕捉你所学到的东西。收集、整理和增强正确的数据(尤其是训练数据)是至关重要的,而且也是那些想使用机器学习的公司的关键瓶颈。
我坚定地认为未来的人工智能系统将依赖于持续学习,而不是离线训练的算法。人类是通过这种方法进行学习的,人工智能系统也将越来越有能力做同样的事情。想象一下,第一次去办公室时你在一个障碍物上被绊倒。当你下次访问这个场景的时候(也许只是几分钟以后)你就会知道需要寻找那个绊倒你的物体。
在很多应用和场景里的学习具有类似的探索性。想象一下,一个与环境交互的机器人会尝试了解要采取哪些动作同时应该避免哪些动作,这样才能完成一些预先分配的任务。我们已经看到了关于增强学习(RL)的最新应用。在增强学习中,目标是学习如何将观察和测量映射到一组动作,同时尝试最大化一些长期的奖励(增强学习这个术语经常被用来描述一类问题和一组算法)。虽然深度学习得到了更多的媒体关注,但最近在人工智能圈里对增强学习感兴趣的有很多。研究人员最近将增强学习应用于游戏、机器人、自动驾驶汽车、对话系统、文本总结、教育和培训以及能源利用等方面。
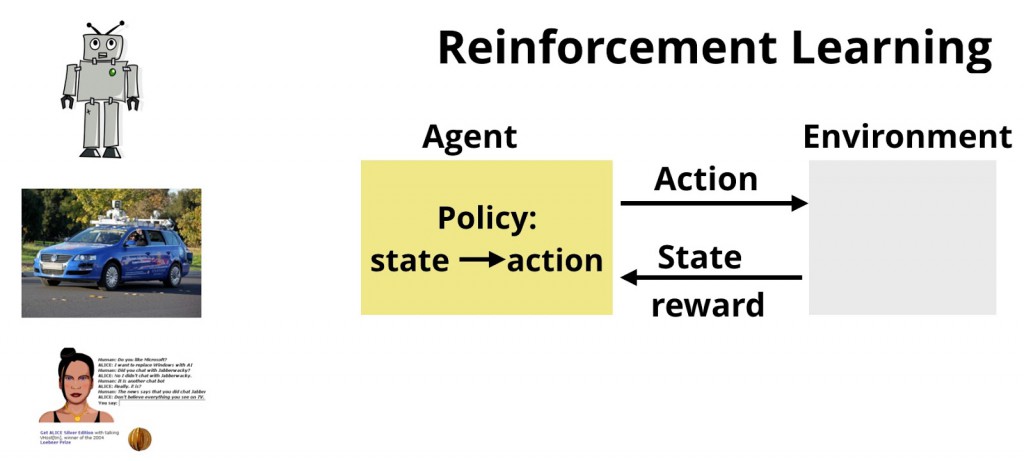
图1. 增强学习涉及到学习把测量和观察映射到行动
正如深度学习正在慢慢地成为数据科学家的工具集的一部分,类似的事情也会在持续学习上发生。但为了让数据科学家参与进来,工具和算法都需要变得更容易获得。这需要一套新的不同于在监督学习中使用的工具和算法。持续学习还需要一系列工具。这些工具可以运行并分析大量的涉及复杂计算图的模拟,当然理想情况是在非常短的延迟响应时间下。
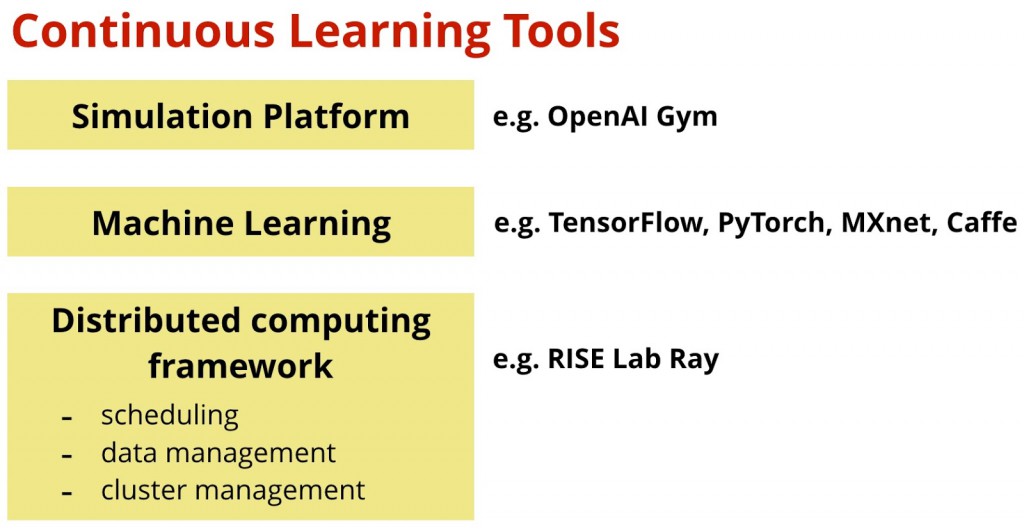
图2. 持续学习的典型工具集(或叫“堆栈” ),来源:Ben Lorica
加州大学伯克利分校的一个研究小组最近发布了一个开源分布式计算框架(Ray),它提供了一些用于增强学习的部分的补充。在复杂的应用程序中(比如自动驾驶汽车)会涉及到多个传感器和测量,因此能够快速地并行探索和运行模拟的框架会提供用户一个巨大的优势。Ray允许用户并行运行模拟,并提供一个Python API,让数据科学家可以使用它(Ray本身主要是用写C++写的)。当我们在增强学习的语境里看待Ray的时候,它是针对Python用户的一个可容错的通用分布式计算框架。它的创建者让别人使用Python在Ray之上编写和运行自己的算法变得非常简单,包括使用普通的机器学习模型。
为什么你需要一个机器学习库?什么算法对持续学习很重要?回想一下,在增强学习中,我们需要学习如何将观察和测量映射到一组动作中,同时尝试最大化一些长期的回报。最近的增强学习成功故事主要使用基于梯度的深度学习,但研究人员已经发现,其他的优化策略(比如进化策略)也是有帮助的。与从训练数据和目标结果开始的监督学习不同的是,在深度学习中只有很少的反馈,所以像神经进化这样的技术相比传统的梯度下降有竞争力。还有其他相关的算法可能成为用于持续学习模型的标准集合的一部分(例如这里介绍的关于利用最小化反事实后悔方法来进行德州扑克比赛)。Ray的创建者正在组装一个实现增强学习算法的通用集合的库,并提供一个简单的Python API供调用。
大多数公司仍处在学习如何使用和部署标准的(离线)机器学习的阶段,因此也许讨论现在持续学习还为时过早。不过现阶段就开始讨论这个话题的一个重要原因是这些技术对于将人工智能引入您的机构会变得非常必要。与其他任何新方法或技术一样,持续学习的起始点都是发现一些应用场景。在这些场景里持续学习可能比现有的离线训练方法有优势。我提供了一些场景,其中持续学习已经被部署或者研究已经表明有希望的结果(出来)。但是这些场景可能与您的机构的运营相去甚远。已经使用多臂强盗算法(推荐内容或评估产品)公司可能很快就会发现一些应用场景并成为持续学习的早期采用者。被用于开发人工智能教学机器人的技术也可能会扩展到涉及增加人类工人的其他应用领域(包括软件工程)。
许多公司正在意识到,在不少场景中机器学习模式在被部署到生产后不久就开始退化。好消息是,许多人工智能初创公司正在把持续学习加入他们开发的产品中。你可能没意识到,你的公司也许会在不久的将来就会开始使用增强学习。
相关资料:
- Ray:一个面向新兴的人工智能应用的分布式运行框架(Michael Jordan在2017 Strata Data 大会上的主题演讲)
- 机器人的深增强学习(Pieter Abbeel在2016年人工智能大会的演讲)
- 与人合作的汽车(Anca Dragan在2017年人工智能大会的主题演讲)
- 增强学习和OpenAI Gym介绍
- 神经进化(Neuroevolution):一种不一样的深度学习
- 增强学习的解释

Ben Lorica
Ben Lorica是O’Reilly Media的首席数据科学家和数据主题内容策略的主管。他已经在多个领域里(包括直销市场、消费者和市场研究、精准广告、文本挖掘和金融工程)进行了商业智能、数据挖掘、机器学习和统计分析的工作。他之前曾效力于投资管理公司、互联网创业企业和金融服务公司。






更多人工智能内容请关注2018年4月10-13日人工智能北京大会。