深度学习在很多商业应用中取得了前所未有的成功。大约十年以前,很少有从业者可以预测到深度学习驱动的系统可以在计算机视觉和语音识别领域超过人类水平。在劳伦斯伯克利国家实验室(LBNL)里,我们面临着科学领域中最具挑战性的数据分析问题。虽然商业应用和科学应用在所有分析任务方面(分类、聚类、异常检测等)存在着相似之处,但是之前的经验让我们没办法相信科学数据集的潜在复杂性会跟ImageNet数据集有可比性。深度学习方法是否已经强大到可以使科学分析任务产生最前沿的表现?在这篇文章中我们介绍了从不同科学领域中选择的一系列案例,来展示深度学习方法有能力促进科学发现。
我最近跟O’Reilly的Jon Bruner在Bots Podcast探讨了这些相关话题。我们讨论了LBNL超级计算中心的架构,及其推进深度学习库整合进这一架构中的工作,并探讨了一些引人瞩目的可扩展到极大数据集的深度学习用例,例如对象或模式检测。下面是我们的采访音频:

使用概率自编码器对星系形状建模
贡献者:Jeffrey Regier,Jon McAullife
星系模型在天文学方面有很多应用。例如一个星系外观轻微的变形可能表示附近有暗有物质的引力拉扯。暗物质的总量被假定为普通物质的五倍,但是对于它是否存在并没有一个定论。如果没有一个看起来未变形的星系形状模型,就没有推断星系存在扭曲的基础。
因为星系形状有很多共同点,所以适用于星系样本的模型可以准确地表示整个星系群。这些共享特征包括“螺旋臂”(见下图1)、“环”(图2)和即使是在不规则的星系中也存在的随着距离远离中心降低的亮度(图3)。这些共同点是高层次的特征,因此不容易在单个像素的级别上描述。
到目前为止,大多数神经网络已经在监督学习问题上取得了成功:给定输入、预测输出。如果预测的输出与正确答案不符,则会调整网络的权重。而对于星系模型来说则没有正确的输出。所以我们在寻求一个将星系图像赋予高概率的图像概率模型,同时所有可能图像的概率总和为一。神经网络在这个模型中指定一个条件概率。
在概率模型中可以从一个多变量标准正态分布中得到一个不可观测的随机向量$z$。神经网络将$z$映射到一个平均值和一个协方差矩阵,这就参数化了高维多元正态分布,星系图像的每个像素对应一维。这个神经网络可以有尽可能多的有助于表示映射的网络层和节点。图4显示了某个特定星系图像的多变量正态分布的平均值,图5显示了协方差矩阵的对角线。最后,从这个多变量正态分布中抽样一个星系图像。
可以选择从我们的过程的两个角度中的任一个来从星系图像里学习神经网络权重:算法和统计。算法上讲,我们的程序训练了一个自编码器。输入是一张图片,低维向量$z$是添加过噪声的网络中间的一个窄层,输出是输入图像的重建。损失测量的是输入和输出的差异。不过,我们选择的损失函数和添加到自编码器中的噪声类型遵循统计模型。基于这些选择,训练自动编码器相当于通过一种称为“变分推断”的技术来学习不可观测向量$z$的近似后验分布。一个星系的后验分布会告诉我们所想知道的:星系最可能出现的样子(例如后验的模式)和其外观不确定性的数量。它把我们关于星系通常看起来的样子的先验经验跟我们从星系图像学习到内容相结合。
我们使用基于Caffe的Julia神经网络框架Mocha.jl来实现了所提出来的变分自编码器(VAE)。我们使用了43444张星系图片来训练我们的模型,每张图片都基于一个主导的星系裁剪并缩小到69 x 69像素。VAE模型相对于常见的使用双变量高斯密度的星系模型,会对保留数据集里的97.2%的星系图片赋予更高的概率。

图1 一个典型的螺旋星系。 资料来源:欧洲航天局与美国航空航天局维基共享资源

图2 环形星系。 资料来源:美国航空航天局、欧洲航天局和哈勃遗产团队(AURA / STScI)的维基共享资料

图3 不规则形状星系。 资料来源:欧洲航天局/哈勃、美国航空航天局、D. Calzetti(马萨诸塞大学)和LEGUS小组的维基共享资料

图4 某个特定星系的69×69像素图像,其中每个像素是平均强度。 来源:由Jeffrey Regier和Jon McAullife生成,并经许可使用
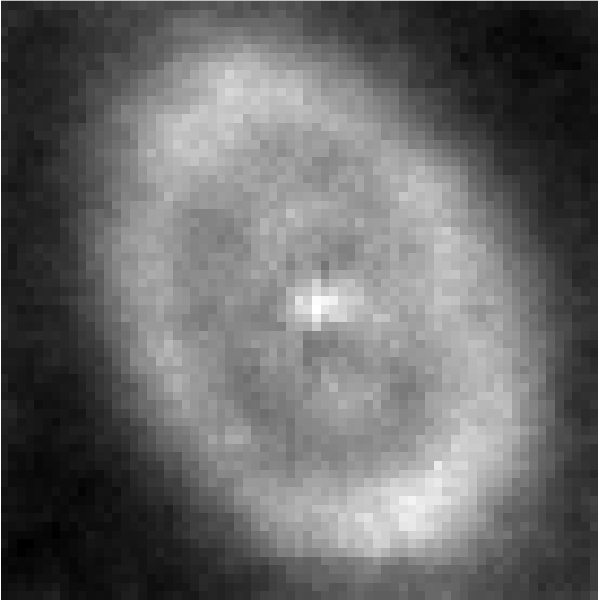
图5 特定星系的69×69像素图像,其中每个像素是强度的方差。 资料来源:由Jeffrey Regier和Jon McAullife生成,并经许可使用
在气候模拟中寻找极端天气事件
贡献者:Evan Racah,Christopher Beckham,Tegan Maharaj,Yunjie Liu,Chris Pal
极端天气事件对生态系统、基础设施和人类健康有着巨大的潜在风险。基于卫星和气象站的观测记录来分析极端天气,以及在未来气候条件的模拟中描述极端天气变化是一项重要的任务。通常气象界是通过手工编码、多变量阈值条件来指定模式标准。这种标准多是主观的,气象界通常对于应该使用的具体算法很少有一致的意见。我们已经探索了一个完全不同的范式,也就是训练一个基于人类真实标注数据的深度学习系统来学习模式分类器。
我们的第一步是考虑以热带气旋和大气河流为中心的剪切图片集的监督分类问题。我们首先确定了5000-10000个剪切图像,并通过在Speamint中进行超参数调优来训练了一个Caffe中的香草卷积神经网络。我们发现对监督分类任务可以获得90%-99%的分类准确度。下一步就是考虑用一个统一的网络对多种类型模型(热带气旋、大气河流、超热带气旋等)同时进行模式分类,并利用包围盒来定位这些模式。这是对这个问题一个更高级的半监督的思路。我们当前的网络如图6所示。
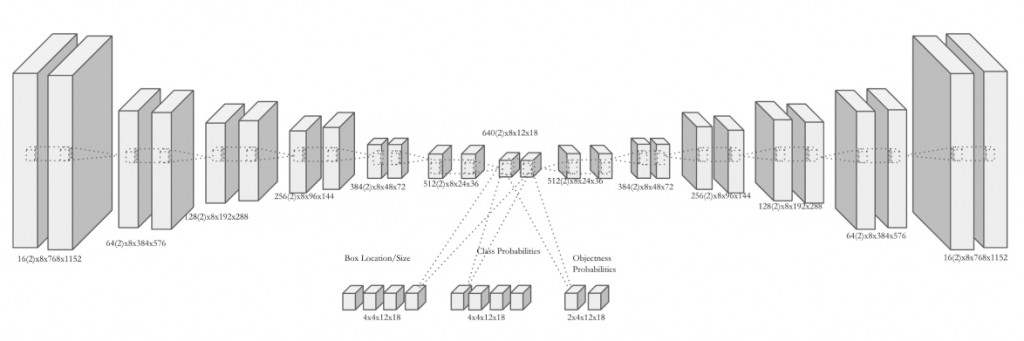
图6 气候模式定位及分类的半监督网络结构。图片由Evan Racah,LBNL友情提供
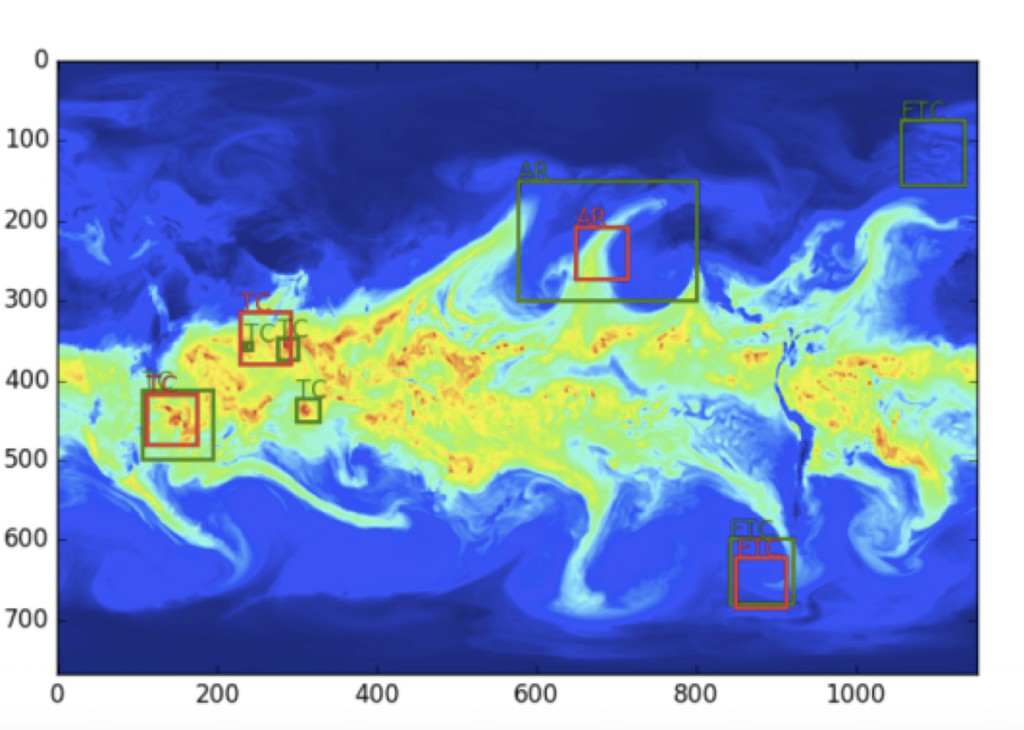
图7 天气模式及其位置的示例结果(真实状况:绿色,深度学习预测:红色)。 图片由Evan Racah,LBNL友情提供
图7显示了通过半监督架构获得的一些示例结果。虽然对架构的进一步调整还正在进行中,但是底层群集的t-SNE图显示了该方法有能力在数据集中发现新的相干流体流量结构。目前的架构运行在气象数据的即时快照上,我们正在扩展模型以包含时间来得到更精确的预测。
学习宇宙质量天体图中的模式
贡献者:Debbie Bard, Shiwangi Singh, Mayur Mudigonda
即将进行的天文巡天项目会获得数百亿个星系的测量数据,从而能够精确得到描述暗物质特性的参数,这些暗物质是加速宇宙扩展的力量。例如可以使用引力透镜技术用宇宙中的常规物质和暗物质来构建天体图。描绘这些质量天体图让我们可以区分不同的暗物质理论模型。
我们探索了新型的深度学习技术来找出快速分析宇宙天体图数据的新方法。这些模型提供了识别物质天体图中意想不到的功能的潜力,从而为宇宙的结构给出了新的见解。我们开发了一个非监督的去噪卷积自编码模型,用来从我们的数据中直接学习一个抽象表示。该模型使用了一个卷积-去卷积架构,它从一个理论宇宙的模拟中获得输入数据(用二项式噪声去破坏数据以防止过拟合)。我们使用了四层卷积层、两个瓶颈层和四个去卷积层,并用Lasagne包实现。它使用了10000张质量天体图的图片进行训练,每张图片的大小为128×128像素。我们的模型能够使用梯度下降有效地最小化输入和输出之间的均方误差,从而产生一个在理论上能够广泛解决其他类似结构化问题的模型。我们使用这个模型成功地重建了模拟的质量天体图并识别它们内部的结构(见图8)。我们还确定了哪些结构具有最高的重要性,也就是哪些结构表达了最典型的数据,参见图9。我们注意到在我们的重建模型中最重要的结构是在高质量集中的周围,这对应于大的星系集群。
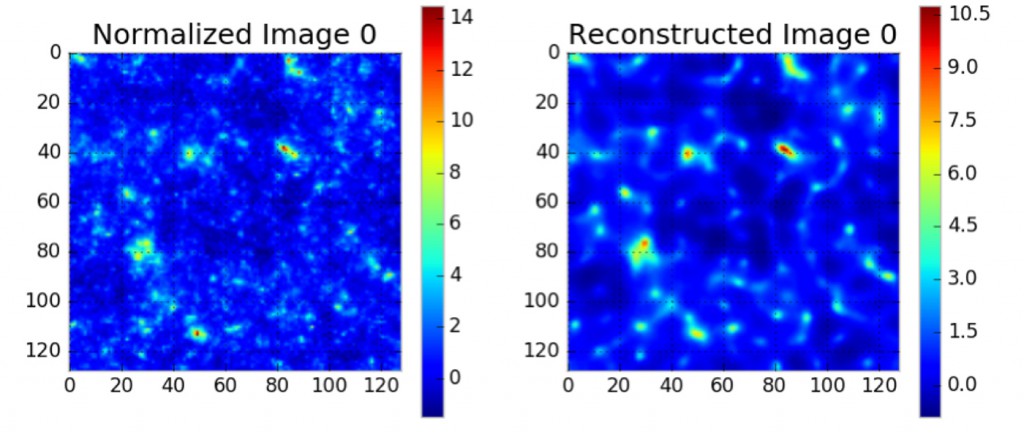
图8 左图:来自宇宙模拟的质量天体图。右图:使用我们的卷积自编码器重建的此天体图。我们平滑了这个天体图,因此丢失了小的细节,但天体图的特征被精确地复制了。图片由Shiwangi Singh和 Debbie Bard,LBNL友情提供
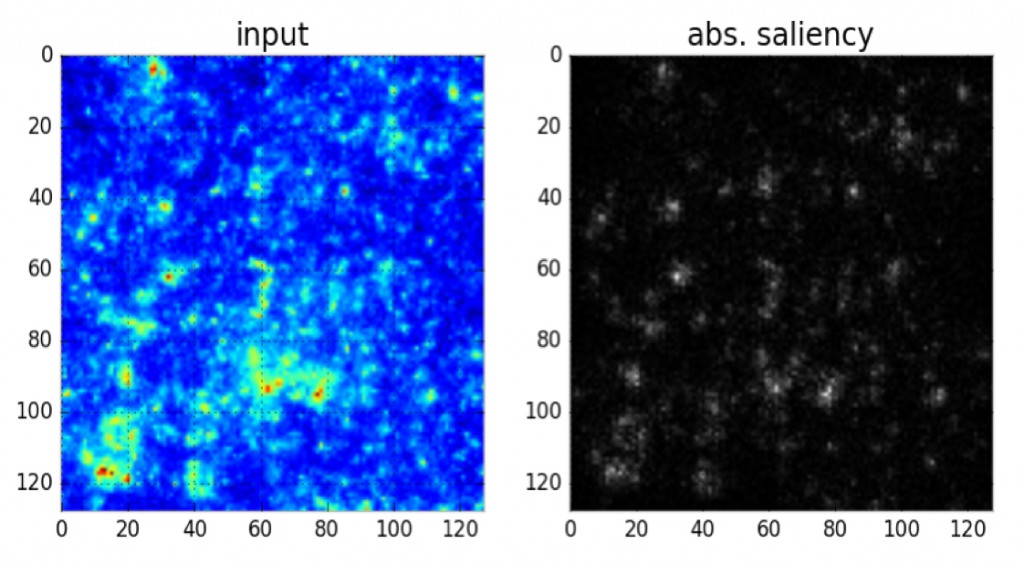
图9 左图:来自宇宙模拟的质量天体图。右图:使用卷积自编码器重建的此天体图的最重要特征的显著图。我们看到高质量集中区域比低质量区域更为重要。图片由Shiwangi Singh和Debbie Bard友情提供
我们还开发了一个具有四个隐藏层的监督卷积神经网络(CNN)用以基于两种不同的模拟理论模型来进行宇宙质量图分类。CNN使用softmax分类器最小化估计分布和真实分布之间的二进制交叉熵损失。换句话说,给定一张从未见过的收敛的天体图,训练好的CNN模型能够概率地决定最拟合数据集的理论模型。使用两个理论模型的5000张天体图(128×128像素)进行训练,这个初步结果表明我们可以以80%的精度来分类产生收敛的天体图的宇宙模型(见图10)。
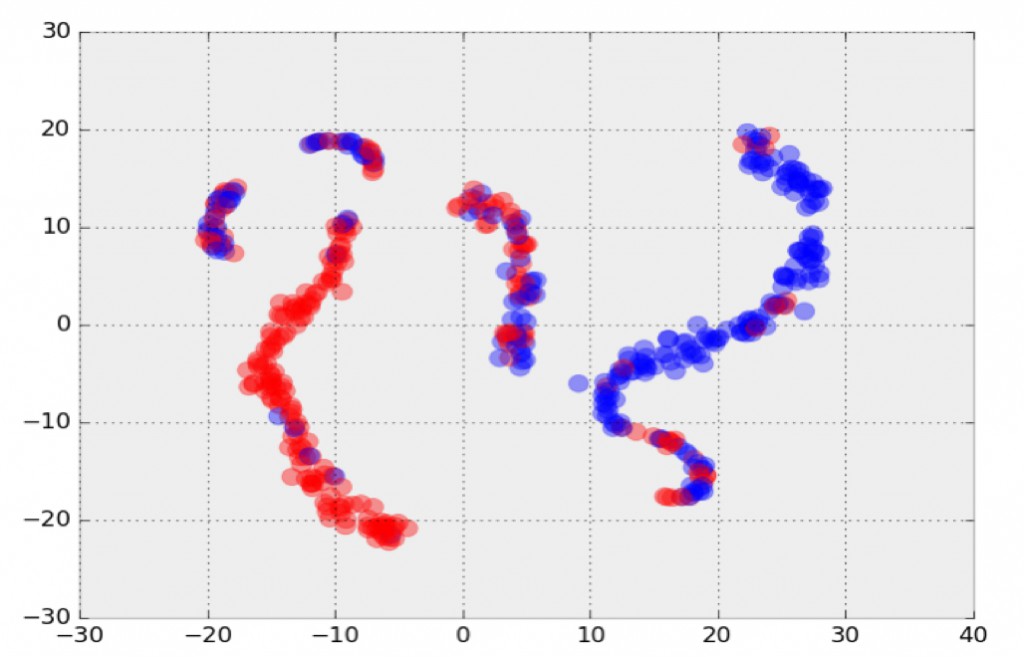
图10 从质量天体图中提取的用2维表示的特征向量t-SNE图。红色和蓝色分别代表了来自两种不同的理论宇宙模型中的质量天体图。图片由Shiwangi Singh和Debbie Bard, LBNL友情提供
从人类神经记录中解码语音
贡献者:Jesse Livezey, Edward Chang, Kristofer Bouchard
能够看似轻松地产生由复杂语法结构和声学模式构成的语音的能力是人类所独有的。Penfield和Boldrey在20世纪30年代的开创性工作表明,人体不同部分(包括声道)都跟大脑的空间局部区域相关联。大脑是如何跨越一组相关联的大脑区域来协调声道的发音器,这个神经活动的时间模式(诸如图11里所示的)仍然是一个悬而未决的问题。
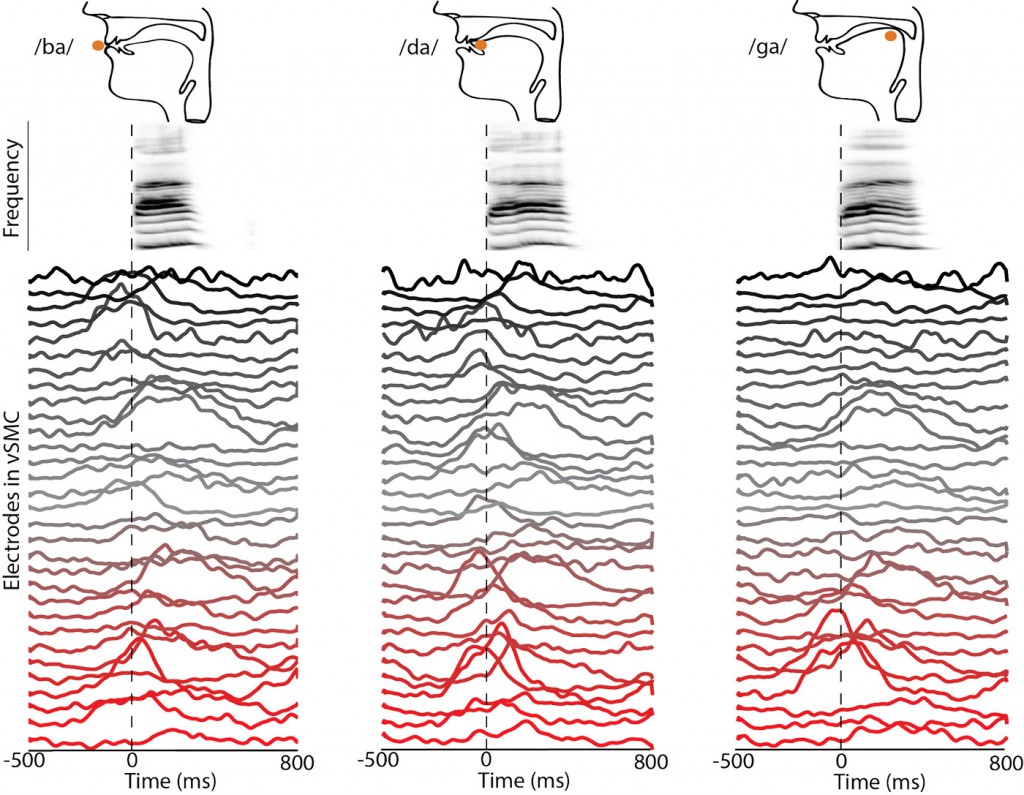
图11 说话过程中人类皮质表面的神经记录。第一行显示了发出辅音“b”、“d”、“g”时的声道的图解示意图。而中间行显示了发出语音“ba”,“da”和“ga”的声谱(以不同频率作为时间的函数的声功率)。下面的彩色轨迹显示了在语音中神经活动记录的时空模式。这些语音声音是通过皮质活动的重叠而又独立的时空模式产生的。图片由Jesse Livezey and Kris Bouchard友情提供
大脑由非线性处理单元(神经元)组成,其表现为一种普通的信号被连续处理的层次结构。因此,我们假设深层神经网络(DNN)的分层及非线性处理将会跟语音生成的复杂神经动力学相匹配。在有着数百万样本的大且复杂的数据集上,DNN已经被证明了其性能在许多任务中胜过传统方法。然而这种先进方法还没有在神经科学分析任务中得到证实,因为它们的数据量要小的多(数千个)。
在最近的工作中,我们发现即使在通过神经科学实验获得的相对较小的数据集上,DNN方法优于传统的解码(即翻译)大脑信号产生语音的方法,达到了最先进的语音分类性能(高达39%的准确度,是随机瞎猜的25倍多)。此外随着训练数据集的增大,DNN的表现会比传统的分类器更好,其在相对有限但非常有价值的数据上实现了回报最大化。输入数据集包括85个频道和250个时间采样信号,分成了1到57个类别。一个单独主题的数据集通常只有2000个训练样本,需要大量的超参数搜索以得到最佳表现。最好的网络具有一个或两个具有双曲正切非线性的隐藏层,并使用Theano库在GPU和CPU上进行训练。每个模型训练相对较快(30分钟),但是很多模型已经在超参数搜索中训练好了。这些结果表明,DNN将来可能成为大脑-机器接口的最先进的方法,这需要更多的工作来找到在小型数据集上训练深度神经网络的最佳实践。
除了对义肢修复至关重要的大脑信号的解码能力,我们还研究了DNN用作揭示神经科学结构的分析工具的能力。我们发现DNN能够在嘈杂的单次实验录音中提取语音组织的一个丰富层次结构。提取的层次结构(见图12)提供了对语音控制的皮质基础的洞察。我们期望应用于神经科学中的数据分析问题的深度学习能够随着更大和更复杂的神经数据集的发展而发展。
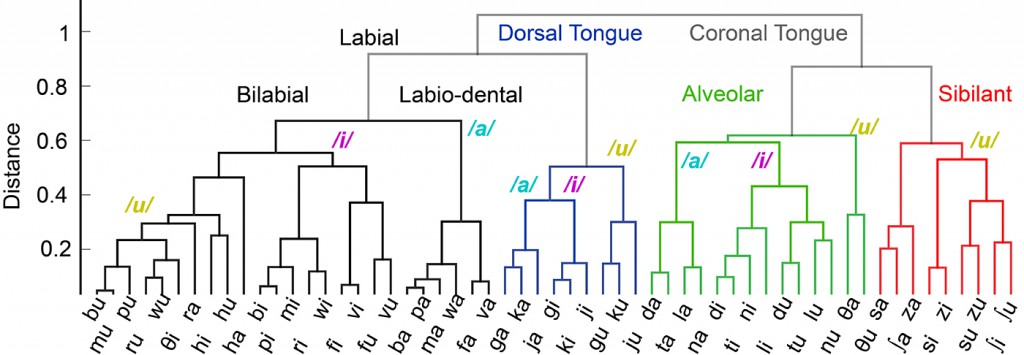
图12 由DNN训练的音节之间的混淆(即误差)构成的树状图,用以分类来自人类大脑活动的语音。我们观察到的语言特征的层次结构,提供了对语言运动控制的皮质组织的新见解。图片由Jesse Livezey和Kris Bouchard友情提供
使用去噪自编码器聚类大亚湾数据
贡献者:Samuel Kohn,Evan Racah,Craig Tull,Wahid Bhimji
大亚湾反应堆的微中子实验通过测量反微中子的特性和在一个核反应堆中由β-衰变产生的基本的亚原子粒子,来探索能够超过粒子物理学标准模型的物理模型。物理学家监测大容量探测器介质(称为液体闪烁体),并寻找来自反中微子相互作用的特有的双闪光。其它背景过程也会产生闪光。有些背景闪光(如宇宙射线μ介子)很容易识别,但是其它的闪光(如由μ介子产生的锂-9同位素的衰变)跟微中子信号非常相似。将反中微子信号跟背景做分离是一项艰巨的任务。这可能会导致系统性的不稳定和信号效率降低,因为真正的反微中子事件可能会在无意中被忽略。
目前大亚湾数据分析使用时间和总能量来区分信号与背景。但是在光空间分布上还存在信息,因此这可能会存在更好的区分方法。通过使用无监督的深度学习技术,我们可以学习到识别与锂-9衰变不同的反微中子信号的特征。利用识别特征的知识,我们可以更新分析模型的分界以增强其识别能力并提高微中子测量的精度。
在一个案例研究中,无监督深度学习用于从已知的背景中区分由两个不相关的闪光引起的反微中子信号的能力是显而易见的。在我们的案例研究中,使用真实数据而不是模拟数据来训练神经网络。这在监督学习中是不常见的,但它在无监督制度中发挥了很好的作用,这是因为它消除了模拟数据和实际数据之间的差异导致的不确定性和偏差。之前的这个研究使用无监督学习来解决大亚湾实验中有关信号与背景的问题。
我们使用去噪卷积自编码神经网络(图13),其分为三个阶段:
- 损坏阶段:三分之一的图像像素被设置为零;
- 编码阶段:物理事件的图像被压缩成编码;
- 解码阶段:解压编码以尝试恢复原始物理事件图像。
为了成功恢复原始的未破坏图像,自编码器必须学习如何从所提供的损坏图像中推断丢失的信息。当被训练正确后,自编码器会创建包含输入图像的重要区分特征信息的编码。
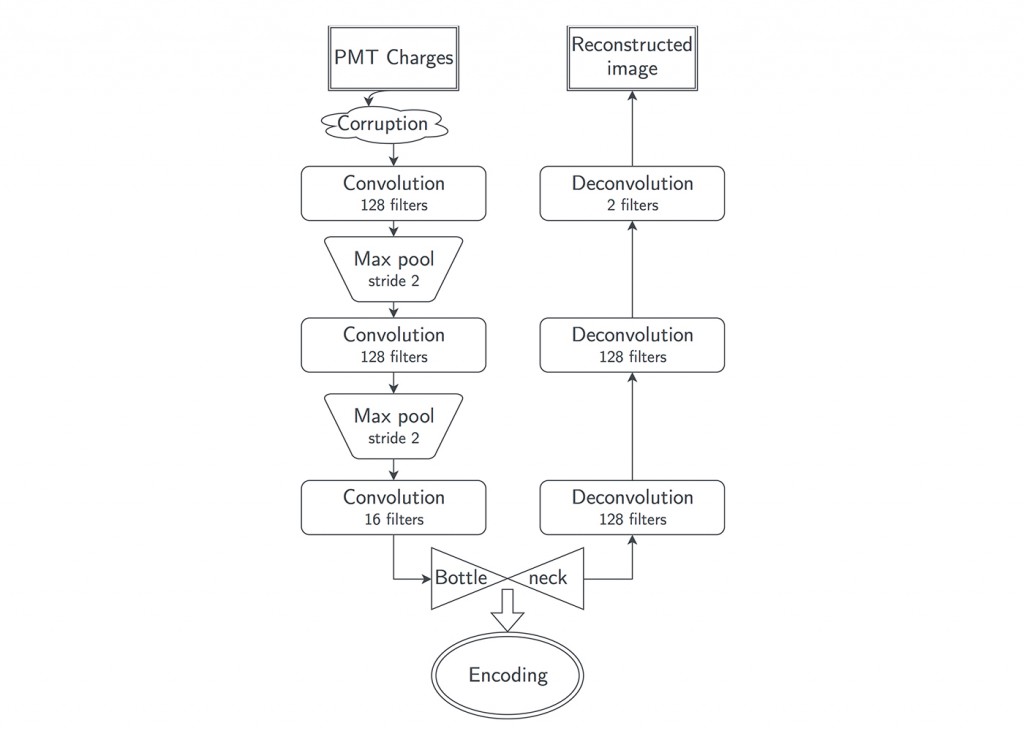
图13.用于本研究的去噪自编码器的架构。图片由Samuel Kohn, LBNL友情提供
通过使用t-SNE维度缩减算法,我们可以在2维笛卡尔平面上显示16维编码。在图14中,神经网络很明显地将我们的信号事件跟意外背景区分开,而不是对单个事件标签进行训练。这是一个有前途的进步,它有助于验证使用无监督神经网络来训练真实数据。我们会继续使用意外背景事件的实验数据来改进网络架构,并确定哪些特征对神经网络重要。等技术进一步发展,我们会将其应用于分离锂-9背景的物理问题。
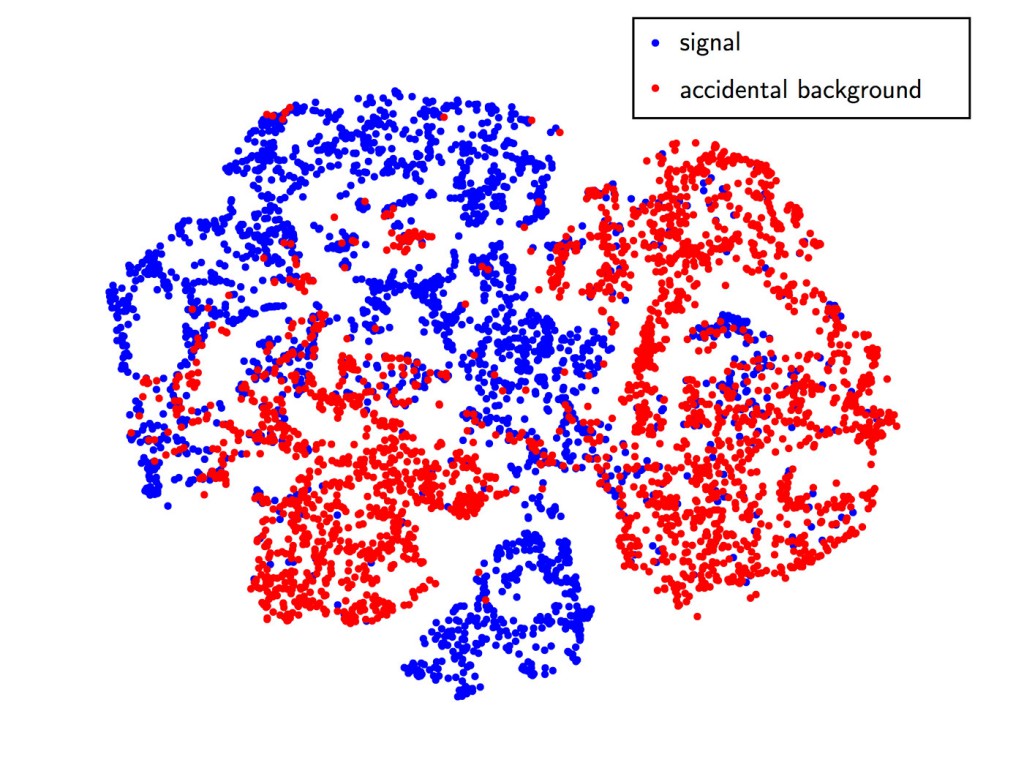
图14 显示信号事件(蓝色)和背景事件(红色)的编码的t-SNE图。蓝色与红色的分离表示神经网络识别出了不在背景中的信号特征,反之亦然。图由Samuel Kohn,LBNL友情提供
在大型强子对撞机(LHC)上进行新的物理事件的分类
贡献者:Thorsten Kurth,Wahid Bhimji,Steve Farrell,Evan Racah
大型强子对撞机(LHC)让质子以能获得的最高能量每秒碰撞4000万次。每次碰撞会产生能在诸如ATLAS检测器(图15)这样的仪器中检测到的粒子喷雾,其中电子设备的数亿通道试图发现前所未知的新粒子。LHC的高曝光度升级(HL-LHC)版预计会使碰撞速度提高一个数量级。来自当前检测器的数据已经达到数以百计的千兆字节。处理这些巨大且复杂的数据的唯一方法就是使用检测器上的“触发器”和离线数据分析的过滤器来快速过滤掉大部分数据。在触发器对数据进行采样完成后(大约每秒200个事件),再将其重建为诸如粒子轨迹和能量沉积物的对象,每个事件降低到数百维。然后进一步采样得到分析数据,其具有取决于感兴趣的特定物理现象的数十个维度。图16展示了一个碰撞事件所展示出的这些检测器信号和更高级重建对象。
2013年诺贝尔物理学奖颁给了希格斯玻色子理论,是因为其在LHC中直接检测出这种粒子。希格斯玻色子完成了粒子物理的标准模型,而超越标准模型的新物理学的确切性质并不为人所知。因此触发器、重建和物理学分析算法的准确性和速度会直接影响到实验发现新现象的能力,且比以往任何时候的影响都更多。已经清楚的是,当前用于过滤数据的方法和算法将难以从计算量方面等比例扩展到LHC的下一阶段,并且它们有错失更多新奇的新物理学信号的风险。因此探索创新的有效的方法来进行数据过滤是至关重要的。使用深度学习以初始检测器信号或原始数据的尺寸和速率来进行物理学分析的方法有可能会产生改变我们对基本物理学理解的新发现。
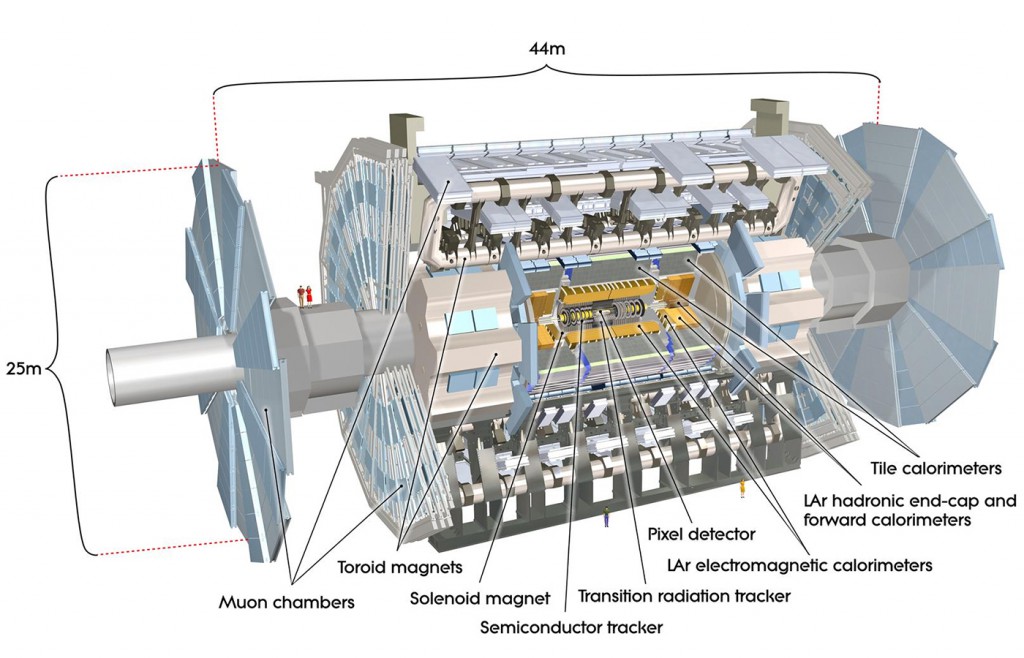
图15 LHC的ATLAS检测器。 图片由CERN友情提供,经许可使用
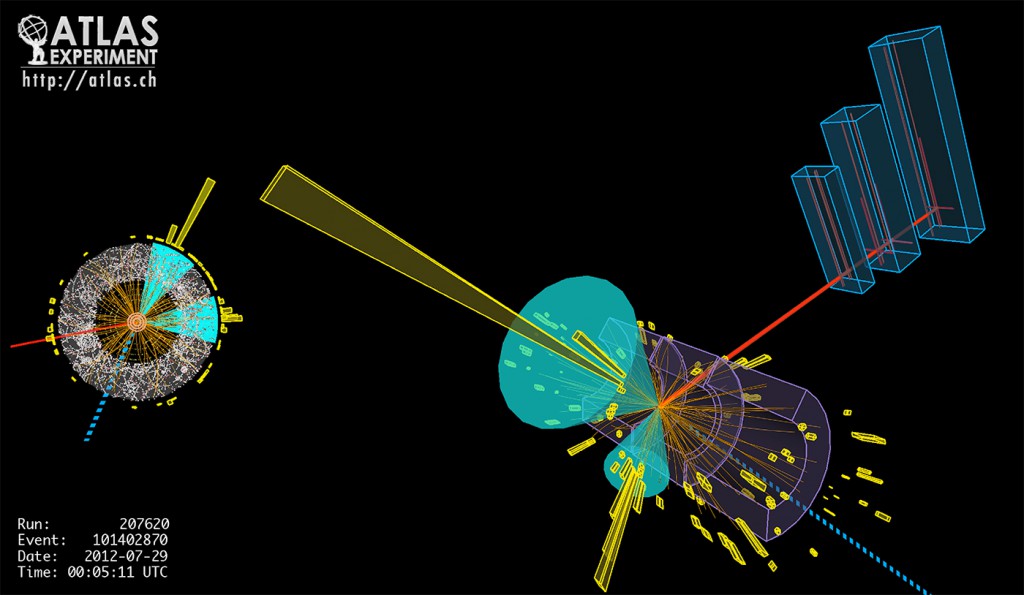
图16 ATLAS检测器中的粒子碰撞,显示了量热计中的沉积物和重建的喷设流。 来源:ATLAS实验,CERN版权所有,经许可使用
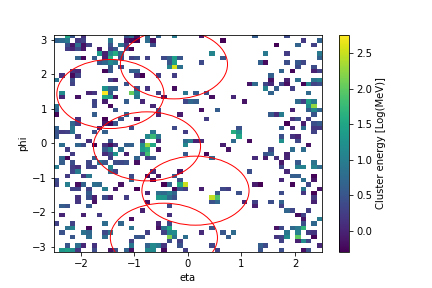
图17 作为卷积神经网络的输入的模拟图像,其来自于模拟LHC检测器的“量热计”部分的信号。模拟器是由仿真包Pythia和Delphes生成的。图片由Wahid Bhimji友情提供
深度学习提供了学习新型选择过滤器的可能性,用以提取比现有方法更精确的稀有的新物理信号,更灵活的可选择的新物理信号,并可以在大维度的输入数据(对应于检测器的通道)上运行提取计算。我们正在探索对新物理学的模拟数据训练分类器,以及仅使用背景(已知标准模型)样本来训练的异常检测算法。从粒子物理检测器中输出的信号可以被认为是图像(如图17),因此我们可以使用卷积架构。我们用于分类的神经网络的示例架构如下图所示。
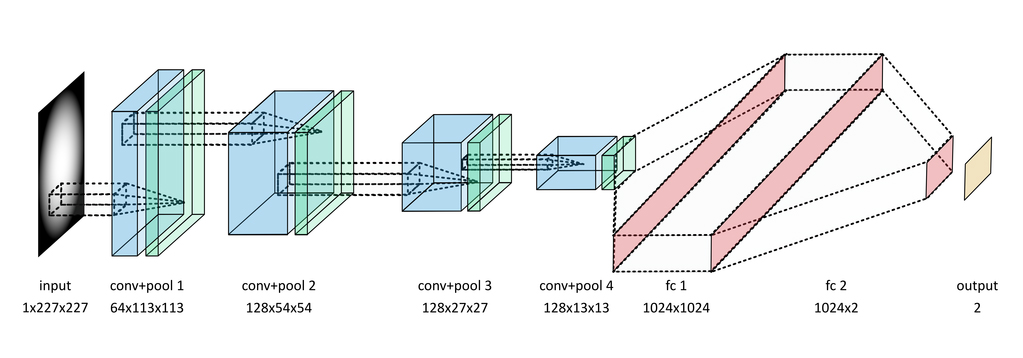
图18 LHC用于数据分类的示例架构。图片由Thorsten Kurth友情提供
我们的方法是新颖的。它首先使用来自检测器的数据,然后使用高分辨率图像(目前为227×227像素)将其重建为高级物理对象。这使我们能够学习更多的敏感模式,其可能不会被现有的物理算法所发现。使用大型模型和数据集需要扩展到跨越多个计算节点进行,这对于科学领域的深度学习也是新颖的。
我们目前实现的分类性能超过了通常用于选择这种物理对象的高级重建特征的简单选择方法,从而证明了这些类型的架构的适用性。我们还将这些架构扩展到大的计算资源,并开始探索不需要模拟新的物理学研究兴趣的异常检测。
存在的挑战
在回顾了一些深度学习的实际应用之后,我们总结出了以下挑战(这些挑战可能是科学应用领域所特有的):
- 性能和规模:深度学习方法在计算方面上是昂贵的。我们目前的实验能够处理1到100GB大小的数据集,在多核架构上要花费一天到一周的时间进行收敛。这对于超参数调优来说是不允许的。提高多核架构的单节点性能并在O(1000)节点上使用数据和模型并行运算来扩展网络是非常必要的。
- 复杂的数据:科学数据有许多不同的格式和大小。 2维图像可以有3-1000个通道,3维结构化和非结构化的网格是很常见的,稀疏和密集的数据集在某些领域是很普遍的,并且经常会遇到编码了重要关系的图形结构。深度学习方法/软件能够对这些数据集进行操作是很重要的。
- 缺乏标注过的数据:科学家们无法轻松的访问大量的高质量的标注过的图像。即使有些领域自己组织和进行打标签的活动,我们也不可能拥有高质量的像ImageNet风格的包含数百万图像的数据库。许多科学领域将始终会在无监督(也就是没有标注数据)或者半监督(也就是某些类仅有少量的标注过的数据)的架构下进行。因此深度学习研究在有限的训练数据的情况下能够继续表现出令人信服的结果是非常重要的。
- 超参数调优:各学科领域的科学家对调整网络配置(卷积层数量和深度)、非线性/汇集函数的类型、学习速率、优化方案和训练体系等他们领域的具体问题的直觉是有限的。为了将深度学习更广泛地应用于科学领域,打包自动调整这些超参数的功能是很重要的。
- 可解释性:与可能可以接受一个黑盒子但近乎完美的预测器的商业应用来说,科学家需要了解并能向本学科的其他成员解释神经网络学习到的功能。他们需要了解学习了哪些特征、这些特征是否有物理意义或见解,以及学习到的特征的非线性函数是否跟物理过程类似。在一个理想的情况下,函数和特征的选择会受到我们对科学学科理解的约束。目前这个重要环节是缺失的,我们希望下一代深度学习研究人员能够尝试弥合可解释性的空缺。
总结
在劳伦斯伯克利国家实验室,我们已经展现了许多来自不同科学学科成功应用深度学习的案例,以及存在的挑战。公平地总结,深度学习的实践经验是非常令人鼓舞的。我们相信深度学习被很多科学学科探究并采纳只是一个时间的问题。我们应该注意到一些科学领域对深度学习网络的理论基础和性能提出的更严格的要求。我们鼓励深度学习研究人员来参与研究科学界丰富的和有趣的问题。
这篇博文是由劳伦斯伯克利国家实验室、加州大学伯克利分校、UCSF和蒙特利尔大学共同合作的结果。

Prabhat
Prabhat领导了劳伦斯伯克利国家实验室和能源部运营的国家能源研究科学计算中心(NERSC)的数据和分析服务团队。他的研究兴趣包括数据分析(统计学,机器学习)、数据管理(并行输入/输出、 数据格式、数据模型)、科学可视化和高性能计算。Prabhat在2001年从布朗大学获得了计算机科学学士学位,1999年从印度理工学院-德里获得了计算机科学与工程学士学位。他目前在美国加州大学伯克利分校的地球行星科学系攻读博士学位。





更多内容可以参考Strata北京2017的相关议题。