我们已经谈论数据科学和数据科学家有10年了。虽然对“数据科学家”的含义总是存在一些争议,但是我们看到了许多大学、在线学院和培训机构都已经提供数据科学的课程,并给予硕士学位、资格认证等等你能想到的名字。当我们只看统计数据时,事情是比较简单的。但简单并不总意味着健康,如果仅仅只是看对于数据科学家的需求,数据科学项目的多样性是不会展现出来的。
随着数据科学领域的发展,出现了不少很差的专业分类。企业会使用“数据科学家”和“数据科学团队”来描述多种角色,包括:
- 进行临时性分析和报告(包括BI和业务分析)的人员
- 负责统计分析和建模的人。他们在许多情况下会进行正式的实验和测试
- 越来越多的使用Notebook开发原型的机器学习建模者
而这个列表里并不包括DJ Patil和Jeff Hammerbacher这样思考和创造“数据科学家”这个词的人:即从数据来构建产品的人。这些数据科学家比较类似机器学习建模者,除了他们构建的东西:他们是以产品为中心,而不是研究人员。它们通常工作于很多数据产品。无论是什么角色,数据科学家不仅仅是统计学家。他们通常拥有科学博士学位,并拥有处理大量数据的实践经验。他们几乎总是很好的程序员,而不仅仅是R或其他一些统计软件包的专家。他们了解数据采集、数据清理、原型设计、将原型转化为生产系统、产品设计、建立和管理数据基础架构等。实际上,他们原来是硅谷“独角兽”的原型:罕见而且很难雇用。
重要的不是我们要有明确定义的专业。在蓬勃发展的领域,总是会有巨大的灰色地带。使“数据科学”如此强大的核心是认识到数据比精算统计、商业智能和数据仓库更强大。打破将数据人员与机构的其他部分(软件开发、营销、管理、人力资源等)分离的孤岛是数据科学的独特之处。其核心概念是数据适用于所有事情。数据科学家的首要任务是收集和使用所有数据。没有什么部门可以例外。
当找不到这些独角兽时,我们就把他们拥有的技能分解成了不同的专业。进而,当数据科学诞生后,这些技能人员开始出现。我们突然开始看到了数据工程师。数据工程师并不主要是数学家或统计学家,尽管他们对数学和统计学也不陌生。他们并不主要是软件开发人员,尽管他们对软件开发也不陌生。数据工程师负责数据技术栈的操作和维护。他们可以把在笔记本电脑上开发的原型导入在生产系统中,并可靠地运行。他们负责了解如何构建和维护Hadoop或Spark群集,以及数据生态系统的其他工具:数据库(如HBase和Cassandra),流式计算数据平台(Kafka、Spark Streaming、Apache Flink )和其他更多的部件。他们知道如何使用和运维云基础设施,能充分利用Amazon Web Services、Microsoft Azure和Google Compute Engine等云平台。
现在我们已经进入了“数据科学”的第二个十年,并且机器学习现在已经逐渐自成一体。我们看到了“数据工程师”的逐步演进。2015年一篇来自Google被广泛引用的文章强调了这样一个事实,即现实世界的机器学习系统除了分析模型之外还有很多的组成部分。企业开始专注于建立数据产品,并把她们采用的技术投入生产系统中。在任何应用中,严格的“机器学习”的部分是相对较小的:(因为)需要有人维护服务器基础设施,监控数据采集管道,确保有足够的计算资源等。为此,我们开始听到更多的企业组建机器学习工程师团队。但这并不是一个全新的专业,因为机器学习(特别是深度学习)在数据科学界快速的扩散,数据工程师一定要向前看一步。但是如何区分一个机器学习工程师和数据工程师?
在一定程度上,机器学习工程师会做软件工程师(和好的数据工程师)一直做的工作。以下是机器学习工程师的几个重要特点:
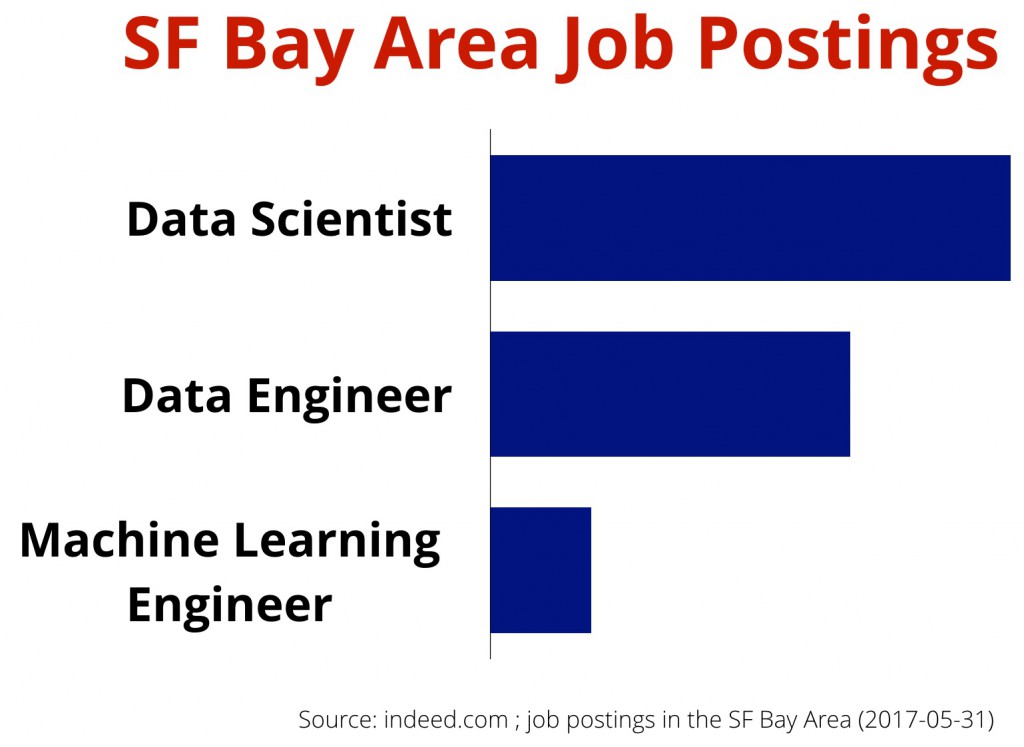
图1 图片由Ben Lorica提供
- 他们比典型的数据科学家有更强的软件工程技能。机器学习工程师能够与维护生产系统的工程师(有时就在同一个团队中)配合工作。他们了解软件开发方法、敏捷实践以及现代软件开发人员使用的各种工具:从Eclipse和IntelliJ等IDE到持续部署管道的组件等。
- 由于他们的重点是使数据产品在生产环境中工作,所以他们会思考周翔,并权衡日志记录或A / B测试基础架构等组件。
- 他们能够针对监控生产系统中的数据产品的具体问题快速反应。有很多应用程序监控的资源,但是机器学习有进一步的要求。数据管道和模型可能会过时,需要重新训练。或者可能会受到对手的某些方式的攻击,这些方式对传统的Web应用程序来说可能是无意思的。机器学习系统是否可以通过破坏供给它的数据的管道来误导?是可以的。而机器学习工程师将需要知道如何检测到这些破坏。
- 深度学习的兴起导致了一个相关但更专业的职位:深度学习工程师。我们也见到了“DataOps”,尽管对于这些术语意味着什么似乎没有达成一致的意见(到目前为止)。
机器学习工程师参与软件架构和设计,他们也了解A / B测试的做法。但更重要的是,他们不仅仅是“了解”A / B测试,他们还知道如何在生产系统上进行A / B测试。他们了解日志和安全性等相关的问题;他们知道如何使日志数据对数据工程师有用。这里没有什么是特别新的东西:这是角色的深化,而不是变化。
机器学习与“数据科学”有什么不同?数据科学显然是更具包容性的术语。但是,深度学习的工作方式有很大的不同。想象数据科学家探索数据是很容易的:查看替代方法和不同的模型来找到一个有用的。像Tukey的《探索性数据分析》这样的经典书籍为大部分数据科学家们所做的事情设定了基调:探索和分析大量的数据,以找到隐藏在其中的价值。
深度学习显著地改变了这个模式。你并不直接和数据工作。你知道你想要的结果,但是你会让程序发现它。你想构建一个能打败最好的围棋冠军的机器,或者正确地标记照片,或是在语言之间进行翻译。在机器学习中,这些目标是不能通过仔细的探索来实现的。在许多情况下,有太多数据可以在太多的意义上探索,并且维度非常多(围棋的维度是什么?或是一种语言的维度是什么?)。机器学习的未来希望是它能自己构建模型:它自己进行数据挖掘和调优。
因此,数据科学家也不会做太多的数据探索。他们的目标不是在数据中找到意义:他们认为这个意义已经在那里了。相反,他们的目标是构建可以分析数据并产生结果的机器:创建一个可用的神经网络,它可以通过调优产生可靠的结果。他们也不太会重视统计结果了。事实上,机器学习的圣杯是“民主化”,即达到机器学习系统可以由某领域的专家而不是AI专业的博士来产生。我们希望围棋玩家能够构建下一代AlphaGo,而不是研究者。我们想要由一名说西班牙语的人来构建自动翻译成西班牙语的引擎。
这种变化对机器学习工程师有着相应的影响。在机器学习中,模型不是静态的。随着时间的推移,模型可能会过时。需要有人来监控这个过程,从而在必要时重新训练模型。这对初始构建系统的开发人员来说是没有吸引力的工作,但它的技术性很强。此外,这也需要这个人能了解监控工具,不过这些工具尚未在数据应用程序中被考虑设计出来。
任何从业的软件开发人员或IT人员都应该了解安全性。据我们所知,还没有针对机器学习系统的重大攻击。但他们会成为越来越诱人的目标。机器学习有哪些新类型的漏洞存在?是否有可能对训练数据“投毒”,或是强制系统在不应该的时候重新训练模型?因为机器学习系统是自我训练的,我们应该考虑到会出现全新类型的漏洞。
随着工具变地越来越好,我们将会看到更多的数据科学家可以将结果转变为生产系统。云环境和SaaS工具使数据科学家更容易将其数据科学原型部署到生产系统中。相应的开源工具,如Clipper和Ground(加州大学伯克利分校的RISE实验室的新项目),也开始出现。但是,我们仍然需要数据工程师和机器学习工程师:他们有数据科学和机器学习方面知识,了解如何在生产系统中部署和运行数据产品,知道如何应对机器学习产品面临的挑战。他们是终极的“机器学习循环中的人类”。
相关资源:
- 《什么是数据科学》?
- 《什么是实践中真正在用的数据科学系统?》,Mikio Braun介绍如何将数据科学引入生产系统中
- “当模型开始捣蛋:在生产系统中使用机器学习的难得的经验教训”。即将到来的“Strata数据”纽约大会上的一个演讲
- 《成为一名机器学习工程师》
- 《数据柔道——将数据转换成产品的艺术》,DJ Patil著